 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Policies for Distributional Deep Exploration
Aug 03, 2023Efficient exploration in complex environments remains a major challenge for reinforcement learning (RL). Compared to previous Thompson sampling-inspired mechanisms that enable temporally extended exploration, i.e., deep exploration, we focus on deep exploration in distributional RL. We develop here a general purpose approach, Bag of Policies (BoP), that can be built on top of any return distribution estimator by maintaining a population of its copies. BoP consists of an ensemble of multiple heads that are updated independently. During training, each episode is controlled by only one of the heads and the collected state-action pairs are used to update all heads off-policy, leading to distinct learning signals for each head which diversify learning and behaviour. To test whether optimistic ensemble method can improve on distributional RL as did on scalar RL, by e.g. Bootstrapped DQN, we implement the BoP approach with a population of distributional actor-critics using Bayesian Distributional Policy Gradients (BDPG). The population thus approximates a posterior distribution of return distributions along with a posterior distribution of policies. Another benefit of building upon BDPG is that it allows to analyze global posterior uncertainty along with local curiosity bonus simultaneously for exploration. As BDPG is already an optimistic method, this pairing helps to investigate if optimism is accumulatable in distributional RL. Overall BoP results in greater robustness and speed during learning as demonstrated by our experimental results on ALE Atari games.
Breaking Bad News in the Era of Artificial Intelligence and Algorithmic Medicine: An Exploration of Disclosure and its Ethical Justification using the Hedonic Calculus
Jun 23, 2022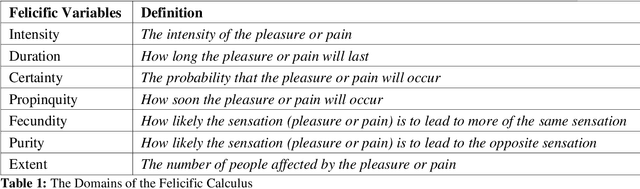

An appropriate ethical framework around the use of Artificial Intelligence (AI) in healthcare has become a key desirable with the increasingly widespread deployment of this technology. Advances in AI hold the promise of improving the precision of outcome prediction at the level of the individual. However, the addition of these technologies to patient-clinician interactions, as with any complex human interaction, has potential pitfalls. While physicians have always had to carefully consider the ethical background and implications of their actions, detailed deliberations around fast-moving technological progress may not have kept up. We use a common but key challenge in healthcare interactions, the disclosure of bad news (likely imminent death), to illustrate how the philosophical framework of the 'Felicific Calculus' developed in the 18th century by Jeremy Bentham, may have a timely quasi-quantitative application in the age of AI. We show how this ethical algorithm can be used to assess, across seven mutually exclusive and exhaustive domains, whether an AI-supported action can be morally justified.
CNNATT: Deep EEG & fNIRS Real-Time Decoding of bimanual forces
Mar 23, 2021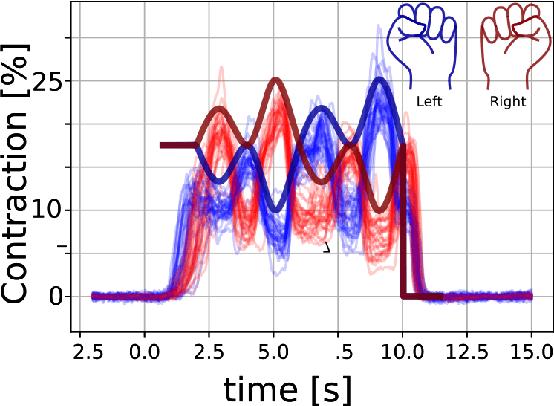
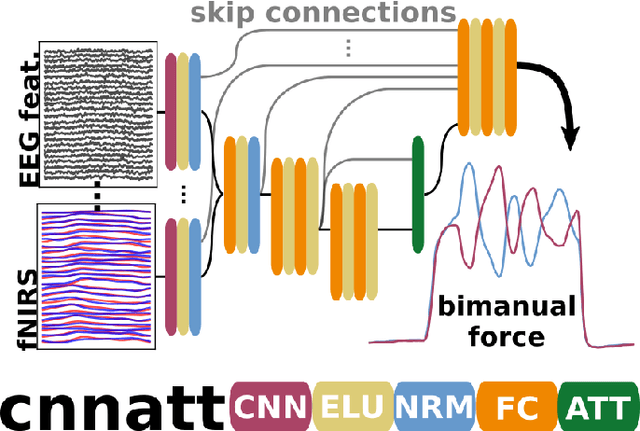
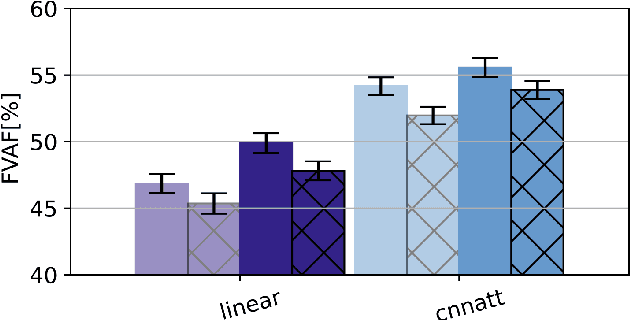
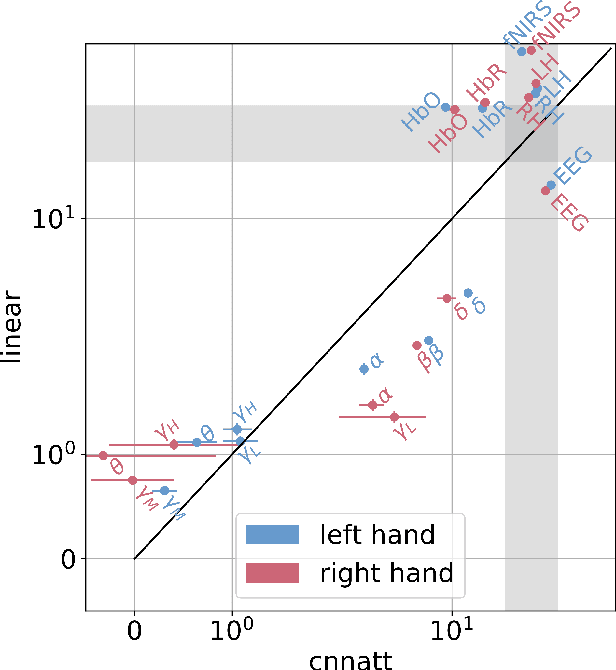
Non-invasive cortical neural interfaces have only achieved modest performance in cortical decoding of limb movements and their forces, compared to invasive brain-computer interfaces (BCIs). While non-invasive methodologies are safer, cheaper and vastly more accessible technologies, signals suffer from either poor resolution in the space domain (EEG) or the temporal domain (BOLD signal of functional Near Infrared Spectroscopy, fNIRS). The non-invasive BCI decoding of bimanual force generation and the continuous force signal has not been realised before and so we introduce an isometric grip force tracking task to evaluate the decoding. We find that combining EEG and fNIRS using deep neural networks works better than linear models to decode continuous grip force modulations produced by the left and the right hand. Our multi-modal deep learning decoder achieves 55.2 FVAF[%] in force reconstruction and improves the decoding performance by at least 15% over each individual modality. Our results show a way to achieve continuous hand force decoding using cortical signals obtained with non-invasive mobile brain imaging has immediate impact for rehabilitation, restoration and consumer applications.
Model-Agnostic Meta-Learning for EEG Motor Imagery Decoding in Brain-Computer-Interfacing
Mar 10, 2021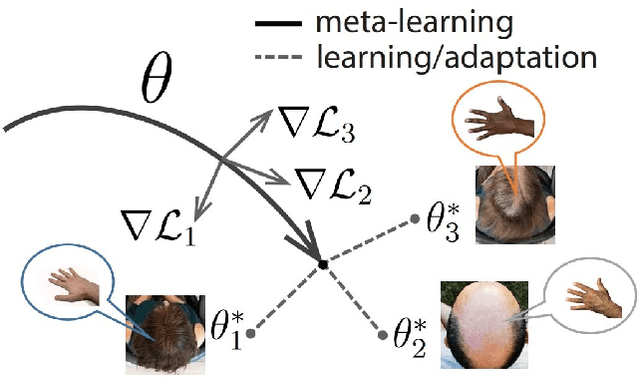
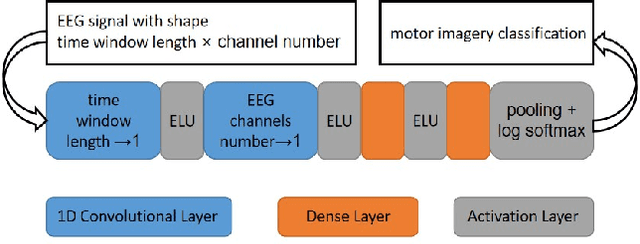
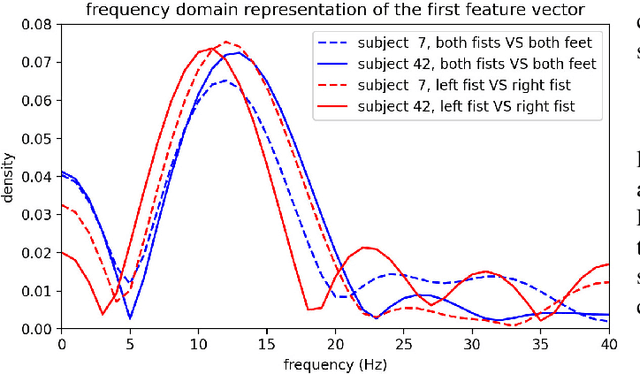
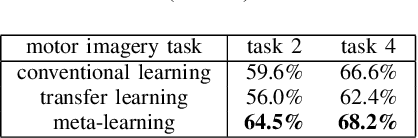
We introduce here the idea of Meta-Learning for training EEG BCI decoders. Meta-Learning is a way of training machine learning systems so they learn to learn. We apply here meta-learning to a simple Deep Learning BCI architecture and compare it to transfer learning on the same architecture. Our Meta-learning strategy operates by finding optimal parameters for the BCI decoder so that it can quickly generalise between different users and recording sessions -- thereby also generalising to new users or new sessions quickly. We tested our algorithm on the Physionet EEG motor imagery dataset. Our approach increased motor imagery classification accuracy between 60% to 80%, outperforming other algorithms under the little-data condition. We believe that establishing the meta-learning or learning-to-learn approach will help neural engineering and human interfacing with the challenges of quickly setting up decoders of neural signals to make them more suitable for daily-life.
HemCNN: Deep Learning enables decoding of fNIRS cortical signals in hand grip motor tasks
Mar 09, 2021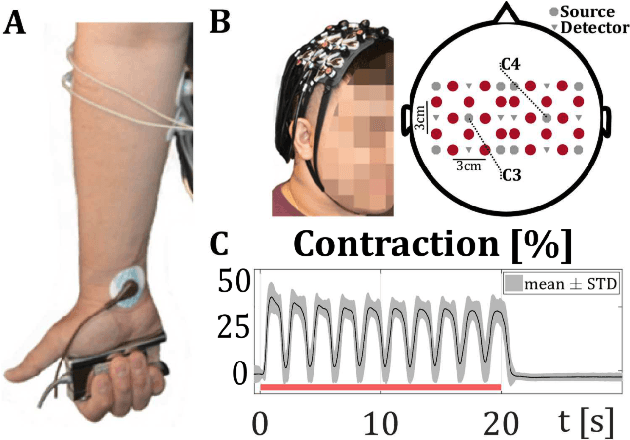
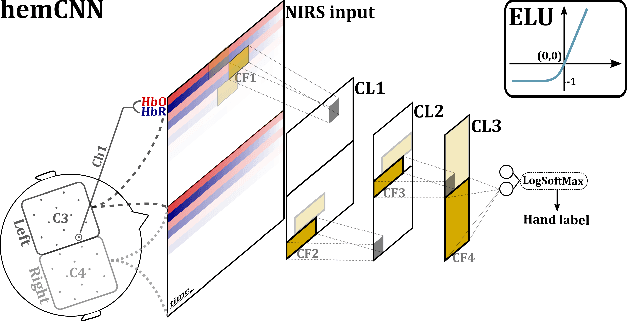
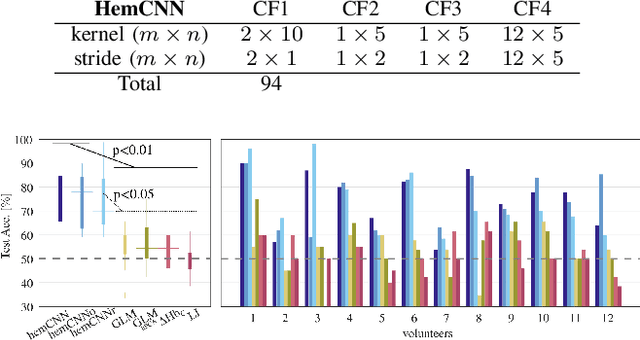
We solve the fNIRS left/right hand force decoding problem using a data-driven approach by using a convolutional neural network architecture, the HemCNN. We test HemCNN's decoding capabilities to decode in a streaming way the hand, left or right, from fNIRS data. HemCNN learned to detect which hand executed a grasp at a naturalistic hand action speed of $~1\,$Hz, outperforming standard methods. Since HemCNN does not require baseline correction and the convolution operation is invariant to time translations, our method can help to unlock fNIRS for a variety of real-time tasks. Mobile brain imaging and mobile brain machine interfacing can benefit from this to develop real-world neuroscience and practical human neural interfacing based on BOLD-like signals for the evaluation, assistance and rehabilitation of force generation, such as fusion of fNIRS with EEG signals.
Action Grammars: A Cognitive Model for Learning Temporal Abstractions
Jul 29, 2019
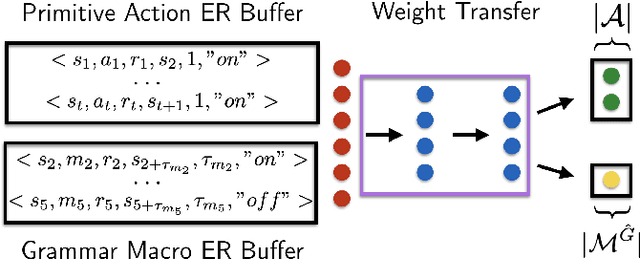
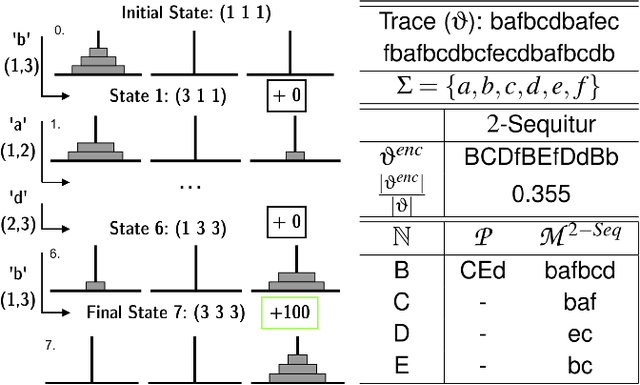

Hierarchical Reinforcement Learning algorithms have successfully been applied to temporal credit assignment problems with sparse reward signals. However, state-of-the-art algorithms require manual specification of subtask structures, a sample inefficient exploration phase and lack semantic interpretability. Human infants, on the other hand, efficiently detect hierarchical sub-structures induced by their surroundings. In this work we propose a cognitive-inspired Reinforcement Learning architecture which uses grammar induction to identify sub-goal policies. More specifically, by treating an on-policy trajectory as a sentence sampled from the policy-conditioned language of the environment, we identify hierarchical constituents with the help of unsupervised grammatical inference. The resulting set of temporal abstractions is called action grammars (Pastra & Aloimonos, 2012) and can be used to enable efficient imitation, transfer and online learning.
RLOC: Neurobiologically Inspired Hierarchical Reinforcement Learning Algorithm for Continuous Control of Nonlinear Dynamical Systems
Mar 07, 2019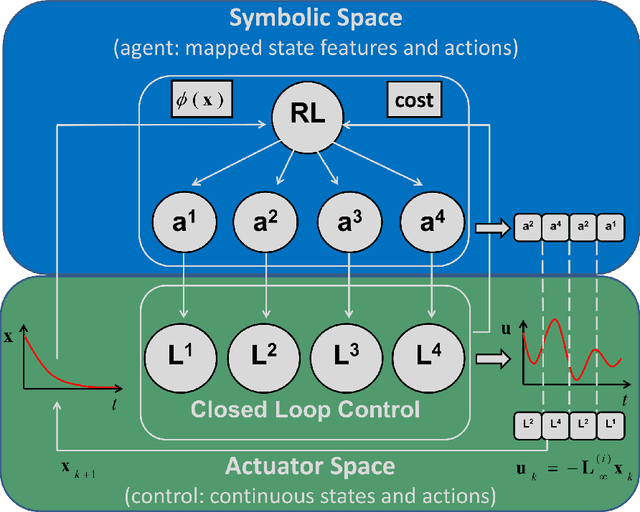

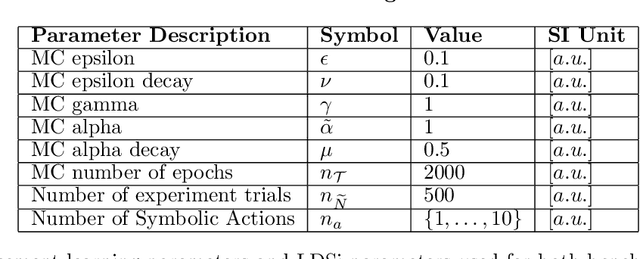
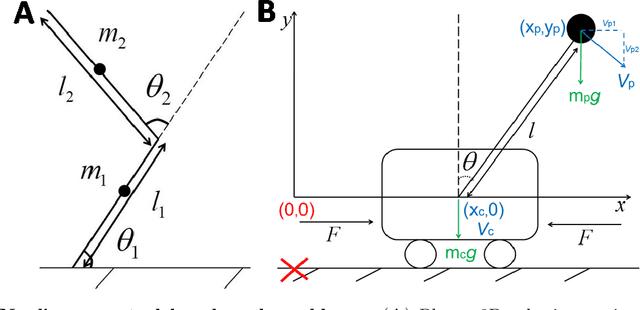
Nonlinear optimal control problems are often solved with numerical methods that require knowledge of system's dynamics which may be difficult to infer, and that carry a large computational cost associated with iterative calculations. We present a novel neurobiologically inspired hierarchical learning framework, Reinforcement Learning Optimal Control, which operates on two levels of abstraction and utilises a reduced number of controllers to solve nonlinear systems with unknown dynamics in continuous state and action spaces. Our approach is inspired by research at two levels of abstraction: first, at the level of limb coordination human behaviour is explained by linear optimal feedback control theory. Second, in cognitive tasks involving learning symbolic level action selection, humans learn such problems using model-free and model-based reinforcement learning algorithms. We propose that combining these two levels of abstraction leads to a fast global solution of nonlinear control problems using reduced number of controllers. Our framework learns the local task dynamics from naive experience and forms locally optimal infinite horizon Linear Quadratic Regulators which produce continuous low-level control. A top-level reinforcement learner uses the controllers as actions and learns how to best combine them in state space while maximising a long-term reward. A single optimal control objective function drives high-level symbolic learning by providing training signals on desirability of each selected controller. We show that a small number of locally optimal linear controllers are able to solve global nonlinear control problems with unknown dynamics when combined with a reinforcement learner in this hierarchical framework. Our algorithm competes in terms of computational cost and solution quality with sophisticated control algorithms and we illustrate this with solutions to benchmark problems.
Improving Sepsis Treatment Strategies by Combining Deep and Kernel-Based Reinforcement Learning
Jan 15, 2019
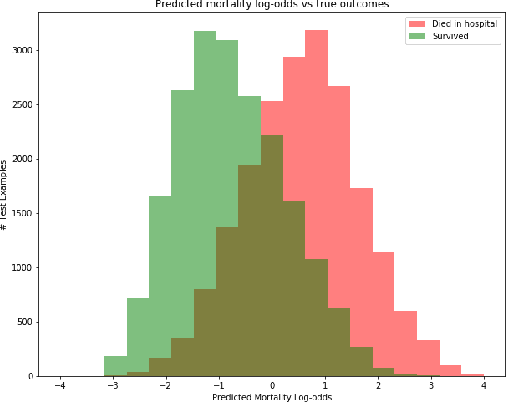


Sepsis is the leading cause of mortality in the ICU. It is challenging to manage because individual patients respond differently to treatment. Thus, tailoring treatment to the individual patient is essential for the best outcomes. In this paper, we take steps toward this goal by applying a mixture-of-experts framework to personalize sepsis treatment. The mixture model selectively alternates between neighbor-based (kernel) and deep reinforcement learning (DRL) experts depending on patient's current history. On a large retrospective cohort, this mixture-based approach outperforms physician, kernel only, and DRL-only experts.
Representation Balancing MDPs for Off-Policy Policy Evaluation
Oct 31, 2018

We study the problem of off-policy policy evaluation (OPPE) in RL. In contrast to prior work, we consider how to estimate both the individual policy value and average policy value accurately. We draw inspiration from recent work in causal reasoning, and propose a new finite sample generalization error bound for value estimates from MDP models. Using this upper bound as an objective, we develop a learning algorithm of an MDP model with a balanced representation, and show that our approach can yield substantially lower MSE in common synthetic benchmarks and a HIV treatment simulation domain.
Behaviour Policy Estimation in Off-Policy Policy Evaluation: Calibration Matters
Jul 10, 2018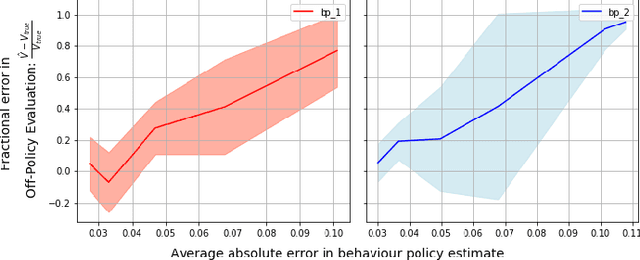

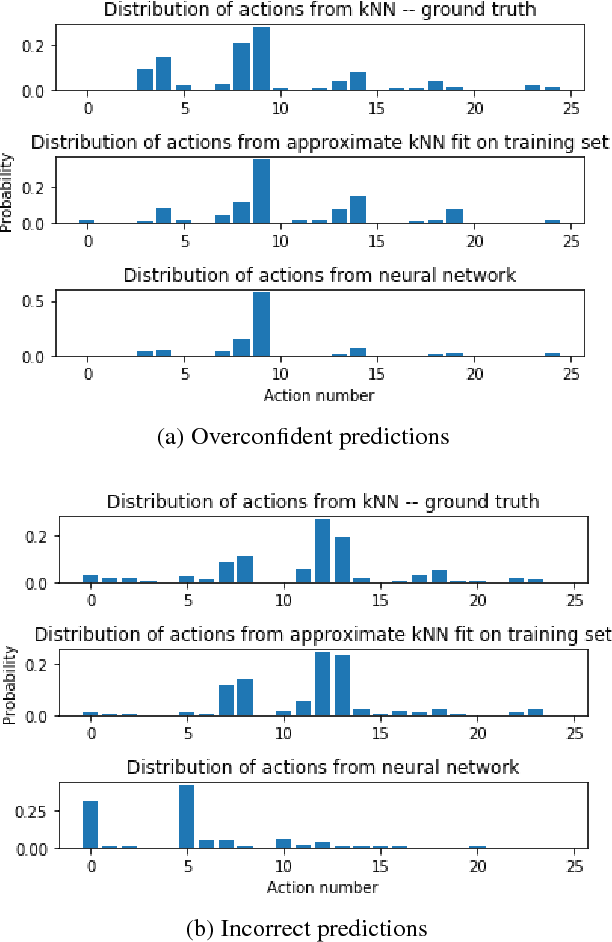

In this work, we consider the problem of estimating a behaviour policy for use in Off-Policy Policy Evaluation (OPE) when the true behaviour policy is unknown. Via a series of empirical studies, we demonstrate how accurate OPE is strongly dependent on the calibration of estimated behaviour policy models: how precisely the behaviour policy is estimated from data. We show how powerful parametric models such as neural networks can result in highly uncalibrated behaviour policy models on a real-world medical dataset, and illustrate how a simple, non-parametric, k-nearest neighbours model produces better calibrated behaviour policy estimates and can be used to obtain superior importance sampling-based OPE estimates.