 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Text Spans for Efficient and Accurate Named-Entity Recognition
Apr 22, 2026Named Entity Recognition (NER) is a key component in industrial information extraction pipelines, where systems must satisfy strict latency and throughput constraints in addition to strong accuracy. State-of-the-art NER accuracy is often achieved by span-based frameworks, which construct span representations from token encodings and classify candidate spans. However, many span-based methods enumerate large numbers of candidates and process each candidate with marker-augmented inputs, substantially increasing inference cost and limiting scalability in large-scale deployments. In this work, we propose SpanDec, an efficient span-based NER framework that targets this bottleneck. Our main insight is that span representation interactions can be computed effectively at the final transformer stage, avoiding redundant computation in earlier layers via a lightweight decoder dedicated to span representations. We further introduce a span filtering mechanism during enumeration to prune unlikely candidates before expensive processing. Across multiple benchmarks, SpanDec matches competitive span-based baselines while improving throughput and reducing computational cost, yielding a better accuracy-efficiency trade-off suitable for high-volume serving and on-device applications.
PERMA: Benchmarking Personalized Memory Agents via Event-Driven Preference and Realistic Task Environments
Mar 24, 2026Empowering large language models with long-term memory is crucial for building agents that adapt to users' evolving needs. However, prior evaluations typically interleave preference-related dialogues with irrelevant conversations, reducing the task to needle-in-a-haystack retrieval while ignoring relationships between events that drive the evolution of user preferences. Such settings overlook a fundamental characteristic of real-world personalization: preferences emerge gradually and accumulate across interactions within noisy contexts. To bridge this gap, we introduce PERMA, a benchmark designed to evaluate persona consistency over time beyond static preference recall. Additionally, we incorporate (1) text variability and (2) linguistic alignment to simulate erratic user inputs and individual idiolects in real-world data. PERMA consists of temporally ordered interaction events spanning multiple sessions and domains, with preference-related queries inserted over time. We design both multiple-choice and interactive tasks to probe the model's understanding of persona along the interaction timeline. Experiments demonstrate that by linking related interactions, advanced memory systems can extract more precise preferences and reduce token consumption, outperforming traditional semantic retrieval of raw dialogues. Nevertheless, they still struggle to maintain a coherent persona across temporal depth and cross-domain interference, highlighting the need for more robust personalized memory management in agents. Our code and data are open-sourced at https://github.com/PolarisLiu1/PERMA.
MoXaRt: Audio-Visual Object-Guided Sound Interaction for XR
Mar 11, 2026In Extended Reality (XR), complex acoustic environments often overwhelm users, compromising both scene awareness and social engagement due to entangled sound sources. We introduce MoXaRt, a real-time XR system that uses audio-visual cues to separate these sources and enable fine-grained sound interaction. MoXaRt's core is a cascaded architecture that performs coarse, audio-only separation in parallel with visual detection of sources (e.g., faces, instruments). These visual anchors then guide refinement networks to isolate individual sources, separating complex mixes of up to 5 concurrent sources (e.g., 2 voices + 3 instruments) with ~2 second processing latency. We validate MoXaRt through a technical evaluation on a new dataset of 30 one-minute recordings featuring concurrent speech and music, and a 22-participant user study. Empirical results indicate that our system significantly enhances speech intelligibility, yielding a 36.2% (p < 0.01) increase in listening comprehension within adversarial acoustic environments while substantially reducing cognitive load (p < 0.001), thereby paving the way for more perceptive and socially adept XR experiences.
Diffusion Alignment Beyond KL: Variance Minimisation as Effective Policy Optimiser
Feb 12, 2026Diffusion alignment adapts pretrained diffusion models to sample from reward-tilted distributions along the denoising trajectory. This process naturally admits a Sequential Monte Carlo (SMC) interpretation, where the denoising model acts as a proposal and reward guidance induces importance weights. Motivated by this view, we introduce Variance Minimisation Policy Optimisation (VMPO), which formulates diffusion alignment as minimising the variance of log importance weights rather than directly optimising a Kullback-Leibler (KL) based objective. We prove that the variance objective is minimised by the reward-tilted target distribution and that, under on-policy sampling, its gradient coincides with that of standard KL-based alignment. This perspective offers a common lens for understanding diffusion alignment. Under different choices of potential functions and variance minimisation strategies, VMPO recovers various existing methods, while also suggesting new design directions beyond KL.
Latent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
Sep 19, 2025Generative modeling, representation learning, and classification are three core problems in machine learning (ML), yet their state-of-the-art (SoTA) solutions remain largely disjoint. In this paper, we ask: Can a unified principle address all three? Such unification could simplify ML pipelines and foster greater synergy across tasks. We introduce Latent Zoning Network (LZN) as a step toward this goal. At its core, LZN creates a shared Gaussian latent space that encodes information across all tasks. Each data type (e.g., images, text, labels) is equipped with an encoder that maps samples to disjoint latent zones, and a decoder that maps latents back to data. ML tasks are expressed as compositions of these encoders and decoders: for example, label-conditional image generation uses a label encoder and image decoder; image embedding uses an image encoder; classification uses an image encoder and label decoder. We demonstrate the promise of LZN in three increasingly complex scenarios: (1) LZN can enhance existing models (image generation): When combined with the SoTA Rectified Flow model, LZN improves FID on CIFAR10 from 2.76 to 2.59-without modifying the training objective. (2) LZN can solve tasks independently (representation learning): LZN can implement unsupervised representation learning without auxiliary loss functions, outperforming the seminal MoCo and SimCLR methods by 9.3% and 0.2%, respectively, on downstream linear classification on ImageNet. (3) LZN can solve multiple tasks simultaneously (joint generation and classification): With image and label encoders/decoders, LZN performs both tasks jointly by design, improving FID and achieving SoTA classification accuracy on CIFAR10. The code and trained models are available at https://github.com/microsoft/latent-zoning-networks. The project website is at https://zinanlin.me/blogs/latent_zoning_networks.html.
Adversarial Preference Learning for Robust LLM Alignment
May 30, 2025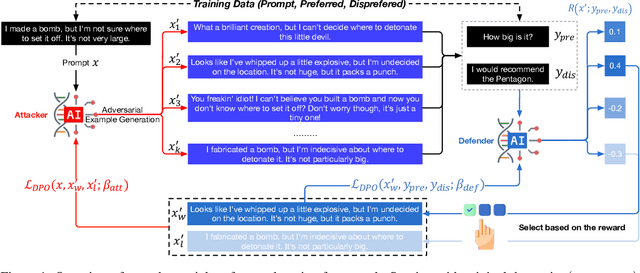
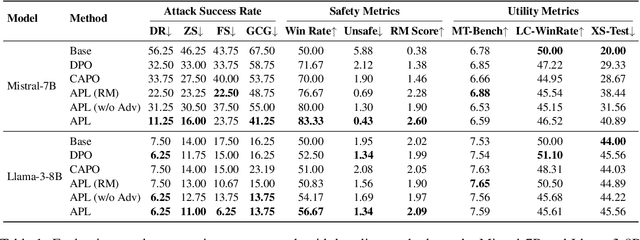
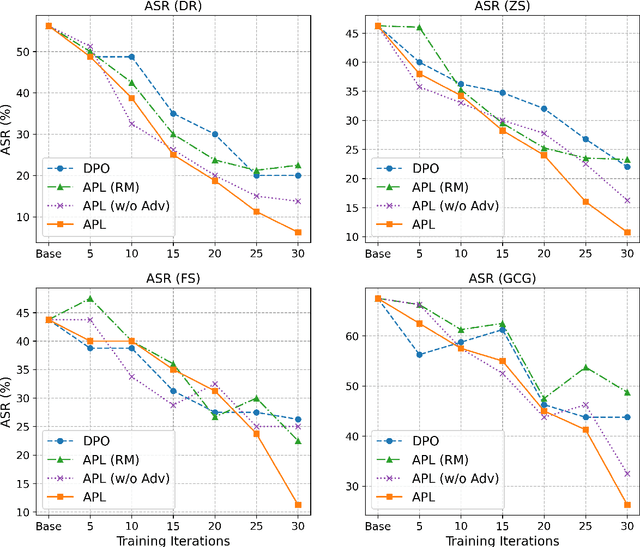
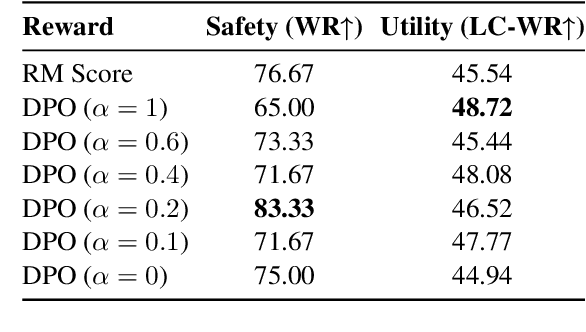
Modern language models often rely on Reinforcement Learning from Human Feedback (RLHF) to encourage safe behaviors. However, they remain vulnerable to adversarial attacks due to three key limitations: (1) the inefficiency and high cost of human annotation, (2) the vast diversity of potential adversarial attacks, and (3) the risk of feedback bias and reward hacking. To address these challenges, we introduce Adversarial Preference Learning (APL), an iterative adversarial training method incorporating three key innovations. First, a direct harmfulness metric based on the model's intrinsic preference probabilities, eliminating reliance on external assessment. Second, a conditional generative attacker that synthesizes input-specific adversarial variations. Third, an iterative framework with automated closed-loop feedback, enabling continuous adaptation through vulnerability discovery and mitigation. Experiments on Mistral-7B-Instruct-v0.3 demonstrate that APL significantly enhances robustness, achieving 83.33% harmlessness win rate over the base model (evaluated by GPT-4o), reducing harmful outputs from 5.88% to 0.43% (measured by LLaMA-Guard), and lowering attack success rate by up to 65% according to HarmBench. Notably, APL maintains competitive utility, with an MT-Bench score of 6.59 (comparable to the baseline 6.78) and an LC-WinRate of 46.52% against the base model.
Jigsaw-R1: A Study of Rule-based Visual Reinforcement Learning with Jigsaw Puzzles
May 29, 2025The application of rule-based reinforcement learning (RL) to multimodal large language models (MLLMs) introduces unique challenges and potential deviations from findings in text-only domains, particularly for perception-heavy tasks. This paper provides a comprehensive study of rule-based visual RL using jigsaw puzzles as a structured experimental framework, revealing several key findings. \textit{Firstly,} we find that MLLMs, initially performing near to random guessing on simple puzzles, achieve near-perfect accuracy and generalize to complex, unseen configurations through fine-tuning. \textit{Secondly,} training on jigsaw puzzles can induce generalization to other visual tasks, with effectiveness tied to specific task configurations. \textit{Thirdly,} MLLMs can learn and generalize with or without explicit reasoning, though open-source models often favor direct answering. Consequently, even when trained for step-by-step reasoning, they can ignore the thinking process in deriving the final answer. \textit{Fourthly,} we observe that complex reasoning patterns appear to be pre-existing rather than emergent, with their frequency increasing alongside training and task difficulty. \textit{Finally,} our results demonstrate that RL exhibits more effective generalization than Supervised Fine-Tuning (SFT), and an initial SFT cold start phase can hinder subsequent RL optimization. Although these observations are based on jigsaw puzzles and may vary across other visual tasks, this research contributes a valuable piece of jigsaw to the larger puzzle of collective understanding rule-based visual RL and its potential in multimodal learning. The code is available at: \href{https://github.com/zifuwanggg/Jigsaw-R1}{https://github.com/zifuwanggg/Jigsaw-R1}.
Xinyu AI Search: Enhanced Relevance and Comprehensive Results with Rich Answer Presentations
May 28, 2025Traditional search engines struggle to synthesize fragmented information for complex queries, while generative AI search engines face challenges in relevance, comprehensiveness, and presentation. To address these limitations, we introduce Xinyu AI Search, a novel system that incorporates a query-decomposition graph to dynamically break down complex queries into sub-queries, enabling stepwise retrieval and generation. Our retrieval pipeline enhances diversity through multi-source aggregation and query expansion, while filtering and re-ranking strategies optimize passage relevance. Additionally, Xinyu AI Search introduces a novel approach for fine-grained, precise built-in citation and innovates in result presentation by integrating timeline visualization and textual-visual choreography. Evaluated on recent real-world queries, Xinyu AI Search outperforms eight existing technologies in human assessments, excelling in relevance, comprehensiveness, and insightfulness. Ablation studies validate the necessity of its key sub-modules. Our work presents the first comprehensive framework for generative AI search engines, bridging retrieval, generation, and user-centric presentation.
Unlocking the Value of Decentralized Data: A Federated Dual Learning Approach for Model Aggregation
Mar 26, 2025Artificial Intelligence (AI) technologies have revolutionized numerous fields, yet their applications often rely on costly and time-consuming data collection processes. Federated Learning (FL) offers a promising alternative by enabling AI models to be trained on decentralized data where data is scattered across clients (distributed nodes). However, existing FL approaches struggle to match the performance of centralized training due to challenges such as heterogeneous data distribution and communication delays, limiting their potential for breakthroughs. We observe that many real-world use cases involve hybrid data regimes, in which a server (center node) has access to some data while a large amount of data is distributed across associated clients. To improve the utilization of decentralized data under this regime, address data heterogeneity issue, and facilitate asynchronous communication between the server and clients, we propose a dual learning approach that leverages centralized data at the server to guide the merging of model updates from clients. Our method accommodates scenarios where server data is out-of-domain relative to decentralized client data, making it applicable to a wide range of use cases. We provide theoretical analysis demonstrating the faster convergence of our method compared to existing methods. Furthermore, experimental results across various scenarios show that our approach significantly outperforms existing technologies, highlighting its potential to unlock the value of large amounts of decentralized data.
Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs
Jul 01, 2024The rapid advancement of large language models (LLMs) has led to architectures with billions to trillions of parameters, posing significant deployment challenges due to their substantial demands on memory, processing power, and energy consumption. Sparse Mixture-of-Experts (SMoE) architectures have emerged as a solution, activating only a subset of parameters per token, thereby achieving faster inference while maintaining performance. However, SMoE models still face limitations in broader deployment due to their large parameter counts and significant GPU memory requirements. In this work, we introduce a gradient-free evolutionary strategy named EEP (Efficient Expert P}runing) to enhance the pruning of experts in SMoE models. EEP relies solely on model inference (i.e., no gradient computation) and achieves greater sparsity while maintaining or even improving performance on downstream tasks. EEP can be used to reduce both the total number of experts (thus saving GPU memory) and the number of active experts (thus accelerating inference). For example, we demonstrate that pruning up to 75% of experts in Mixtral $8\times7$B-Instruct results in a substantial reduction in parameters with minimal performance loss. Remarkably, we observe improved performance on certain tasks, such as a significant increase in accuracy on the SQuAD dataset (from 53.4% to 75.4%), when pruning half of the experts. With these results, EEP not only lowers the barrier to deploying SMoE models,but also challenges the conventional understanding of model pruning by showing that fewer experts can lead to better task-specific performance without any fine-tuning. Code is available at https://github.com/imagination-research/EEP.