 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOV9D: Open-Vocabulary Category-Level 9D Object Pose and Size Estimation
Paper and Code
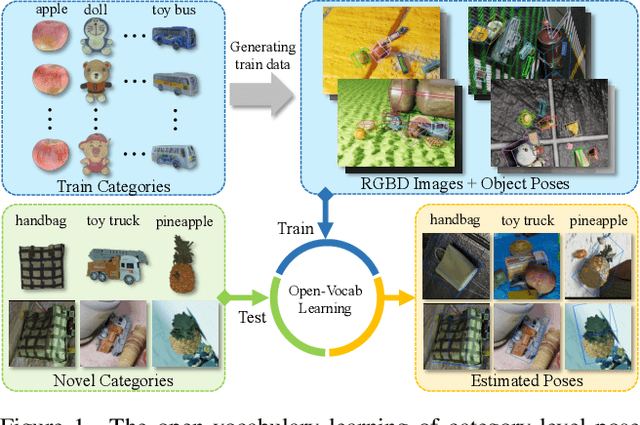
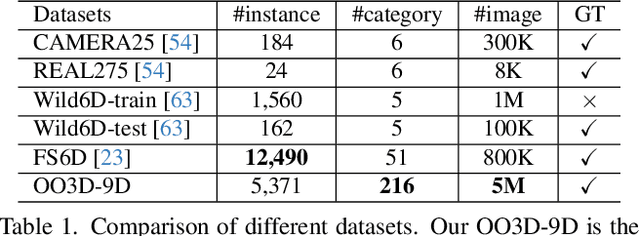

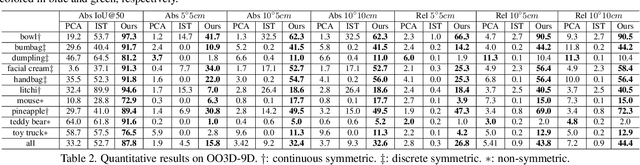
This paper studies a new open-set problem, the open-vocabulary category-level object pose and size estimation. Given human text descriptions of arbitrary novel object categories, the robot agent seeks to predict the position, orientation, and size of the target object in the observed scene image. To enable such generalizability, we first introduce OO3D-9D, a large-scale photorealistic dataset for this task. Derived from OmniObject3D, OO3D-9D is the largest and most diverse dataset in the field of category-level object pose and size estimation. It includes additional annotations for the symmetry axis of each category, which help resolve symmetric ambiguity. Apart from the large-scale dataset, we find another key to enabling such generalizability is leveraging the strong prior knowledge in pre-trained visual-language foundation models. We then propose a framework built on pre-trained DinoV2 and text-to-image stable diffusion models to infer the normalized object coordinate space (NOCS) maps of the target instances. This framework fully leverages the visual semantic prior from DinoV2 and the aligned visual and language knowledge within the text-to-image diffusion model, which enables generalization to various text descriptions of novel categories. Comprehensive quantitative and qualitative experiments demonstrate that the proposed open-vocabulary method, trained on our large-scale synthesized data, significantly outperforms the baseline and can effectively generalize to real-world images of unseen categories. The project page is at https://ov9d.github.io.