 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
Apr 21, 2026Human video generation remains challenging due to the difficulty of jointly modeling human appearance, motion, and camera viewpoint under limited multi-view data. Existing methods often address these factors separately, resulting in limited controllability or reduced visual quality. We revisit this problem from an image-first perspective, where high-quality human appearance is learned via image generation and used as a prior for video synthesis, decoupling appearance modeling from temporal consistency. We propose a pose- and viewpoint-controllable pipeline that combines a pretrained image backbone with SMPL-X-based motion guidance, together with a training-free temporal refinement stage based on a pretrained video diffusion model. Our method produces high-quality, temporally consistent videos under diverse poses and viewpoints. We also release a canonical human dataset and an auxiliary model for compositional human image synthesis. Code and data are publicly available at https://github.com/Taited/ReImagine.
MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025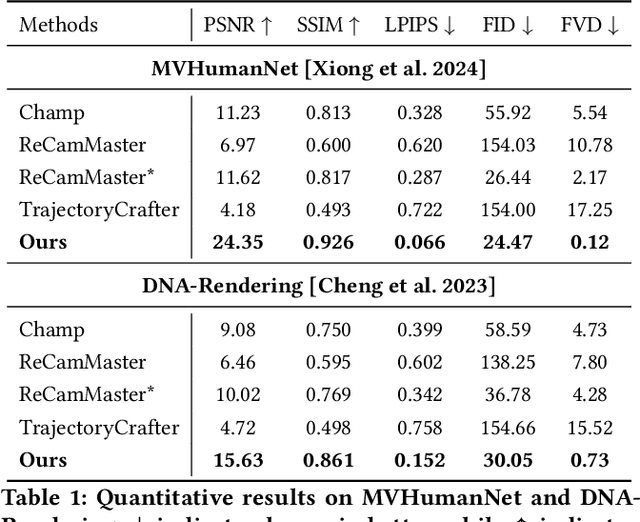

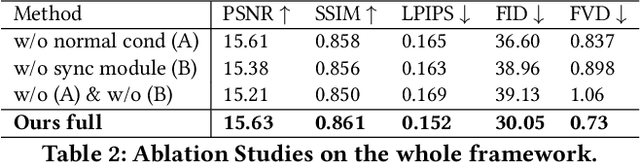
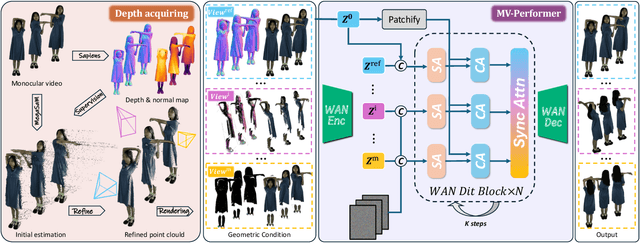
Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
Exploring Disentangled and Controllable Human Image Synthesis: From End-to-End to Stage-by-Stage
Mar 25, 2025



Achieving fine-grained controllability in human image synthesis is a long-standing challenge in computer vision. Existing methods primarily focus on either facial synthesis or near-frontal body generation, with limited ability to simultaneously control key factors such as viewpoint, pose, clothing, and identity in a disentangled manner. In this paper, we introduce a new disentangled and controllable human synthesis task, which explicitly separates and manipulates these four factors within a unified framework. We first develop an end-to-end generative model trained on MVHumanNet for factor disentanglement. However, the domain gap between MVHumanNet and in-the-wild data produce unsatisfacotry results, motivating the exploration of virtual try-on (VTON) dataset as a potential solution. Through experiments, we observe that simply incorporating the VTON dataset as additional data to train the end-to-end model degrades performance, primarily due to the inconsistency in data forms between the two datasets, which disrupts the disentanglement process. To better leverage both datasets, we propose a stage-by-stage framework that decomposes human image generation into three sequential steps: clothed A-pose generation, back-view synthesis, and pose and view control. This structured pipeline enables better dataset utilization at different stages, significantly improving controllability and generalization, especially for in-the-wild scenarios. Extensive experiments demonstrate that our stage-by-stage approach outperforms end-to-end models in both visual fidelity and disentanglement quality, offering a scalable solution for real-world tasks. Additional demos are available on the project page: https://taited.github.io/discohuman-project/.
MVImgNet2.0: A Larger-scale Dataset of Multi-view Images
Dec 02, 2024
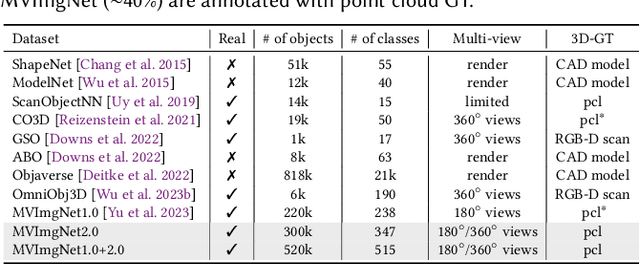

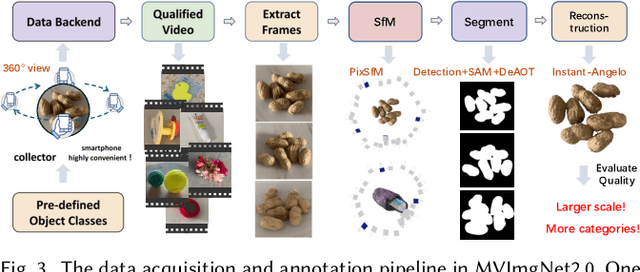
MVImgNet is a large-scale dataset that contains multi-view images of ~220k real-world objects in 238 classes. As a counterpart of ImageNet, it introduces 3D visual signals via multi-view shooting, making a soft bridge between 2D and 3D vision. This paper constructs the MVImgNet2.0 dataset that expands MVImgNet into a total of ~520k objects and 515 categories, which derives a 3D dataset with a larger scale that is more comparable to ones in the 2D domain. In addition to the expanded dataset scale and category range, MVImgNet2.0 is of a higher quality than MVImgNet owing to four new features: (i) most shoots capture 360-degree views of the objects, which can support the learning of object reconstruction with completeness; (ii) the segmentation manner is advanced to produce foreground object masks of higher accuracy; (iii) a more powerful structure-from-motion method is adopted to derive the camera pose for each frame of a lower estimation error; (iv) higher-quality dense point clouds are reconstructed via advanced methods for objects captured in 360-degree views, which can serve for downstream applications. Extensive experiments confirm the value of the proposed MVImgNet2.0 in boosting the performance of large 3D reconstruction models. MVImgNet2.0 will be public at luyues.github.io/mvimgnet2, including multi-view images of all 520k objects, the reconstructed high-quality point clouds, and data annotation codes, hoping to inspire the broader vision community.
* ACM Transactions on Graphics (TOG), SIGGRAPH Asia 2024
LLMCount: Enhancing Stationary mmWave Detection with Multimodal-LLM
Sep 24, 2024



Millimeter wave sensing provides people with the capability of sensing the surrounding crowds in a non-invasive and privacy-preserving manner, which holds huge application potential. However, detecting stationary crowds remains challenging due to several factors such as minimal movements (like breathing or casual fidgets), which can be easily treated as noise clusters during data collection and consequently filtered in the following processing procedures. Additionally, the uneven distribution of signal power due to signal power attenuation and interferences resulting from external reflectors or absorbers further complicates accurate detection. To address these challenges and enable stationary crowd detection across various application scenarios requiring specialized domain adaption, we introduce LLMCount, the first system to harness the capabilities of large-language models (LLMs) to enhance crowd detection performance. By exploiting the decision-making capability of LLM, we can successfully compensate the signal power to acquire a uniform distribution and thereby achieve a detection with higher accuracy. To assess the system's performance, comprehensive evaluations are conducted under diversified scenarios like hall, meeting room, and cinema. The evaluation results show that our proposed approach reaches high detection accuracy with lower overall latency compared with previous methods.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023
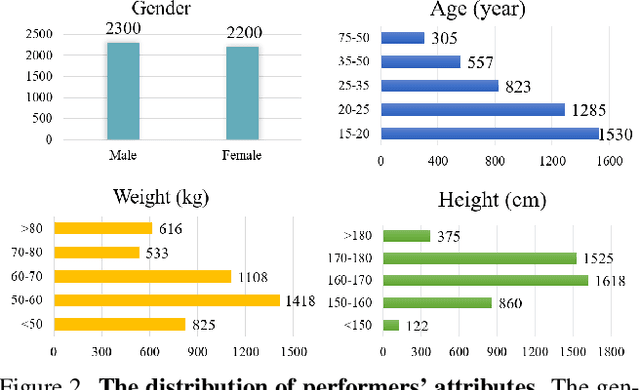
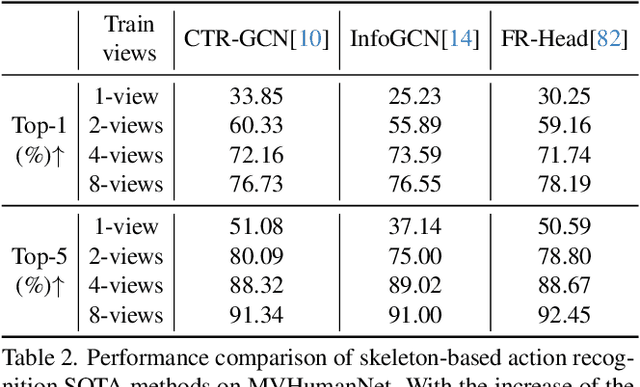

In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.