 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2D Feature Distillation for Weakly- and Semi-Supervised 3D Semantic Segmentation
Nov 27, 2023



As 3D perception problems grow in popularity and the need for large-scale labeled datasets for LiDAR semantic segmentation increase, new methods arise that aim to reduce the necessity for dense annotations by employing weakly-supervised training. However these methods continue to show weak boundary estimation and high false negative rates for small objects and distant sparse regions. We argue that such weaknesses can be compensated by using RGB images which provide a denser representation of the scene. We propose an image-guidance network (IGNet) which builds upon the idea of distilling high level feature information from a domain adapted synthetically trained 2D semantic segmentation network. We further utilize a one-way contrastive learning scheme alongside a novel mixing strategy called FOVMix, to combat the horizontal field-of-view mismatch between the two sensors and enhance the effects of image guidance. IGNet achieves state-of-the-art results for weakly-supervised LiDAR semantic segmentation on ScribbleKITTI, boasting up to 98% relative performance to fully supervised training with only 8% labeled points, while introducing no additional annotation burden or computational/memory cost during inference. Furthermore, we show that our contributions also prove effective for semi-supervised training, where IGNet claims state-of-the-art results on both ScribbleKITTI and SemanticKITTI.
Prior Based Online Lane Graph Extraction from Single Onboard Camera Image
Jul 25, 2023



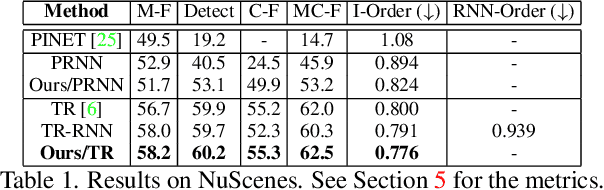
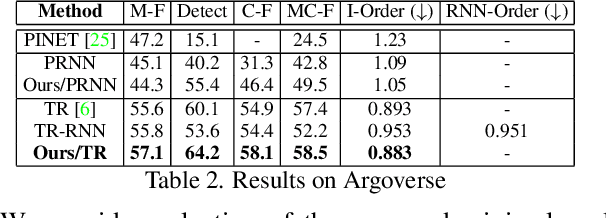
The local road network information is essential for autonomous navigation. This information is commonly obtained from offline HD-Maps in terms of lane graphs. However, the local road network at a given moment can be drastically different than the one given in the offline maps; due to construction works, accidents etc. Moreover, the autonomous vehicle might be at a location not covered in the offline HD-Map. Thus, online estimation of the lane graph is crucial for widespread and reliable autonomous navigation. In this work, we tackle online Bird's-Eye-View lane graph extraction from a single onboard camera image. We propose to use prior information to increase quality of the estimations. The prior is extracted from the dataset through a transformer based Wasserstein Autoencoder. The autoencoder is then used to enhance the initial lane graph estimates. This is done through optimization of the latent space vector. The optimization encourages the lane graph estimation to be logical by discouraging it to diverge from the prior distribution. We test the method on two benchmark datasets, NuScenes and Argoverse. The results show that the proposed method significantly improves the performance compared to state-of-the-art methods.
Improving Online Lane Graph Extraction by Object-Lane Clustering
Jul 20, 2023



Autonomous driving requires accurate local scene understanding information. To this end, autonomous agents deploy object detection and online BEV lane graph extraction methods as a part of their perception stack. In this work, we propose an architecture and loss formulation to improve the accuracy of local lane graph estimates by using 3D object detection outputs. The proposed method learns to assign the objects to centerlines by considering the centerlines as cluster centers and the objects as data points to be assigned a probability distribution over the cluster centers. This training scheme ensures direct supervision on the relationship between lanes and objects, thus leading to better performance. The proposed method improves lane graph estimation substantially over state-of-the-art methods. The extensive ablations show that our method can achieve significant performance improvements by using the outputs of existing 3D object detection methods. Since our method uses the detection outputs rather than detection method intermediate representations, a single model of our method can use any detection method at test time.
Online Lane Graph Extraction from Onboard Video
Apr 03, 2023



Autonomous driving requires a structured understanding of the surrounding road network to navigate. One of the most common and useful representation of such an understanding is done in the form of BEV lane graphs. In this work, we use the video stream from an onboard camera for online extraction of the surrounding's lane graph. Using video, instead of a single image, as input poses both benefits and challenges in terms of combining the information from different timesteps. We study the emerged challenges using three different approaches. The first approach is a post-processing step that is capable of merging single frame lane graph estimates into a unified lane graph. The second approach uses the spatialtemporal embeddings in the transformer to enable the network to discover the best temporal aggregation strategy. Finally, the third, and the proposed method, is an early temporal aggregation through explicit BEV projection and alignment of framewise features. A single model of this proposed simple, yet effective, method can process any number of images, including one, to produce accurate lane graphs. The experiments on the Nuscenes and Argoverse datasets show the validity of all the approaches while highlighting the superiority of the proposed method. The code will be made public.
Piecewise Planar Hulls for Semi-Supervised Learning of 3D Shape and Pose from 2D Images
Nov 14, 2022



We study the problem of estimating 3D shape and pose of an object in terms of keypoints, from a single 2D image. The shape and pose are learned directly from images collected by categories and their partial 2D keypoint annotations.. In this work, we first propose an end-to-end training framework for intermediate 2D keypoints extraction and final 3D shape and pose estimation. The proposed framework is then trained using only the weak supervision of the intermediate 2D keypoints. Additionally, we devise a semi-supervised training framework that benefits from both labeled and unlabeled data. To leverage the unlabeled data, we introduce and exploit the \emph{piece-wise planar hull} prior of the canonical object shape. These planar hulls are defined manually once per object category, with the help of the keypoints. On the one hand, the proposed method learns to segment these planar hulls from the labeled data. On the other hand, it simultaneously enforces the consistency between predicted keypoints and the segmented hulls on the unlabeled data. The enforced consistency allows us to efficiently use the unlabeled data for the task at hand. The proposed method achieves comparable results with fully supervised state-of-the-art methods by using only half of the annotations. Our source code will be made publicly available.
End-to-End Learning of Multi-category 3D Pose and Shape Estimation
Dec 19, 2021

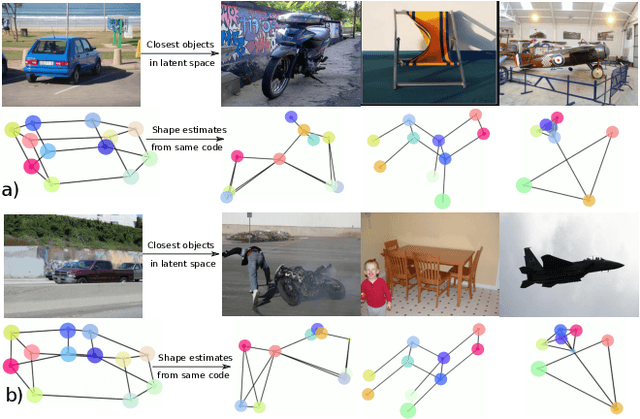
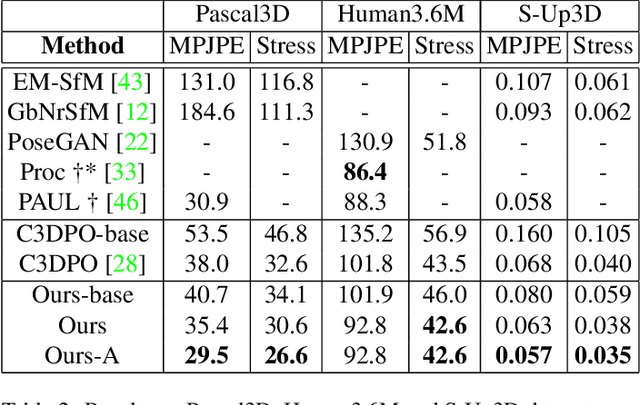
In this paper, we study the representation of the shape and pose of objects using their keypoints. Therefore, we propose an end-to-end method that simultaneously detects 2D keypoints from an image and lifts them to 3D. The proposed method learns both 2D detection and 3D lifting only from 2D keypoints annotations. In this regard, a novel method that explicitly disentangles the pose and 3D shape by means of augmentation-based cyclic self-supervision is proposed, for the first time. In addition of being end-to-end in image to 3D learning, our method also handles objects from multiple categories using a single neural network. We use a Transformer-based architecture to detect the keypoints, as well as to summarize the visual context of the image. This visual context information is then used while lifting the keypoints to 3D, so as to allow the context-based reasoning for better performance. While lifting, our method learns a small set of basis shapes and their sparse non-negative coefficients to represent the 3D shape in canonical frame. Our method can handle occlusions as well as wide variety of object classes. Our experiments on three benchmarks demonstrate that our method performs better than the state-of-the-art. Our source code will be made publicly available.
Topology Preserving Local Road Network Estimation from Single Onboard Camera Image
Dec 19, 2021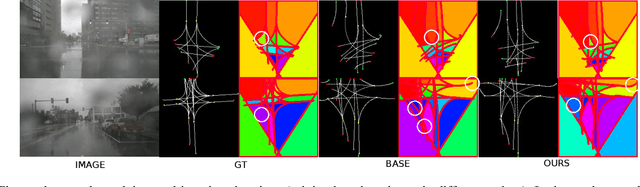
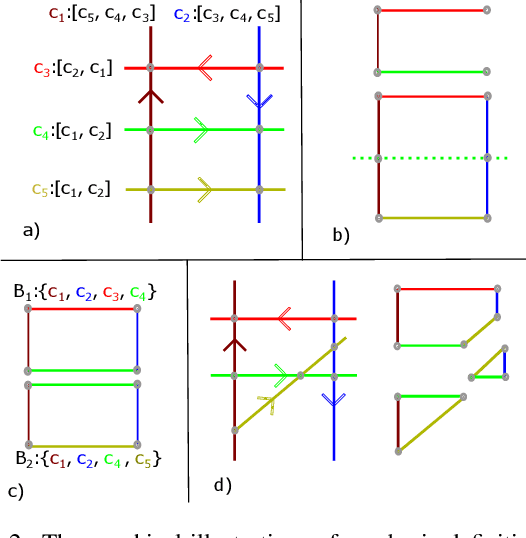
Knowledge of the road network topology is crucial for autonomous planning and navigation. Yet, recovering such topology from a single image has only been explored in part. Furthermore, it needs to refer to the ground plane, where also the driving actions are taken. This paper aims at extracting the local road network topology, directly in the bird's-eye-view (BEV), all in a complex urban setting. The only input consists of a single onboard, forward looking camera image. We represent the road topology using a set of directed lane curves and their interactions, which are captured using their intersection points. To better capture topology, we introduce the concept of \emph{minimal cycles} and their covers. A minimal cycle is the smallest cycle formed by the directed curve segments (between two intersections). The cover is a set of curves whose segments are involved in forming a minimal cycle. We first show that the covers suffice to uniquely represent the road topology. The covers are then used to supervise deep neural networks, along with the lane curve supervision. These learn to predict the road topology from a single input image. The results on the NuScenes and Argoverse benchmarks are significantly better than those obtained with baselines. Our source code will be made publicly available.
Structured Bird's-Eye-View Traffic Scene Understanding from Onboard Images
Oct 05, 2021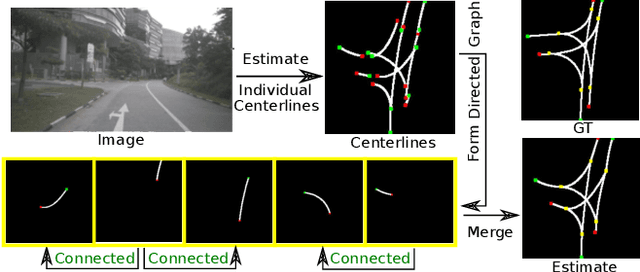
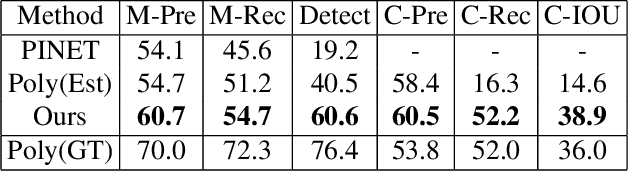
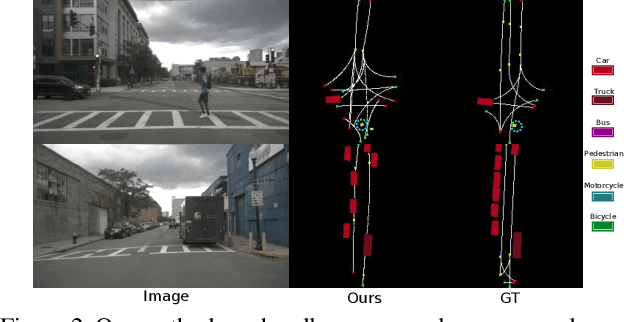
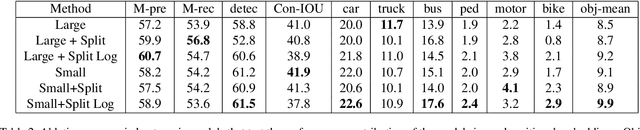
Autonomous navigation requires structured representation of the road network and instance-wise identification of the other traffic agents. Since the traffic scene is defined on the ground plane, this corresponds to scene understanding in the bird's-eye-view (BEV). However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding, making this task very challenging. In this work, we study the problem of extracting a directed graph representing the local road network in BEV coordinates, from a single onboard camera image. Moreover, we show that the method can be extended to detect dynamic objects on the BEV plane. The semantics, locations, and orientations of the detected objects together with the road graph facilitates a comprehensive understanding of the scene. Such understanding becomes fundamental for the downstream tasks, such as path planning and navigation. We validate our approach against powerful baselines and show that our network achieves superior performance. We also demonstrate the effects of various design choices through ablation studies. Code: https://github.com/ybarancan/STSU
Understanding Bird's-Eye View Semantic HD-Maps Using an Onboard Monocular Camera
Dec 05, 2020

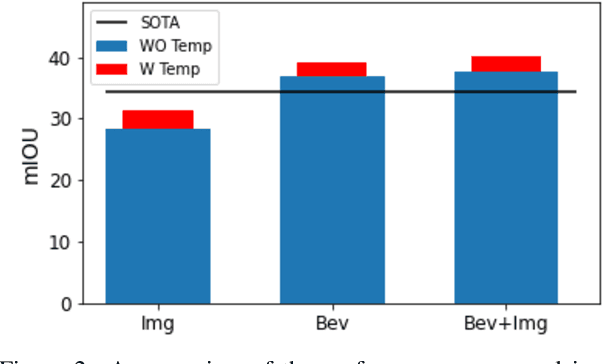

Autonomous navigation requires scene understanding of the action-space to move or anticipate events. For planner agents moving on the ground plane, such as autonomous vehicles, this translates to scene understanding in the bird's-eye view. However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding. In this work, we study scene understanding in the form of online estimation of semantic bird's-eye-view HD-maps using the video input from a single onboard camera. We study three key aspects of this task, image-level understanding, BEV level understanding, and the aggregation of temporal information. Based on these three pillars we propose a novel architecture that combines these three aspects. In our extensive experiments, we demonstrate that the considered aspects are complementary to each other for HD-map understanding. Furthermore, the proposed architecture significantly surpasses the current state-of-the-art.
Towards Spectral Estimation from a Single RGB Image in the Wild
Dec 03, 2018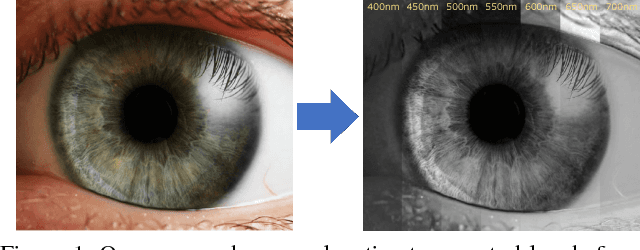
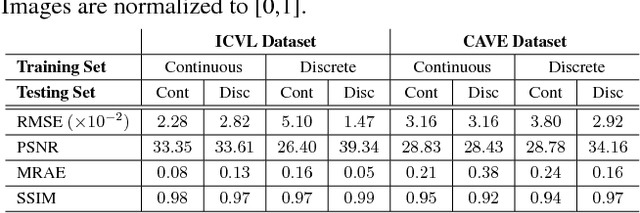
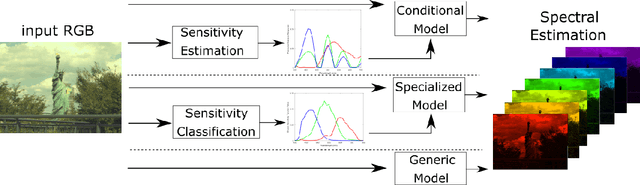

In contrast to the current literature, we address the problem of estimating the spectrum from a single common trichromatic RGB image obtained under unconstrained settings (e.g. unknown camera parameters, unknown scene radiance, unknown scene contents). For this we use a reference spectrum as provided by a hyperspectral image camera, and propose efficient deep learning solutions for sensitivity function estimation and spectral reconstruction from a single RGB image. We further expand the concept of spectral reconstruction such that to work for RGB images taken in the wild and propose a solution based on a convolutional network conditioned on the estimated sensitivity function. Besides the proposed solutions, we study also generic and sensitivity specialized models and discuss their limitations. We achieve state-of-the-art competitive results on the standard example-based spectral reconstruction benchmarks: ICVL, CAVE, NUS and NTIRE. Moreover, our experiments show that, for the first time, accurate spectral estimation from a single RGB image in the wild is within our reach.