 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Vehicle Path Planning by Searching With Differentiable Simulation
Nov 14, 2025



Planning allows an agent to safely refine its actions before executing them in the real world. In autonomous driving, this is crucial to avoid collisions and navigate in complex, dense traffic scenarios. One way to plan is to search for the best action sequence. However, this is challenging when all necessary components - policy, next-state predictor, and critic - have to be learned. Here we propose Differentiable Simulation for Search (DSS), a framework that leverages the differentiable simulator Waymax as both a next state predictor and a critic. It relies on the simulator's hardcoded dynamics, making state predictions highly accurate, while utilizing the simulator's differentiability to effectively search across action sequences. Our DSS agent optimizes its actions using gradient descent over imagined future trajectories. We show experimentally that DSS - the combination of planning gradients and stochastic search - significantly improves tracking and path planning accuracy compared to sequence prediction, imitation learning, model-free RL, and other planning methods.
Neural 4D Evolution under Large Topological Changes from 2D Images
Nov 22, 2024In the literature, it has been shown that the evolution of the known explicit 3D surface to the target one can be learned from 2D images using the instantaneous flow field, where the known and target 3D surfaces may largely differ in topology. We are interested in capturing 4D shapes whose topology changes largely over time. We encounter that the straightforward extension of the existing 3D-based method to the desired 4D case performs poorly. In this work, we address the challenges in extending 3D neural evolution to 4D under large topological changes by proposing two novel modifications. More precisely, we introduce (i) a new architecture to discretize and encode the deformation and learn the SDF and (ii) a technique to impose the temporal consistency. (iii) Also, we propose a rendering scheme for color prediction based on Gaussian splatting. Furthermore, to facilitate learning directly from 2D images, we propose a learning framework that can disentangle the geometry and appearance from RGB images. This method of disentanglement, while also useful for the 4D evolution problem that we are concentrating on, is also novel and valid for static scenes. Our extensive experiments on various data provide awesome results and, most importantly, open a new approach toward reconstructing challenging scenes with significant topological changes and deformations. Our source code and the dataset are publicly available at https://github.com/insait-institute/N4DE.
Autonomous Vehicle Controllers From End-to-End Differentiable Simulation
Sep 12, 2024Current methods to learn controllers for autonomous vehicles (AVs) focus on behavioural cloning. Being trained only on exact historic data, the resulting agents often generalize poorly to novel scenarios. Simulators provide the opportunity to go beyond offline datasets, but they are still treated as complicated black boxes, only used to update the global simulation state. As a result, these RL algorithms are slow, sample-inefficient, and prior-agnostic. In this work, we leverage a differentiable simulator and design an analytic policy gradients (APG) approach to training AV controllers on the large-scale Waymo Open Motion Dataset. Our proposed framework brings the differentiable simulator into an end-to-end training loop, where gradients of the environment dynamics serve as a useful prior to help the agent learn a more grounded policy. We combine this setup with a recurrent architecture that can efficiently propagate temporal information across long simulated trajectories. This APG method allows us to learn robust, accurate, and fast policies, while only requiring widely-available expert trajectories, instead of scarce expert actions. We compare to behavioural cloning and find significant improvements in performance and robustness to noise in the dynamics, as well as overall more intuitive human-like handling.
Ternary-type Opacity and Hybrid Odometry for RGB-only NeRF-SLAM
Dec 22, 2023

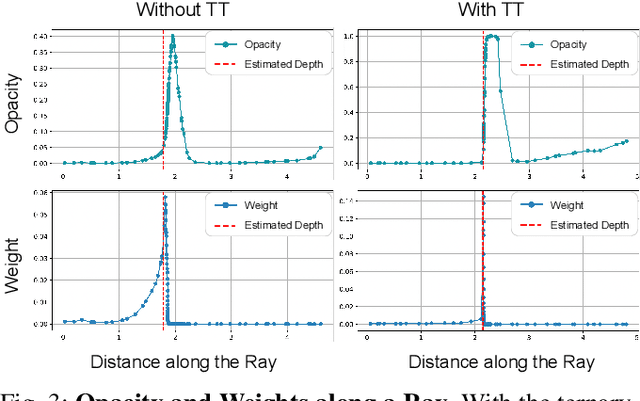

The opacity of rigid 3D scenes with opaque surfaces is considered to be of a binary type. However, we observed that this property is not followed by the existing RGB-only NeRF-SLAM. Therefore, we are motivated to introduce this prior into the RGB-only NeRF-SLAM pipeline. Unfortunately, the optimization through the volumetric rendering function does not facilitate easy integration of the desired prior. Instead, we observed that the opacity of ternary-type (TT) is well supported. In this work, we study why ternary-type opacity is well-suited and desired for the task at hand. In particular, we provide theoretical insights into the process of jointly optimizing radiance and opacity through the volumetric rendering process. Through exhaustive experiments on benchmark datasets, we validate our claim and provide insights into the optimization process, which we believe will unleash the potential of RGB-only NeRF-SLAM. To foster this line of research, we also propose a simple yet novel visual odometry scheme that uses a hybrid combination of volumetric and warping-based image renderings. More specifically, the proposed hybrid odometry (HO) additionally uses image warping-based coarse odometry, leading up to an order of magnitude final speed-up. Furthermore, we show that the proposed TT and HO well complement each other, offering state-of-the-art results on benchmark datasets in terms of both speed and accuracy.
Diffusion-Based Particle-DETR for BEV Perception
Dec 18, 2023



The Bird-Eye-View (BEV) is one of the most widely-used scene representations for visual perception in Autonomous Vehicles (AVs) due to its well suited compatibility to downstream tasks. For the enhanced safety of AVs, modeling perception uncertainty in BEV is crucial. Recent diffusion-based methods offer a promising approach to uncertainty modeling for visual perception but fail to effectively detect small objects in the large coverage of the BEV. Such degradation of performance can be attributed primarily to the specific network architectures and the matching strategy used when training. Here, we address this problem by combining the diffusion paradigm with current state-of-the-art 3D object detectors in BEV. We analyze the unique challenges of this approach, which do not exist with deterministic detectors, and present a simple technique based on object query interpolation that allows the model to learn positional dependencies even in the presence of the diffusion noise. Based on this, we present a diffusion-based DETR model for object detection that bears similarities to particle methods. Abundant experimentation on the NuScenes dataset shows equal or better performance for our generative approach, compared to deterministic state-of-the-art methods. Our source code will be made publicly available.
Bag of Policies for Distributional Deep Exploration
Aug 03, 2023Efficient exploration in complex environments remains a major challenge for reinforcement learning (RL). Compared to previous Thompson sampling-inspired mechanisms that enable temporally extended exploration, i.e., deep exploration, we focus on deep exploration in distributional RL. We develop here a general purpose approach, Bag of Policies (BoP), that can be built on top of any return distribution estimator by maintaining a population of its copies. BoP consists of an ensemble of multiple heads that are updated independently. During training, each episode is controlled by only one of the heads and the collected state-action pairs are used to update all heads off-policy, leading to distinct learning signals for each head which diversify learning and behaviour. To test whether optimistic ensemble method can improve on distributional RL as did on scalar RL, by e.g. Bootstrapped DQN, we implement the BoP approach with a population of distributional actor-critics using Bayesian Distributional Policy Gradients (BDPG). The population thus approximates a posterior distribution of return distributions along with a posterior distribution of policies. Another benefit of building upon BDPG is that it allows to analyze global posterior uncertainty along with local curiosity bonus simultaneously for exploration. As BDPG is already an optimistic method, this pairing helps to investigate if optimism is accumulatable in distributional RL. Overall BoP results in greater robustness and speed during learning as demonstrated by our experimental results on ALE Atari games.