 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Policies for Distributional Deep Exploration
Aug 03, 2023Efficient exploration in complex environments remains a major challenge for reinforcement learning (RL). Compared to previous Thompson sampling-inspired mechanisms that enable temporally extended exploration, i.e., deep exploration, we focus on deep exploration in distributional RL. We develop here a general purpose approach, Bag of Policies (BoP), that can be built on top of any return distribution estimator by maintaining a population of its copies. BoP consists of an ensemble of multiple heads that are updated independently. During training, each episode is controlled by only one of the heads and the collected state-action pairs are used to update all heads off-policy, leading to distinct learning signals for each head which diversify learning and behaviour. To test whether optimistic ensemble method can improve on distributional RL as did on scalar RL, by e.g. Bootstrapped DQN, we implement the BoP approach with a population of distributional actor-critics using Bayesian Distributional Policy Gradients (BDPG). The population thus approximates a posterior distribution of return distributions along with a posterior distribution of policies. Another benefit of building upon BDPG is that it allows to analyze global posterior uncertainty along with local curiosity bonus simultaneously for exploration. As BDPG is already an optimistic method, this pairing helps to investigate if optimism is accumulatable in distributional RL. Overall BoP results in greater robustness and speed during learning as demonstrated by our experimental results on ALE Atari games.
Bayesian Distributional Policy Gradients
Mar 23, 2021


Distributional Reinforcement Learning (RL) maintains the entire probability distribution of the reward-to-go, i.e. the return, providing more learning signals that account for the uncertainty associated with policy performance, which may be beneficial for trading off exploration and exploitation and policy learning in general. Previous works in distributional RL focused mainly on computing the state-action-return distributions, here we model the state-return distributions. This enables us to translate successful conventional RL algorithms that are based on state values into distributional RL. We formulate the distributional Bellman operation as an inference-based auto-encoding process that minimises Wasserstein metrics between target/model return distributions. The proposed algorithm, BDPG (Bayesian Distributional Policy Gradients), uses adversarial training in joint-contrastive learning to estimate a variational posterior from the returns. Moreover, we can now interpret the return prediction uncertainty as an information gain, which allows to obtain a new curiosity measure that helps BDPG steer exploration actively and efficiently. We demonstrate in a suite of Atari 2600 games and MuJoCo tasks, including well known hard-exploration challenges, how BDPG learns generally faster and with higher asymptotic performance than reference distributional RL algorithms.
Optimizing Medical Treatment for Sepsis in Intensive Care: from Reinforcement Learning to Pre-Trial Evaluation
Mar 18, 2020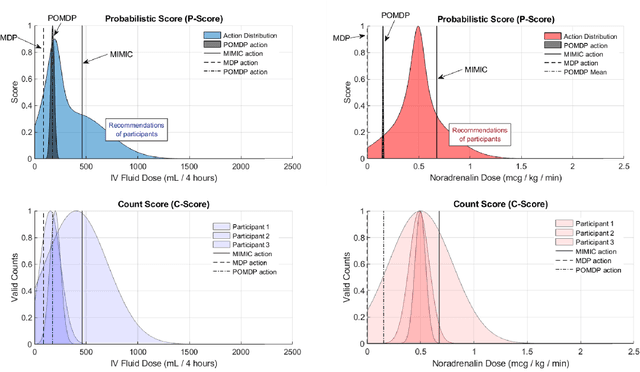
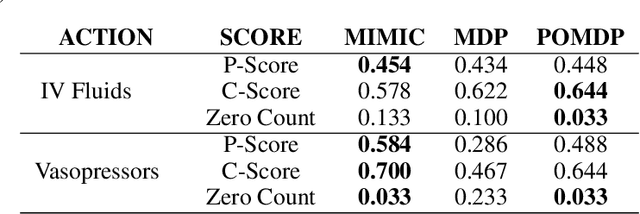
Our aim is to establish a framework where reinforcement learning (RL) of optimizing interventions retrospectively allows us a regulatory compliant pathway to prospective clinical testing of the learned policies in a clinical deployment. We focus on infections in intensive care units which are one of the major causes of death and difficult to treat because of the complex and opaque patient dynamics, and the clinically debated, highly-divergent set of intervention policies required by each individual patient, yet intensive care units are naturally data rich. In our work, we build on RL approaches in healthcare ("AI Clinicians"), and learn off-policy continuous dosing policy of pharmaceuticals for sepsis treatment using historical intensive care data under partially observable MDPs (POMDPs). POMPDs capture uncertainty in patient state better by taking in all historical information, yielding an efficient representation, which we investigate through ablations. We compensate for the lack of exploration in our retrospective data by evaluating each encountered state with a best-first tree search. We mitigate state distributional shift by optimizing our policy in the vicinity of the clinicians' compound policy. Crucially, we evaluate our model recommendations using not only conventional policy evaluations but a novel framework that incorporates human experts: a model-agnostic pre-clinical evaluation method to estimate the accuracy and uncertainty of clinician's decisions versus our system recommendations when confronted with the same individual patient history ("shadow mode").
Optimizing Sequential Medical Treatments with Auto-Encoding Heuristic Search in POMDPs
May 17, 2019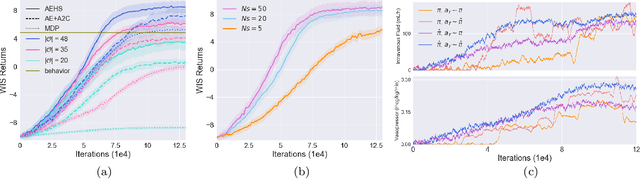
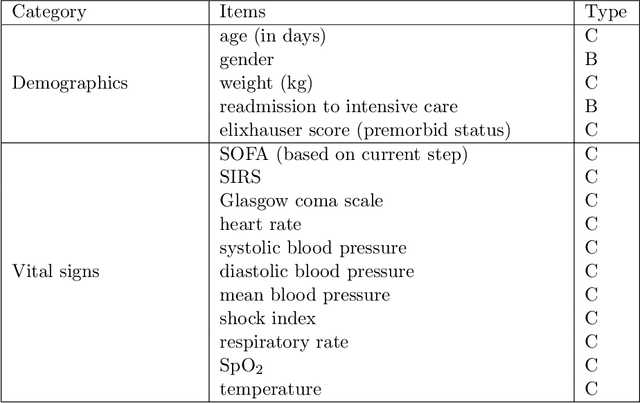
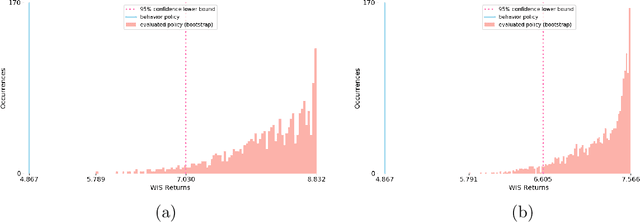
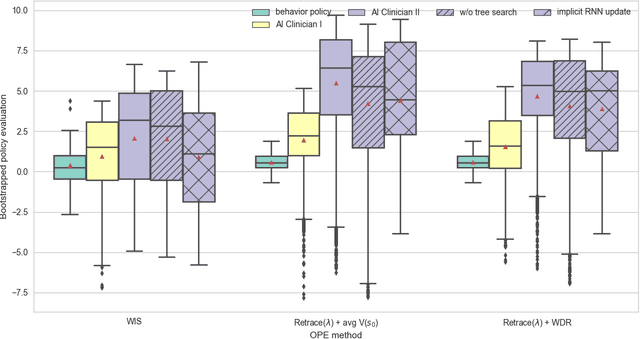
Health-related data is noisy and stochastic in implying the true physiological states of patients, limiting information contained in single-moment observations for sequential clinical decision making. We model patient-clinician interactions as partially observable Markov decision processes (POMDPs) and optimize sequential treatment based on belief states inferred from history sequence. To facilitate inference, we build a variational generative model and boost state representation with a recurrent neural network (RNN), incorporating an auxiliary loss from sequence auto-encoding. Meanwhile, we optimize a continuous policy of drug levels with an actor-critic method where policy gradients are obtained from a stablized off-policy estimate of advantage function, with the value of belief state backed up by parallel best-first suffix trees. We exploit our methodology in optimizing dosages of vasopressor and intravenous fluid for sepsis patients using a retrospective intensive care dataset and evaluate the learned policy with off-policy policy evaluation (OPPE). The results demonstrate that modelling as POMDPs yields better performance than MDPs, and that incorporating heuristic search improves sample efficiency.
The Actor Search Tree Critic for Off-Policy POMDP Learning in Medical Decision Making
Jun 03, 2018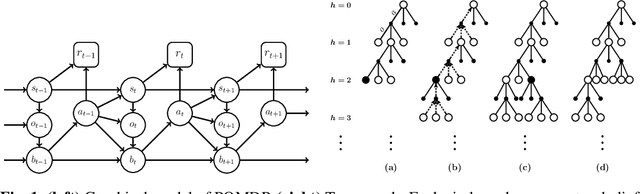
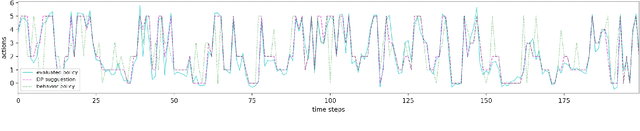
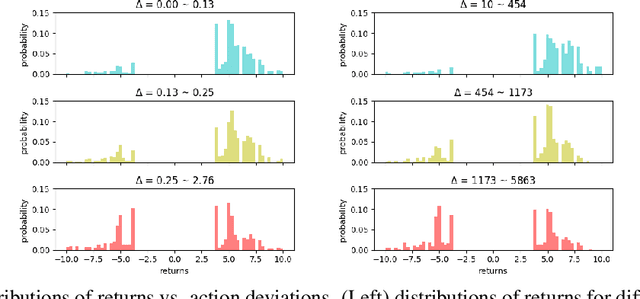
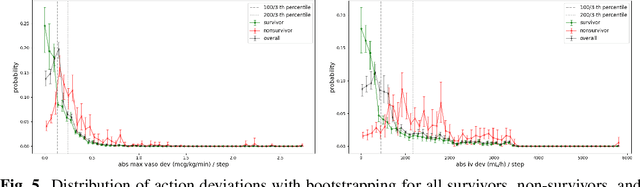
Off-policy reinforcement learning enables near-optimal policy from suboptimal experience, thereby provisions opportunity for artificial intelligence applications in healthcare. Previous works have mainly framed patient-clinician interactions as Markov decision processes, while true physiological states are not necessarily fully observable from clinical data. We capture this situation with partially observable Markov decision process, in which an agent optimises its actions in a belief represented as a distribution of patient states inferred from individual history trajectories. A Gaussian mixture model is fitted for the observed data. Moreover, we take into account the fact that nuance in pharmaceutical dosage could presumably result in significantly different effect by modelling a continuous policy through a Gaussian approximator directly in the policy space, i.e. the actor. To address the challenge of infinite number of possible belief states which renders exact value iteration intractable, we evaluate and plan for only every encountered belief, through heuristic search tree by tightly maintaining lower and upper bounds of the true value of belief. We further resort to function approximations to update value bounds estimation, i.e. the critic, so that the tree search can be improved through more compact bounds at the fringe nodes that will be back-propagated to the root. Both actor and critic parameters are learned via gradient-based approaches. Our proposed policy trained from real intensive care unit data is capable of dictating dosing on vasopressors and intravenous fluids for sepsis patients that lead to the best patient outcomes.