 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Photometric Stereo Revisited
Oct 14, 2022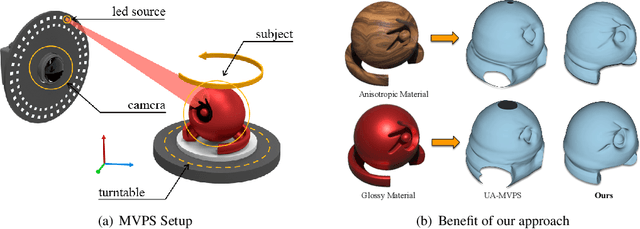

Multi-view photometric stereo (MVPS) is a preferred method for detailed and precise 3D acquisition of an object from images. Although popular methods for MVPS can provide outstanding results, they are often complex to execute and limited to isotropic material objects. To address such limitations, we present a simple, practical approach to MVPS, which works well for isotropic as well as other object material types such as anisotropic and glossy. The proposed approach in this paper exploits the benefit of uncertainty modeling in a deep neural network for a reliable fusion of photometric stereo (PS) and multi-view stereo (MVS) network predictions. Yet, contrary to the recently proposed state-of-the-art, we introduce neural volume rendering methodology for a trustworthy fusion of MVS and PS measurements. The advantage of introducing neural volume rendering is that it helps in the reliable modeling of objects with diverse material types, where existing MVS methods, PS methods, or both may fail. Furthermore, it allows us to work on neural 3D shape representation, which has recently shown outstanding results for many geometric processing tasks. Our suggested new loss function aims to fits the zero level set of the implicit neural function using the most certain MVS and PS network predictions coupled with weighted neural volume rendering cost. The proposed approach shows state-of-the-art results when tested extensively on several benchmark datasets.
Uncertainty-Aware Deep Multi-View Photometric Stereo
Mar 28, 2022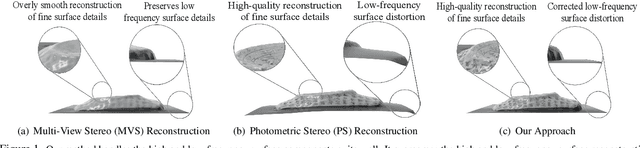

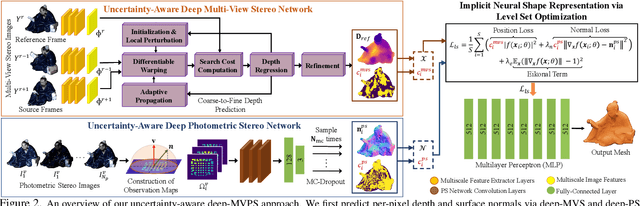

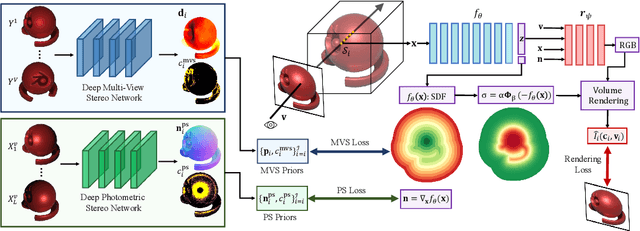
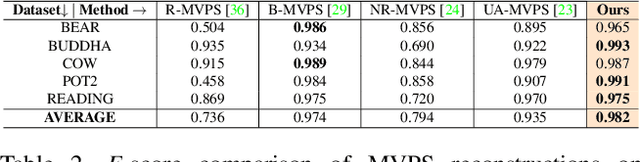
This paper presents a simple and effective solution to the longstanding classical multi-view photometric stereo (MVPS) problem. It is well-known that photometric stereo (PS) is excellent at recovering high-frequency surface details, whereas multi-view stereo (MVS) can help remove the low-frequency distortion due to PS and retain the global geometry of the shape. This paper proposes an approach that can effectively utilize such complementary strengths of PS and MVS. Our key idea is to combine them suitably while considering the per-pixel uncertainty of their estimates. To this end, we estimate per-pixel surface normals and depth using an uncertainty-aware deep-PS network and deep-MVS network, respectively. Uncertainty modeling helps select reliable surface normal and depth estimates at each pixel which then act as a true representative of the dense surface geometry. At each pixel, our approach either selects or discards deep-PS and deep-MVS network prediction depending on the prediction uncertainty measure. For dense, detailed, and precise inference of the object's surface profile, we propose to learn the implicit neural shape representation via a multilayer perceptron (MLP). Our approach encourages the MLP to converge to a natural zero-level set surface using the confident prediction from deep-PS and deep-MVS networks, providing superior dense surface reconstruction. Extensive experiments on the DiLiGenT-MV benchmark dataset show that our method provides high-quality shape recovery with a much lower memory footprint while outperforming almost all of the existing approaches.
Neural Architecture Search for Efficient Uncalibrated Deep Photometric Stereo
Oct 11, 2021



We present an automated machine learning approach for uncalibrated photometric stereo (PS). Our work aims at discovering lightweight and computationally efficient PS neural networks with excellent surface normal accuracy. Unlike previous uncalibrated deep PS networks, which are handcrafted and carefully tuned, we leverage differentiable neural architecture search (NAS) strategy to find uncalibrated PS architecture automatically. We begin by defining a discrete search space for a light calibration network and a normal estimation network, respectively. We then perform a continuous relaxation of this search space and present a gradient-based optimization strategy to find an efficient light calibration and normal estimation network. Directly applying the NAS methodology to uncalibrated PS is not straightforward as certain task-specific constraints must be satisfied, which we impose explicitly. Moreover, we search for and train the two networks separately to account for the Generalized Bas-Relief (GBR) ambiguity. Extensive experiments on the DiLiGenT dataset show that the automatically searched neural architectures performance compares favorably with the state-of-the-art uncalibrated PS methods while having a lower memory footprint.
Neural Radiance Fields Approach to Deep Multi-View Photometric Stereo
Oct 11, 2021

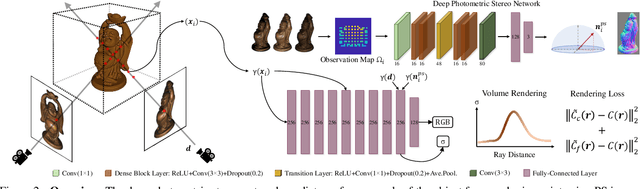

We present a modern solution to the multi-view photometric stereo problem (MVPS). Our work suitably exploits the image formation model in a MVPS experimental setup to recover the dense 3D reconstruction of an object from images. We procure the surface orientation using a photometric stereo (PS) image formation model and blend it with a multi-view neural radiance field representation to recover the object's surface geometry. Contrary to the previous multi-staged framework to MVPS, where the position, iso-depth contours, or orientation measurements are estimated independently and then fused later, our method is simple to implement and realize. Our method performs neural rendering of multi-view images while utilizing surface normals estimated by a deep photometric stereo network. We render the MVPS images by considering the object's surface normals for each 3D sample point along the viewing direction rather than explicitly using the density gradient in the volume space via 3D occupancy information. We optimize the proposed neural radiance field representation for the MVPS setup efficiently using a fully connected deep network to recover the 3D geometry of an object. Extensive evaluation on the DiLiGenT-MV benchmark dataset shows that our method performs better than the approaches that perform only PS or only multi-view stereo (MVS) and provides comparable results against the state-of-the-art multi-stage fusion methods.
Uncalibrated Neural Inverse Rendering for Photometric Stereo of General Surfaces
Dec 12, 2020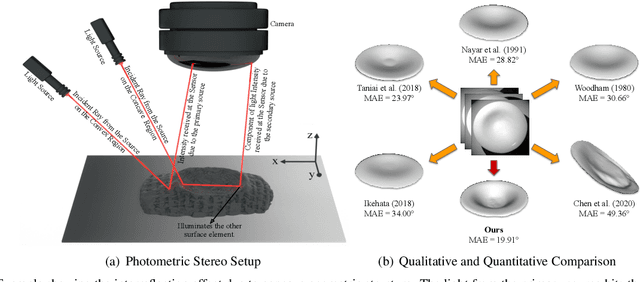
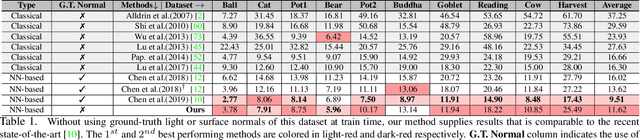
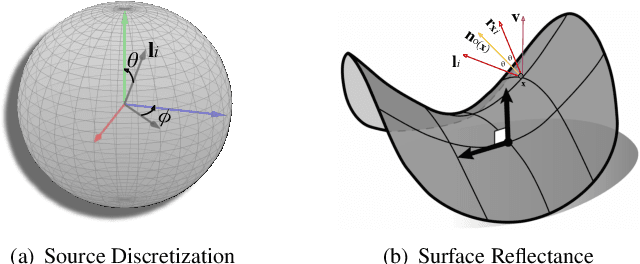

This paper presents an uncalibrated deep neural network framework for the photometric stereo problem. For training models to solve the problem, existing neural network-based methods either require exact light directions or ground-truth surface normals of the object or both. However, in practice, it is challenging to procure both of this information precisely, which restricts the broader adoption of photometric stereo algorithms for vision application. To bypass this difficulty, we propose an uncalibrated neural inverse rendering approach to this problem. Our method first estimates the light directions from the input images and then optimizes an image reconstruction loss to calculate the surface normals, bidirectional reflectance distribution function value, and depth. Additionally, our formulation explicitly models the concave and convex parts of a complex surface to consider the effects of interreflections in the image formation process. Extensive evaluation of the proposed method on the challenging subjects generally shows comparable or better results than the supervised and classical approaches.
Self-Supervised 2D Image to 3D Shape Translation with Disentangled Representations
Mar 22, 2020


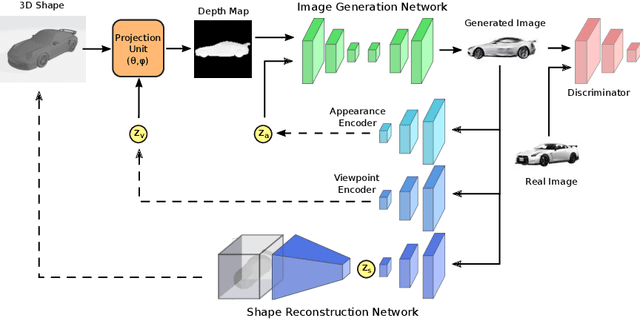
We present a framework to translate between 2D image views and 3D object shapes. Recent progress in deep learning enabled us to learn structure-aware representations from a scene. However, the existing literature assumes that pairs of images and 3D shapes are available for training in full supervision. In this paper, we propose SIST, a Self-supervised Image to Shape Translation framework that fulfills three tasks: (i) reconstructing the 3D shape from a single image; (ii) learning disentangled representations for shape, appearance and viewpoint; and (iii) generating a realistic RGB image from these independent factors. In contrast to the existing approaches, our method does not require image-shape pairs for training. Instead, it uses unpaired image and shape datasets from the same object class and jointly trains image generator and shape reconstruction networks. Our translation method achieves promising results, comparable in quantitative and qualitative terms to the state-of-the-art achieved by fully-supervised methods.
Towards Spectral Estimation from a Single RGB Image in the Wild
Dec 03, 2018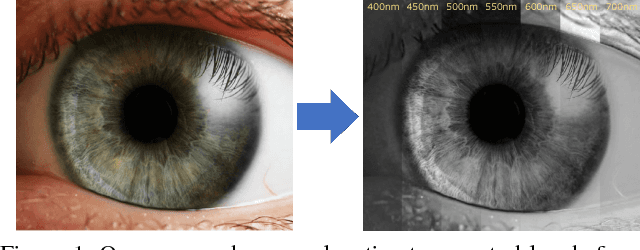
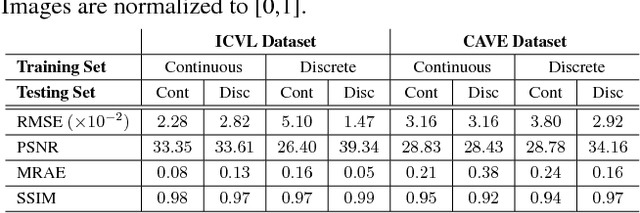
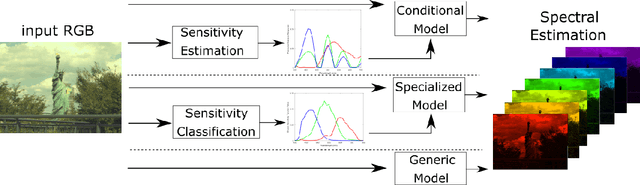

In contrast to the current literature, we address the problem of estimating the spectrum from a single common trichromatic RGB image obtained under unconstrained settings (e.g. unknown camera parameters, unknown scene radiance, unknown scene contents). For this we use a reference spectrum as provided by a hyperspectral image camera, and propose efficient deep learning solutions for sensitivity function estimation and spectral reconstruction from a single RGB image. We further expand the concept of spectral reconstruction such that to work for RGB images taken in the wild and propose a solution based on a convolutional network conditioned on the estimated sensitivity function. Besides the proposed solutions, we study also generic and sensitivity specialized models and discuss their limitations. We achieve state-of-the-art competitive results on the standard example-based spectral reconstruction benchmarks: ICVL, CAVE, NUS and NTIRE. Moreover, our experiments show that, for the first time, accurate spectral estimation from a single RGB image in the wild is within our reach.
EndNet: Sparse AutoEncoder Network for Endmember Extraction and Hyperspectral Unmixing
Jul 16, 2018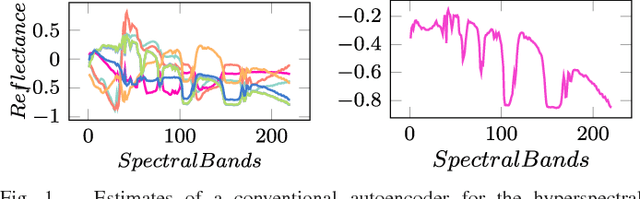



Data acquired from multi-channel sensors is a highly valuable asset to interpret the environment for a variety of remote sensing applications. However, low spatial resolution is a critical limitation for previous sensors and the constituent materials of a scene can be mixed in different fractions due to their spatial interactions. Spectral unmixing is a technique that allows us to obtain the material spectral signatures and their fractions from hyperspectral data. In this paper, we propose a novel endmember extraction and hyperspectral unmixing scheme, so called \textit{EndNet}, that is based on a two-staged autoencoder network. This well-known structure is completely enhanced and restructured by introducing additional layers and a projection metric (i.e., spectral angle distance (SAD) instead of inner product) to achieve an optimum solution. Moreover, we present a novel loss function that is composed of a Kullback-Leibler divergence term with SAD similarity and additional penalty terms to improve the sparsity of the estimates. These modifications enable us to set the common properties of endmembers such as non-linearity and sparsity for autoencoder networks. Lastly, due to the stochastic-gradient based approach, the method is scalable for large-scale data and it can be accelerated on Graphical Processing Units (GPUs). To demonstrate the superiority of our proposed method, we conduct extensive experiments on several well-known datasets. The results confirm that the proposed method considerably improves the performance compared to the state-of-the-art techniques in literature.