 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVImgNet2.0: A Larger-scale Dataset of Multi-view Images
Dec 02, 2024
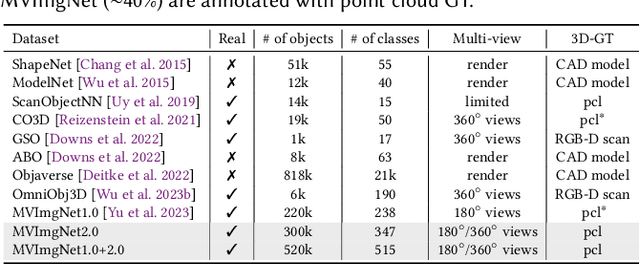

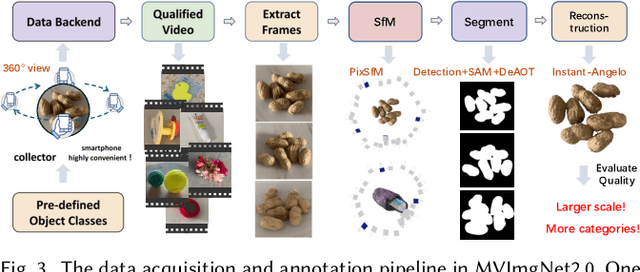
MVImgNet is a large-scale dataset that contains multi-view images of ~220k real-world objects in 238 classes. As a counterpart of ImageNet, it introduces 3D visual signals via multi-view shooting, making a soft bridge between 2D and 3D vision. This paper constructs the MVImgNet2.0 dataset that expands MVImgNet into a total of ~520k objects and 515 categories, which derives a 3D dataset with a larger scale that is more comparable to ones in the 2D domain. In addition to the expanded dataset scale and category range, MVImgNet2.0 is of a higher quality than MVImgNet owing to four new features: (i) most shoots capture 360-degree views of the objects, which can support the learning of object reconstruction with completeness; (ii) the segmentation manner is advanced to produce foreground object masks of higher accuracy; (iii) a more powerful structure-from-motion method is adopted to derive the camera pose for each frame of a lower estimation error; (iv) higher-quality dense point clouds are reconstructed via advanced methods for objects captured in 360-degree views, which can serve for downstream applications. Extensive experiments confirm the value of the proposed MVImgNet2.0 in boosting the performance of large 3D reconstruction models. MVImgNet2.0 will be public at luyues.github.io/mvimgnet2, including multi-view images of all 520k objects, the reconstructed high-quality point clouds, and data annotation codes, hoping to inspire the broader vision community.
* ACM Transactions on Graphics (TOG), SIGGRAPH Asia 2024
IPoD: Implicit Field Learning with Point Diffusion for Generalizable 3D Object Reconstruction from Single RGB-D Images
Mar 30, 2024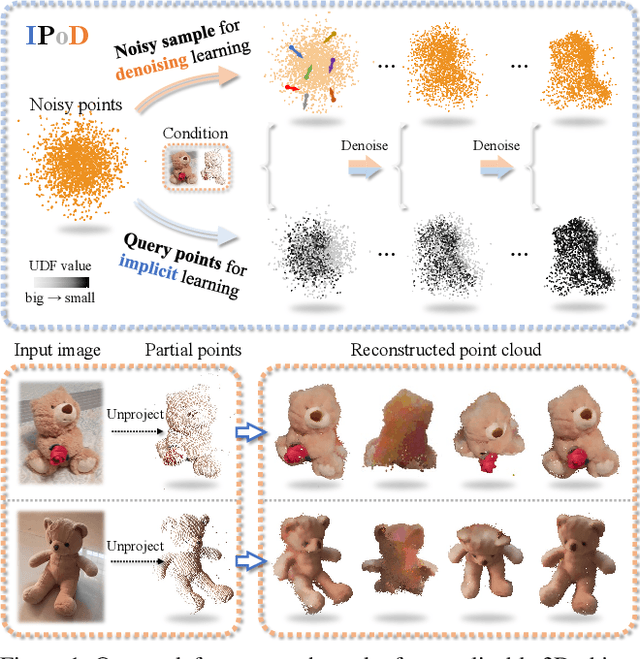
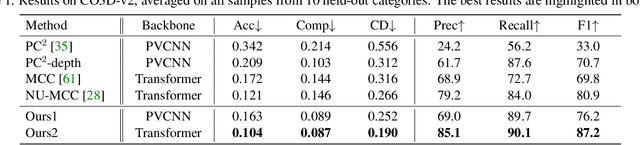
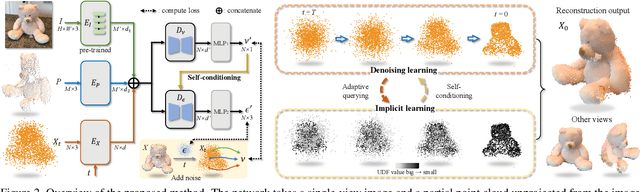
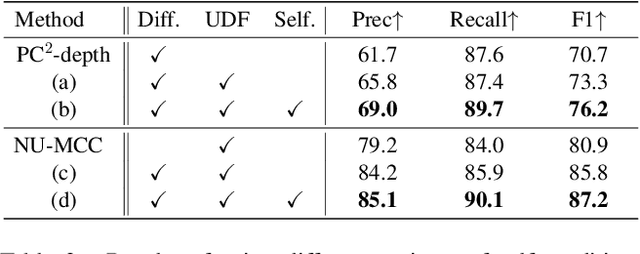
Generalizable 3D object reconstruction from single-view RGB-D images remains a challenging task, particularly with real-world data. Current state-of-the-art methods develop Transformer-based implicit field learning, necessitating an intensive learning paradigm that requires dense query-supervision uniformly sampled throughout the entire space. We propose a novel approach, IPoD, which harmonizes implicit field learning with point diffusion. This approach treats the query points for implicit field learning as a noisy point cloud for iterative denoising, allowing for their dynamic adaptation to the target object shape. Such adaptive query points harness diffusion learning's capability for coarse shape recovery and also enhances the implicit representation's ability to delineate finer details. Besides, an additional self-conditioning mechanism is designed to use implicit predictions as the guidance of diffusion learning, leading to a cooperative system. Experiments conducted on the CO3D-v2 dataset affirm the superiority of IPoD, achieving 7.8% improvement in F-score and 28.6% in Chamfer distance over existing methods. The generalizability of IPoD is also demonstrated on the MVImgNet dataset. Our project page is at https://yushuang-wu.github.io/IPoD.