 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinarized Weight Error Networks With a Transition Regularization Term
May 09, 2021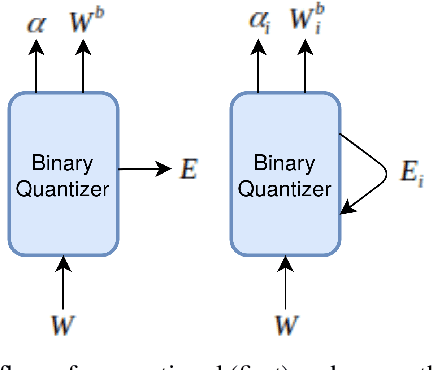



This paper proposes a novel binarized weight network (BT) for a resource-efficient neural structure. The proposed model estimates a binary representation of weights by taking into account the approximation error with an additional term. This model increases representation capacity and stability, particularly for shallow networks, while the computation load is theoretically reduced. In addition, a novel regularization term is introduced that is suitable for all threshold-based binary precision networks. This term penalizes the trainable parameters that are far from the thresholds at which binary transitions occur. This step promotes a swift modification for binary-precision responses at train time. The experimental results are carried out for two sets of tasks: visual classification and visual inverse problems. Benchmarks for Cifar10, SVHN, Fashion, ImageNet2012, Set5, Set14, Urban and BSD100 datasets show that our method outperforms all counterparts with binary precision.
Spectral Unmixing With Multinomial Mixture Kernel and Wasserstein Generative Adversarial Loss
Dec 12, 2020
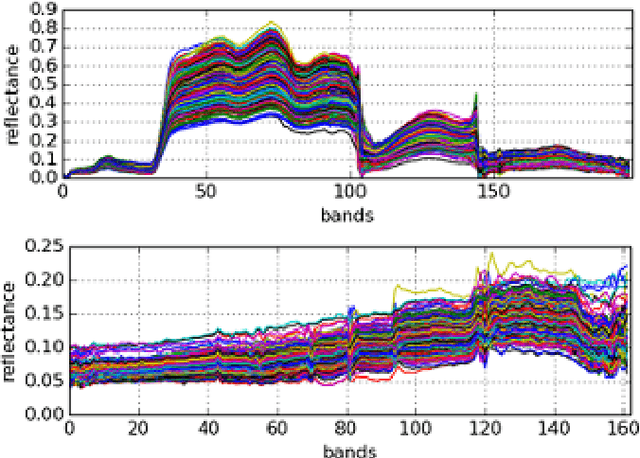


This study proposes a novel framework for spectral unmixing by using 1D convolution kernels and spectral uncertainty. High-level representations are computed from data, and they are further modeled with the Multinomial Mixture Model to estimate fractions under severe spectral uncertainty. Furthermore, a new trainable uncertainty term based on a nonlinear neural network model is introduced in the reconstruction step. All uncertainty models are optimized by Wasserstein Generative Adversarial Network (WGAN) to improve stability and capture uncertainty. Experiments are performed on both real and synthetic datasets. The results validate that the proposed method obtains state-of-the-art performance, especially for the real datasets compared to the baselines. Project page at: https://github.com/savasozkan/dscn.
Cross-Domain Segmentation with Adversarial Loss and Covariate Shift for Biomedical Imaging
Jun 08, 2020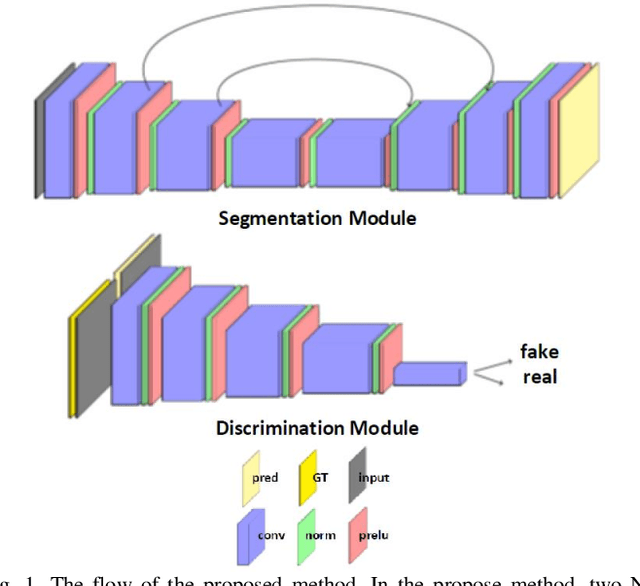
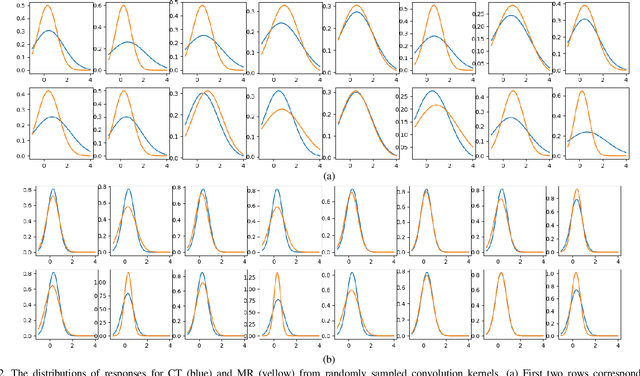
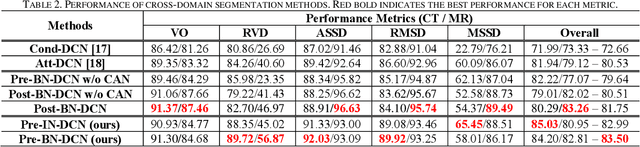
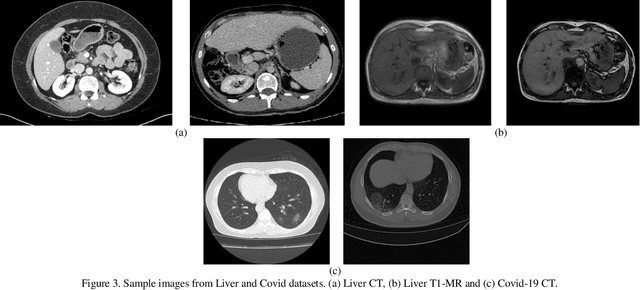
Despite the widespread use of deep learning methods for semantic segmentation of images that are acquired from a single source, clinicians often use multi-domain data for a detailed analysis. For instance, CT and MRI have advantages over each other in terms of imaging quality, artifacts, and output characteristics that lead to differential diagnosis. The capacity of current segmentation techniques is only allow to work for an individual domain due to their differences. However, the models that are capable of working on all modalities are essentially needed for a complete solution. Furthermore, robustness is drastically affected by the number of samples in the training step, especially for deep learning models. Hence, there is a necessity that all available data regardless of data domain should be used for reliable methods. For this purpose, this manuscript aims to implement a novel model that can learn robust representations from cross-domain data by encapsulating distinct and shared patterns from different modalities. Precisely, covariate shift property is retained with structural modification and adversarial loss where sparse and rich representations are obtained. Hence, a single parameter set is used to perform cross-domain segmentation task. The superiority of the proposed method is that no information related to modalities are provided in either training or inference phase. The tests on CT and MRI liver data acquired in routine clinical workflows show that the proposed model outperforms all other baseline with a large margin. Experiments are also conducted on Covid-19 dataset that it consists of CT data where significant intra-class visual differences are observed. Similarly, the proposed method achieves the best performance.
Automatic Liver Segmentation with Adversarial Loss and Convolutional Neural Network
Nov 28, 2018


Automatic segmentation of medical images is among most demanded works in the medical information field since it saves time of the experts in the field and avoids human error factors. In this work, a method based on Conditional Adversarial Networks and Fully Convolutional Networks is proposed for the automatic segmentation of the liver MRIs. The proposed method, without any post-processing, is achieved the second place in the SIU Liver Segmentation Challenge 2018, data of which is provided by Dokuz Eyl\"ul University. In this paper, some improvements for the post-processing step are also proposed and it is shown that with these additions, the method outperforms other baseline methods.
Convolutional Neural Networks Analyzed via Inverse Problem Theory and Sparse Representations
Oct 23, 2018


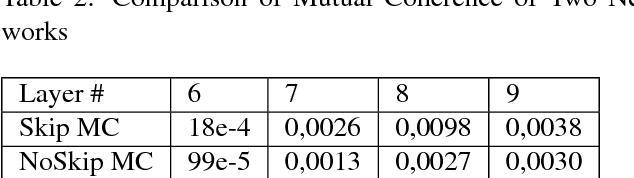
Inverse problems in imaging such as denoising, deblurring, superresolution (SR) have been addressed for many decades. In recent years, convolutional neural networks (CNNs) have been widely used for many inverse problem areas. Although their indisputable success, CNNs are not mathematically validated as to how and what they learn. In this paper, we prove that during training, CNN elements solve for inverse problems which are optimum solutions stored as CNN neuron filters. We discuss the necessity of mutual coherence between CNN layer elements in order for a network to converge to the optimum solution. We prove that required mutual coherence can be provided by the usage of residual learning and skip connections. We have set rules over training sets and depth of networks for better convergence, i.e. performance.
Improved Deep Spectral Convolution Network For Hyperspectral Unmixing With Multinomial Mixture Kernel and Endmember Uncertainty
Aug 03, 2018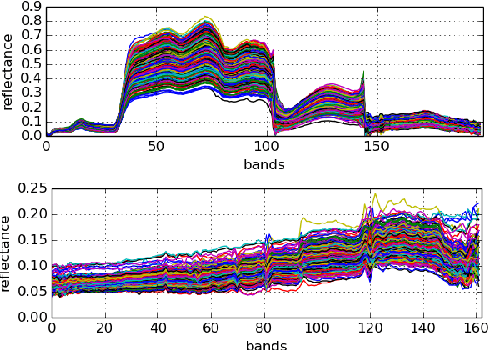

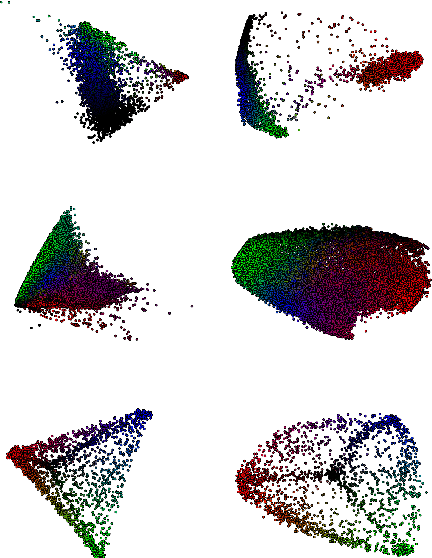
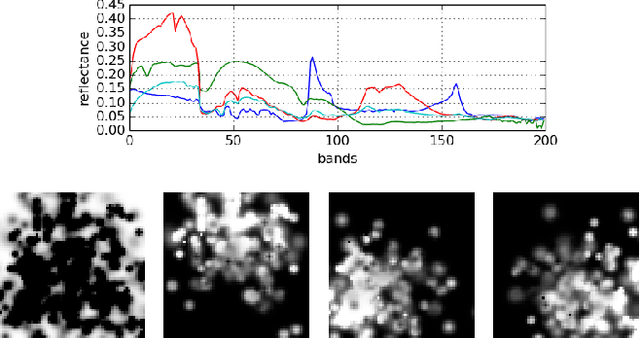
In this study, we propose a novel framework for hyperspectral unmixing by using a modular neural network structure while addressing the endmember uncertainty in our formulation. We present critical contributions throughout the manuscript: First, to improve the separability for hyperspectral data, we modify deep spectral convolution networks (DSCNs) that lead to more stable and accurate results. Second, we introduce a multinomial mixture kernel with a neural network (NN) which mimics the Gaussian Mixture Model (GMM) to estimate the abundances per-pixel by using the low-dimension representations obtained from the improved DSCN. Moreover, as formulated in the spectral variability assumption, a NN module is incorporated to capture the uncertainty term. Third, to optimize the coefficients of the multinomial model and the uncertainty term, Wasserstein GAN is exploited in particular since it has several theoretical benefits over the expectation maximization. Fourth, all neural network modules are formulated as an end-to-end hyperspectral unmixing pipeline that can be optimized with backpropagation by using a stochastic gradient-based solver. Experiments are performed on real and synthetic datasets. The results validate that the proposed method obtains state-of-the-art hyperspectral unmixing performance particularly on the real datasets compared to the baseline techniques.
Late Fusion of Local Indexing and Deep Feature Scores for Fast Image-to-Video Search on Large-Scale Databases
Aug 03, 2018
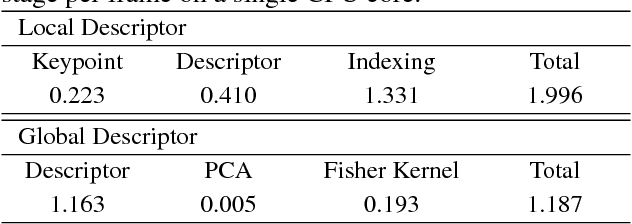

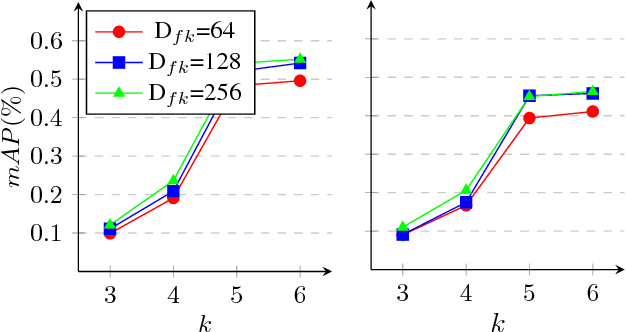
Low cost visual representation and fast query-by-example content search are two challenging objectives which should be supplied for web-scale visual retrieval task on moderate hardwares. In this paper, we introduce a fast yet robust method that ensures these two objectives by obtaining the state-of-the-art results for the image-to-video search scenario. For this purpose, we present critical improvements to the commonly used indexing and visual representation techniques by promoting faster, better and modest retrieval performance. Also, we boost the effectiveness of the method for visual distortions by exploiting the individual decision scores of local and global descriptors in the query time. By this way, local content descriptors effectively depict copy/duplicate scenes with large geometric deformations, while global descriptors are more practical for the near-duplicate and semantic search. Experiments are conducted on the large-scale Stanford I2V dataset. The experimental results show that the method is effective in terms of complexity and query processing time for large-scale visual retrieval scenarios, even if local and global representations are used together. Moreover, the proposed method is quite accurate and obtains state-of-the art performance based on the mAP score on the dataset. Lastly, we report additional mAP scores after updating the ground annotations obtained by the retrieval results of the proposed method which demonstrates the actual performance more clearly.
EndNet: Sparse AutoEncoder Network for Endmember Extraction and Hyperspectral Unmixing
Jul 16, 2018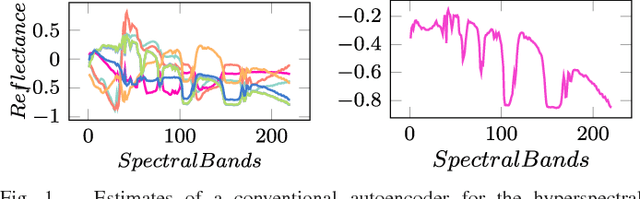



Data acquired from multi-channel sensors is a highly valuable asset to interpret the environment for a variety of remote sensing applications. However, low spatial resolution is a critical limitation for previous sensors and the constituent materials of a scene can be mixed in different fractions due to their spatial interactions. Spectral unmixing is a technique that allows us to obtain the material spectral signatures and their fractions from hyperspectral data. In this paper, we propose a novel endmember extraction and hyperspectral unmixing scheme, so called \textit{EndNet}, that is based on a two-staged autoencoder network. This well-known structure is completely enhanced and restructured by introducing additional layers and a projection metric (i.e., spectral angle distance (SAD) instead of inner product) to achieve an optimum solution. Moreover, we present a novel loss function that is composed of a Kullback-Leibler divergence term with SAD similarity and additional penalty terms to improve the sparsity of the estimates. These modifications enable us to set the common properties of endmembers such as non-linearity and sparsity for autoencoder networks. Lastly, due to the stochastic-gradient based approach, the method is scalable for large-scale data and it can be accelerated on Graphical Processing Units (GPUs). To demonstrate the superiority of our proposed method, we conduct extensive experiments on several well-known datasets. The results confirm that the proposed method considerably improves the performance compared to the state-of-the-art techniques in literature.
Deep Spectral Convolution Network for HyperSpectral Unmixing
Jun 22, 2018

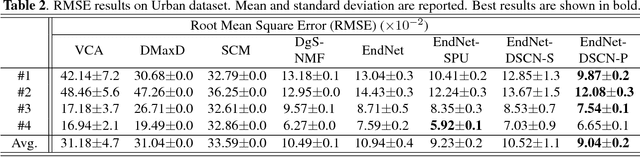
In this paper, we propose a novel hyperspectral unmixing technique based on deep spectral convolution networks (DSCN). Particularly, three important contributions are presented throughout this paper. First, fully-connected linear operation is replaced with spectral convolutions to extract local spectral characteristics from hyperspectral signatures with a deeper network architecture. Second, instead of batch normalization, we propose a spectral normalization layer which improves the selectivity of filters by normalizing their spectral responses. Third, we introduce two fusion configurations that produce ideal abundance maps by using the abstract representations computed from previous layers. In experiments, we use two real datasets to evaluate the performance of our method with other baseline techniques. The experimental results validate that the proposed method outperforms baselines based on Root Mean Square Error (RMSE).
Relaxed Spatio-Temporal Deep Feature Aggregation for Real-Fake Expression Prediction
Aug 24, 2017
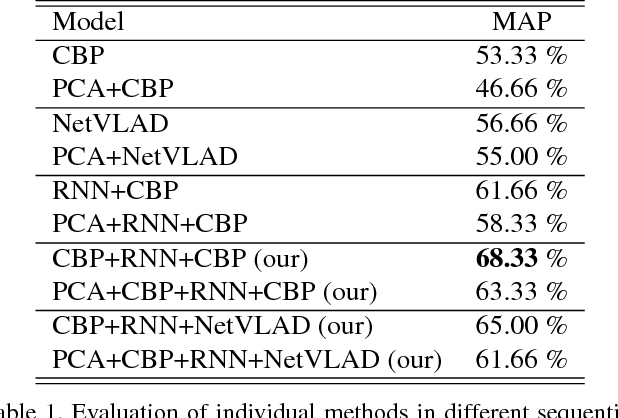
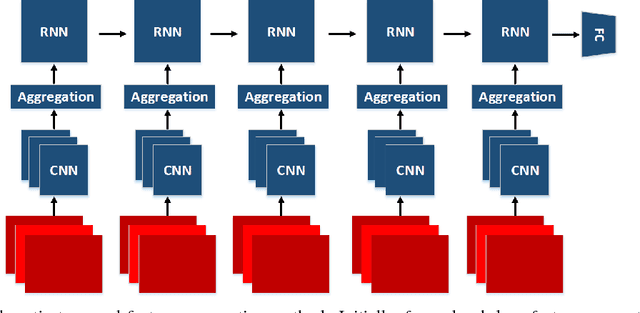

Frame-level visual features are generally aggregated in time with the techniques such as LSTM, Fisher Vectors, NetVLAD etc. to produce a robust video-level representation. We here introduce a learnable aggregation technique whose primary objective is to retain short-time temporal structure between frame-level features and their spatial interdependencies in the representation. Also, it can be easily adapted to the cases where there have very scarce training samples. We evaluate the method on a real-fake expression prediction dataset to demonstrate its superiority. Our method obtains 65% score on the test dataset in the official MAP evaluation and there is only one misclassified decision with the best reported result in the Chalearn Challenge (i.e. 66:7%) . Lastly, we believe that this method can be extended to different problems such as action/event recognition in future.