 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Bird's-Eye View Semantic HD-Maps Using an Onboard Monocular Camera
Paper and Code


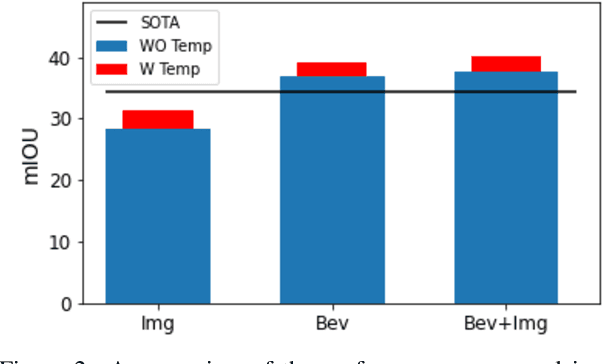

Autonomous navigation requires scene understanding of the action-space to move or anticipate events. For planner agents moving on the ground plane, such as autonomous vehicles, this translates to scene understanding in the bird's-eye view. However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding. In this work, we study scene understanding in the form of online estimation of semantic bird's-eye-view HD-maps using the video input from a single onboard camera. We study three key aspects of this task, image-level understanding, BEV level understanding, and the aggregation of temporal information. Based on these three pillars we propose a novel architecture that combines these three aspects. In our extensive experiments, we demonstrate that the considered aspects are complementary to each other for HD-map understanding. Furthermore, the proposed architecture significantly surpasses the current state-of-the-art.