 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-VLA: True Autoregressive Action Expert for Vision-Language-Action Models
Mar 10, 2026We propose a standalone autoregressive (AR) Action Expert that generates actions as a continuous causal sequence while conditioning on refreshable vision-language prefixes. In contrast to existing Vision-Language-Action (VLA) models and diffusion policies that reset temporal context with each new observation and predict actions reactively, our Action Expert maintains its own history through a long-lived memory and is inherently context-aware. This structure addresses the frequency mismatch between fast control and slow reasoning, enabling efficient independent pretraining of kinematic syntax and modular integration with heavy perception backbones, naturally ensuring spatio-temporally consistent action generation across frames. To synchronize these asynchronous hybrid V-L-A modalities, we utilize a re-anchoring mechanism that mathematically accounts for perception staleness during both training and inference. Experiments on simulated and real-robot manipulation tasks demonstrate that the proposed method can effectively replace traditional chunk-based action heads for both specialist and generalist policies. AR-VLA exhibits superior history awareness and substantially smoother action trajectories while maintaining or exceeding the task success rates of state-of-the-art reactive VLAs. Overall, our work introduces a scalable, context-aware action generation schema that provides a robust structural foundation for training effective robotic policies.
Neural 4D Evolution under Large Topological Changes from 2D Images
Nov 22, 2024In the literature, it has been shown that the evolution of the known explicit 3D surface to the target one can be learned from 2D images using the instantaneous flow field, where the known and target 3D surfaces may largely differ in topology. We are interested in capturing 4D shapes whose topology changes largely over time. We encounter that the straightforward extension of the existing 3D-based method to the desired 4D case performs poorly. In this work, we address the challenges in extending 3D neural evolution to 4D under large topological changes by proposing two novel modifications. More precisely, we introduce (i) a new architecture to discretize and encode the deformation and learn the SDF and (ii) a technique to impose the temporal consistency. (iii) Also, we propose a rendering scheme for color prediction based on Gaussian splatting. Furthermore, to facilitate learning directly from 2D images, we propose a learning framework that can disentangle the geometry and appearance from RGB images. This method of disentanglement, while also useful for the 4D evolution problem that we are concentrating on, is also novel and valid for static scenes. Our extensive experiments on various data provide awesome results and, most importantly, open a new approach toward reconstructing challenging scenes with significant topological changes and deformations. Our source code and the dataset are publicly available at https://github.com/insait-institute/N4DE.
Learning Generative Interactive Environments By Trained Agent Exploration
Sep 10, 2024


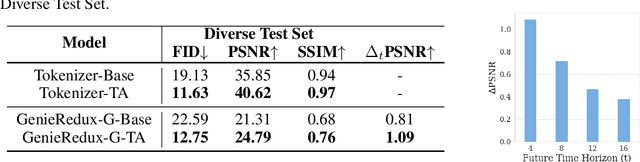
World models are increasingly pivotal in interpreting and simulating the rules and actions of complex environments. Genie, a recent model, excels at learning from visually diverse environments but relies on costly human-collected data. We observe that their alternative method of using random agents is too limited to explore the environment. We propose to improve the model by employing reinforcement learning based agents for data generation. This approach produces diverse datasets that enhance the model's ability to adapt and perform well across various scenarios and realistic actions within the environment. In this paper, we first release the model GenieRedux - an implementation based on Genie. Additionally, we introduce GenieRedux-G, a variant that uses the agent's readily available actions to factor out action prediction uncertainty during validation. Our evaluation, including a replication of the Coinrun case study, shows that GenieRedux-G achieves superior visual fidelity and controllability using the trained agent exploration. The proposed approach is reproducable, scalable and adaptable to new types of environments. Our codebase is available at https://github.com/insait-institute/GenieRedux .
A Unified and Interpretable Emotion Representation and Expression Generation
Apr 01, 2024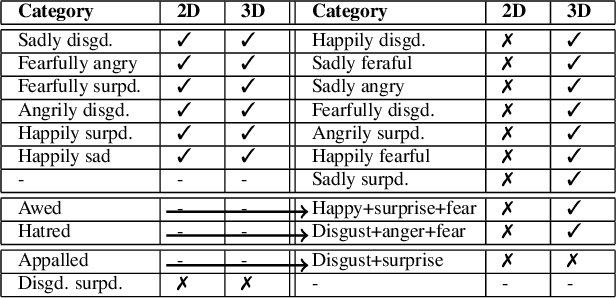
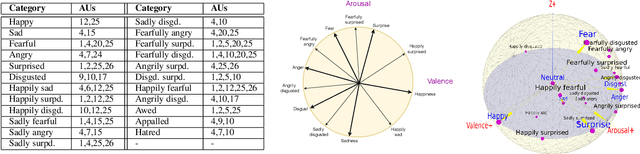

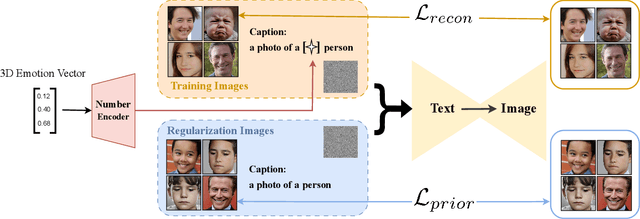
Canonical emotions, such as happy, sad, and fearful, are easy to understand and annotate. However, emotions are often compound, e.g. happily surprised, and can be mapped to the action units (AUs) used for expressing emotions, and trivially to the canonical ones. Intuitively, emotions are continuous as represented by the arousal-valence (AV) model. An interpretable unification of these four modalities - namely, Canonical, Compound, AUs, and AV - is highly desirable, for a better representation and understanding of emotions. However, such unification remains to be unknown in the current literature. In this work, we propose an interpretable and unified emotion model, referred as C2A2. We also develop a method that leverages labels of the non-unified models to annotate the novel unified one. Finally, we modify the text-conditional diffusion models to understand continuous numbers, which are then used to generate continuous expressions using our unified emotion model. Through quantitative and qualitative experiments, we show that our generated images are rich and capture subtle expressions. Our work allows a fine-grained generation of expressions in conjunction with other textual inputs and offers a new label space for emotions at the same time.
Understanding Bird's-Eye View Semantic HD-Maps Using an Onboard Monocular Camera
Dec 05, 2020

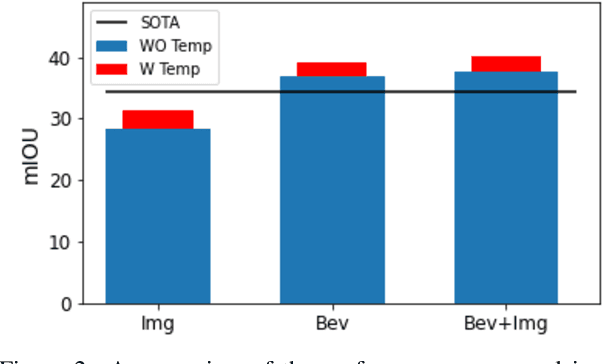

Autonomous navigation requires scene understanding of the action-space to move or anticipate events. For planner agents moving on the ground plane, such as autonomous vehicles, this translates to scene understanding in the bird's-eye view. However, the onboard cameras of autonomous cars are customarily mounted horizontally for a better view of the surrounding. In this work, we study scene understanding in the form of online estimation of semantic bird's-eye-view HD-maps using the video input from a single onboard camera. We study three key aspects of this task, image-level understanding, BEV level understanding, and the aggregation of temporal information. Based on these three pillars we propose a novel architecture that combines these three aspects. In our extensive experiments, we demonstrate that the considered aspects are complementary to each other for HD-map understanding. Furthermore, the proposed architecture significantly surpasses the current state-of-the-art.
Covariance Pooling For Facial Expression Recognition
May 13, 2018

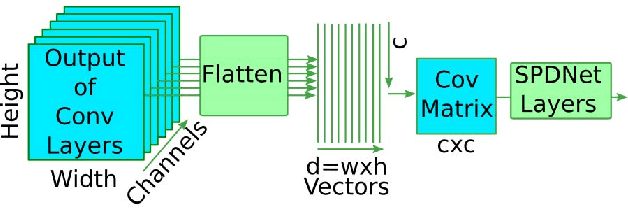
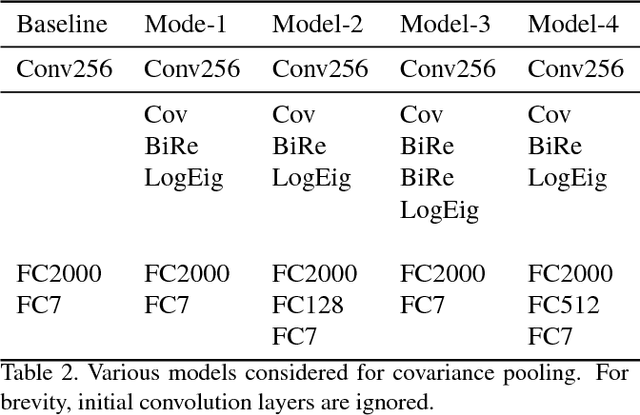
Classifying facial expressions into different categories requires capturing regional distortions of facial landmarks. We believe that second-order statistics such as covariance is better able to capture such distortions in regional facial fea- tures. In this work, we explore the benefits of using a man- ifold network structure for covariance pooling to improve facial expression recognition. In particular, we first employ such kind of manifold networks in conjunction with tradi- tional convolutional networks for spatial pooling within in- dividual image feature maps in an end-to-end deep learning manner. By doing so, we are able to achieve a recognition accuracy of 58.14% on the validation set of Static Facial Expressions in the Wild (SFEW 2.0) and 87.0% on the vali- dation set of Real-World Affective Faces (RAF) Database. Both of these results are the best results we are aware of. Besides, we leverage covariance pooling to capture the tem- poral evolution of per-frame features for video-based facial expression recognition. Our reported results demonstrate the advantage of pooling image-set features temporally by stacking the designed manifold network of covariance pool-ing on top of convolutional network layers.