 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient 3D Full-Body Motion Generation from Sparse Tracking Inputs with Temporal Windows
May 03, 2025To have a seamless user experience on immersive AR/VR applications, the importance of efficient and effective Neural Network (NN) models is undeniable, since missing body parts that cannot be captured by limited sensors should be generated using these models for a complete 3D full-body reconstruction in virtual environment. However, the state-of-the-art NN-models are typically computational expensive and they leverage longer sequences of sparse tracking inputs to generate full-body movements by capturing temporal context. Inevitably, longer sequences increase the computation overhead and introduce noise in longer temporal dependencies that adversely affect the generation performance. In this paper, we propose a novel Multi-Layer Perceptron (MLP)-based method that enhances the overall performance while balancing the computational cost and memory overhead for efficient 3D full-body generation. Precisely, we introduce a NN-mechanism that divides the longer sequence of inputs into smaller temporal windows. Later, the current motion is merged with the information from these windows through latent representations to utilize the past context for the generation. Our experiments demonstrate that generation accuracy of our method with this NN-mechanism is significantly improved compared to the state-of-the-art methods while greatly reducing computational costs and memory overhead, making our method suitable for resource-constrained devices.
Unlocking the Value of Decentralized Data: A Federated Dual Learning Approach for Model Aggregation
Mar 26, 2025Artificial Intelligence (AI) technologies have revolutionized numerous fields, yet their applications often rely on costly and time-consuming data collection processes. Federated Learning (FL) offers a promising alternative by enabling AI models to be trained on decentralized data where data is scattered across clients (distributed nodes). However, existing FL approaches struggle to match the performance of centralized training due to challenges such as heterogeneous data distribution and communication delays, limiting their potential for breakthroughs. We observe that many real-world use cases involve hybrid data regimes, in which a server (center node) has access to some data while a large amount of data is distributed across associated clients. To improve the utilization of decentralized data under this regime, address data heterogeneity issue, and facilitate asynchronous communication between the server and clients, we propose a dual learning approach that leverages centralized data at the server to guide the merging of model updates from clients. Our method accommodates scenarios where server data is out-of-domain relative to decentralized client data, making it applicable to a wide range of use cases. We provide theoretical analysis demonstrating the faster convergence of our method compared to existing methods. Furthermore, experimental results across various scenarios show that our approach significantly outperforms existing technologies, highlighting its potential to unlock the value of large amounts of decentralized data.
Efficient and Accurate Scene Text Recognition with Cascaded-Transformers
Mar 24, 2025In recent years, vision transformers with text decoder have demonstrated remarkable performance on Scene Text Recognition (STR) due to their ability to capture long-range dependencies and contextual relationships with high learning capacity. However, the computational and memory demands of these models are significant, limiting their deployment in resource-constrained applications. To address this challenge, we propose an efficient and accurate STR system. Specifically, we focus on improving the efficiency of encoder models by introducing a cascaded-transformers structure. This structure progressively reduces the vision token size during the encoding step, effectively eliminating redundant tokens and reducing computational cost. Our experimental results confirm that our STR system achieves comparable performance to state-of-the-art baselines while substantially decreasing computational requirements. In particular, for large-models, the accuracy remains same, 92.77 to 92.68, while computational complexity is almost halved with our structure.
Accurate Scene Text Recognition with Efficient Model Scaling and Cloze Self-Distillation
Mar 20, 2025



Scaling architectures have been proven effective for improving Scene Text Recognition (STR), but the individual contribution of vision encoder and text decoder scaling remain under-explored. In this work, we present an in-depth empirical analysis and demonstrate that, contrary to previous observations, scaling the decoder yields significant performance gains, always exceeding those achieved by encoder scaling alone. We also identify label noise as a key challenge in STR, particularly in real-world data, which can limit the effectiveness of STR models. To address this, we propose Cloze Self-Distillation (CSD), a method that mitigates label noise by distilling a student model from context-aware soft predictions and pseudolabels generated by a teacher model. Additionally, we enhance the decoder architecture by introducing differential cross-attention for STR. Our methodology achieves state-of-the-art performance on 10 out of 11 benchmarks using only real data, while significantly reducing the parameter size and computational costs.
Binarized Weight Error Networks With a Transition Regularization Term
May 09, 2021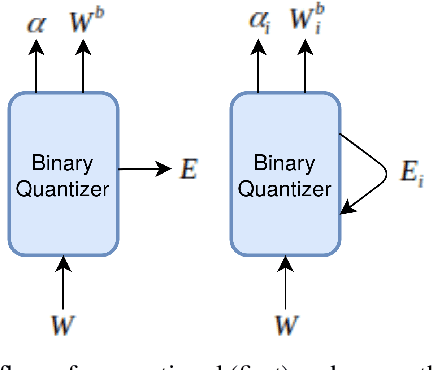



This paper proposes a novel binarized weight network (BT) for a resource-efficient neural structure. The proposed model estimates a binary representation of weights by taking into account the approximation error with an additional term. This model increases representation capacity and stability, particularly for shallow networks, while the computation load is theoretically reduced. In addition, a novel regularization term is introduced that is suitable for all threshold-based binary precision networks. This term penalizes the trainable parameters that are far from the thresholds at which binary transitions occur. This step promotes a swift modification for binary-precision responses at train time. The experimental results are carried out for two sets of tasks: visual classification and visual inverse problems. Benchmarks for Cifar10, SVHN, Fashion, ImageNet2012, Set5, Set14, Urban and BSD100 datasets show that our method outperforms all counterparts with binary precision.
Spectral Unmixing With Multinomial Mixture Kernel and Wasserstein Generative Adversarial Loss
Dec 12, 2020
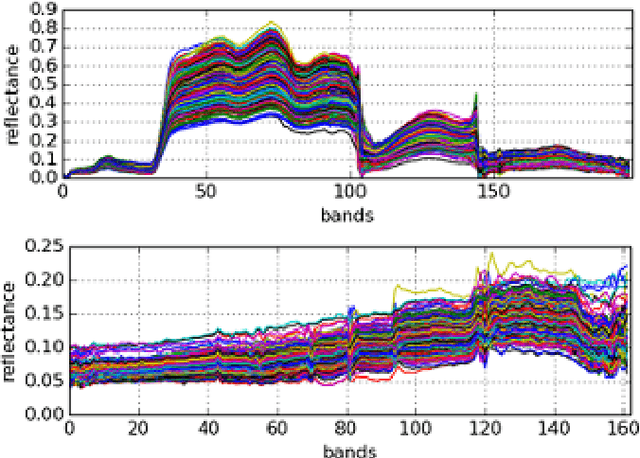


This study proposes a novel framework for spectral unmixing by using 1D convolution kernels and spectral uncertainty. High-level representations are computed from data, and they are further modeled with the Multinomial Mixture Model to estimate fractions under severe spectral uncertainty. Furthermore, a new trainable uncertainty term based on a nonlinear neural network model is introduced in the reconstruction step. All uncertainty models are optimized by Wasserstein Generative Adversarial Network (WGAN) to improve stability and capture uncertainty. Experiments are performed on both real and synthetic datasets. The results validate that the proposed method obtains state-of-the-art performance, especially for the real datasets compared to the baselines. Project page at: https://github.com/savasozkan/dscn.
Cross-Domain Segmentation with Adversarial Loss and Covariate Shift for Biomedical Imaging
Jun 08, 2020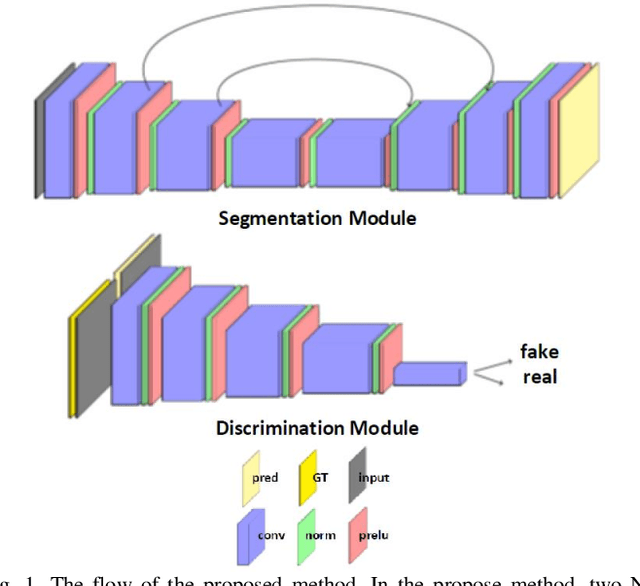
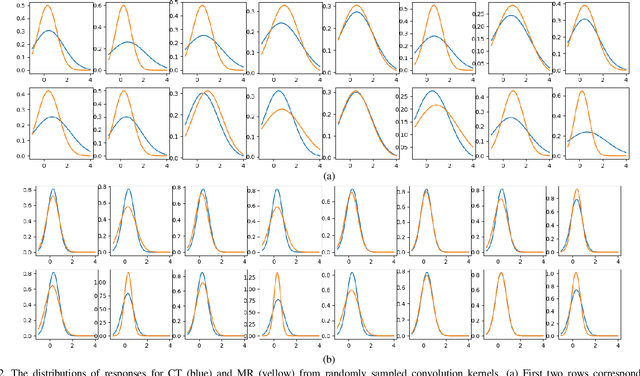
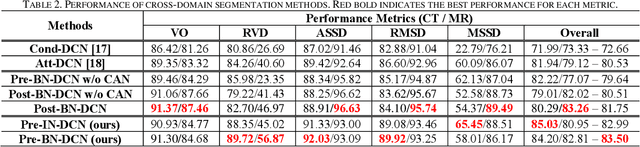
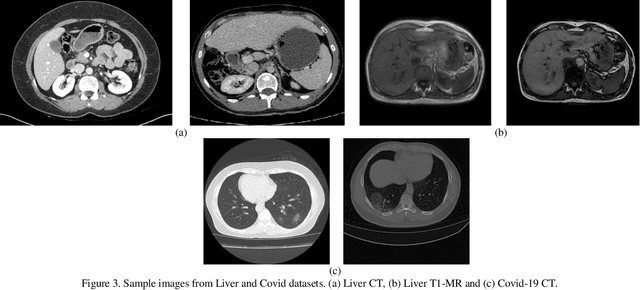
Despite the widespread use of deep learning methods for semantic segmentation of images that are acquired from a single source, clinicians often use multi-domain data for a detailed analysis. For instance, CT and MRI have advantages over each other in terms of imaging quality, artifacts, and output characteristics that lead to differential diagnosis. The capacity of current segmentation techniques is only allow to work for an individual domain due to their differences. However, the models that are capable of working on all modalities are essentially needed for a complete solution. Furthermore, robustness is drastically affected by the number of samples in the training step, especially for deep learning models. Hence, there is a necessity that all available data regardless of data domain should be used for reliable methods. For this purpose, this manuscript aims to implement a novel model that can learn robust representations from cross-domain data by encapsulating distinct and shared patterns from different modalities. Precisely, covariate shift property is retained with structural modification and adversarial loss where sparse and rich representations are obtained. Hence, a single parameter set is used to perform cross-domain segmentation task. The superiority of the proposed method is that no information related to modalities are provided in either training or inference phase. The tests on CT and MRI liver data acquired in routine clinical workflows show that the proposed model outperforms all other baseline with a large margin. Experiments are also conducted on Covid-19 dataset that it consists of CT data where significant intra-class visual differences are observed. Similarly, the proposed method achieves the best performance.
Automatic Liver Segmentation with Adversarial Loss and Convolutional Neural Network
Nov 28, 2018


Automatic segmentation of medical images is among most demanded works in the medical information field since it saves time of the experts in the field and avoids human error factors. In this work, a method based on Conditional Adversarial Networks and Fully Convolutional Networks is proposed for the automatic segmentation of the liver MRIs. The proposed method, without any post-processing, is achieved the second place in the SIU Liver Segmentation Challenge 2018, data of which is provided by Dokuz Eyl\"ul University. In this paper, some improvements for the post-processing step are also proposed and it is shown that with these additions, the method outperforms other baseline methods.
Improved Deep Spectral Convolution Network For Hyperspectral Unmixing With Multinomial Mixture Kernel and Endmember Uncertainty
Aug 03, 2018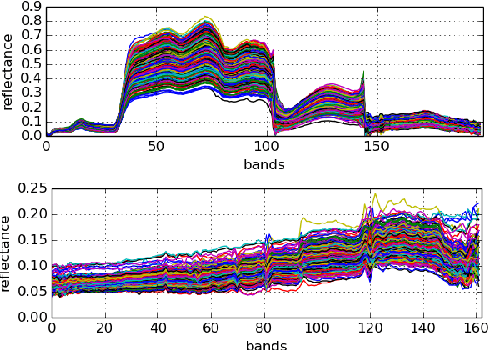

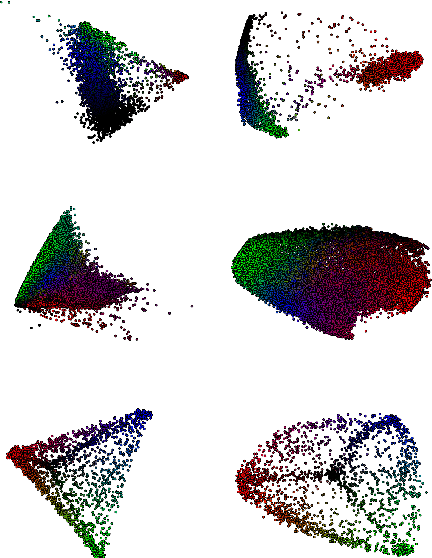
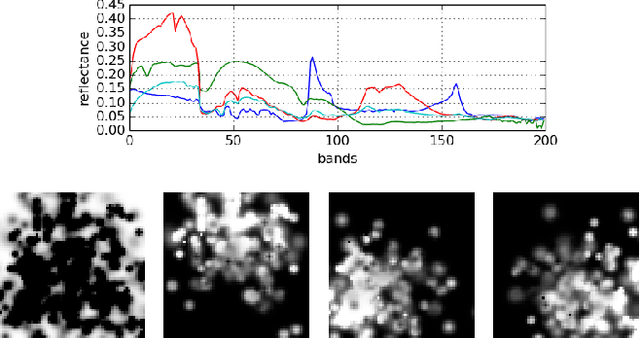
In this study, we propose a novel framework for hyperspectral unmixing by using a modular neural network structure while addressing the endmember uncertainty in our formulation. We present critical contributions throughout the manuscript: First, to improve the separability for hyperspectral data, we modify deep spectral convolution networks (DSCNs) that lead to more stable and accurate results. Second, we introduce a multinomial mixture kernel with a neural network (NN) which mimics the Gaussian Mixture Model (GMM) to estimate the abundances per-pixel by using the low-dimension representations obtained from the improved DSCN. Moreover, as formulated in the spectral variability assumption, a NN module is incorporated to capture the uncertainty term. Third, to optimize the coefficients of the multinomial model and the uncertainty term, Wasserstein GAN is exploited in particular since it has several theoretical benefits over the expectation maximization. Fourth, all neural network modules are formulated as an end-to-end hyperspectral unmixing pipeline that can be optimized with backpropagation by using a stochastic gradient-based solver. Experiments are performed on real and synthetic datasets. The results validate that the proposed method obtains state-of-the-art hyperspectral unmixing performance particularly on the real datasets compared to the baseline techniques.
Late Fusion of Local Indexing and Deep Feature Scores for Fast Image-to-Video Search on Large-Scale Databases
Aug 03, 2018
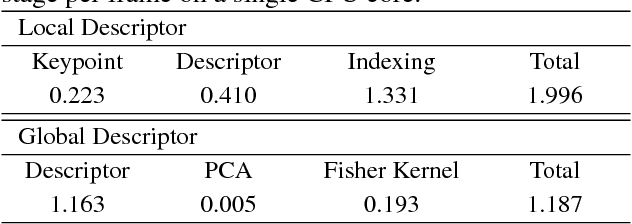

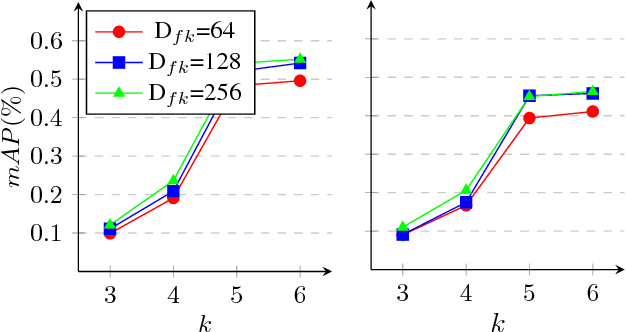
Low cost visual representation and fast query-by-example content search are two challenging objectives which should be supplied for web-scale visual retrieval task on moderate hardwares. In this paper, we introduce a fast yet robust method that ensures these two objectives by obtaining the state-of-the-art results for the image-to-video search scenario. For this purpose, we present critical improvements to the commonly used indexing and visual representation techniques by promoting faster, better and modest retrieval performance. Also, we boost the effectiveness of the method for visual distortions by exploiting the individual decision scores of local and global descriptors in the query time. By this way, local content descriptors effectively depict copy/duplicate scenes with large geometric deformations, while global descriptors are more practical for the near-duplicate and semantic search. Experiments are conducted on the large-scale Stanford I2V dataset. The experimental results show that the method is effective in terms of complexity and query processing time for large-scale visual retrieval scenarios, even if local and global representations are used together. Moreover, the proposed method is quite accurate and obtains state-of-the art performance based on the mAP score on the dataset. Lastly, we report additional mAP scores after updating the ground annotations obtained by the retrieval results of the proposed method which demonstrates the actual performance more clearly.