 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Grammars: A Cognitive Model for Learning Temporal Abstractions
Paper and Code

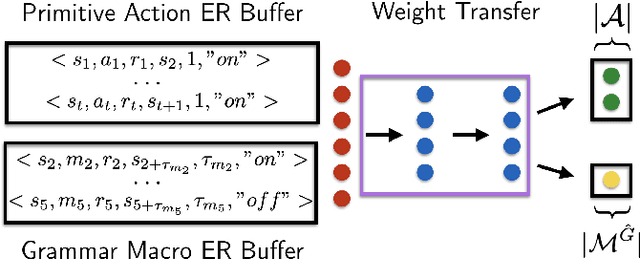
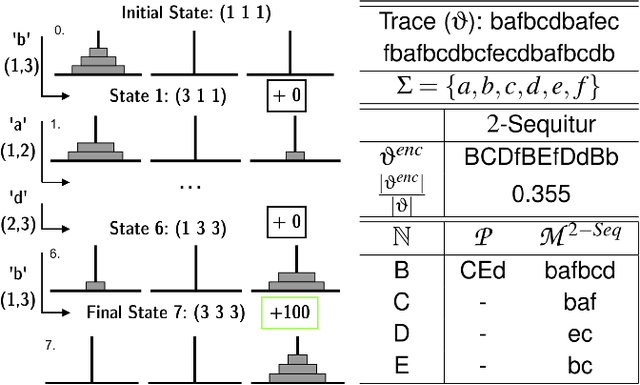

Hierarchical Reinforcement Learning algorithms have successfully been applied to temporal credit assignment problems with sparse reward signals. However, state-of-the-art algorithms require manual specification of subtask structures, a sample inefficient exploration phase and lack semantic interpretability. Human infants, on the other hand, efficiently detect hierarchical sub-structures induced by their surroundings. In this work we propose a cognitive-inspired Reinforcement Learning architecture which uses grammar induction to identify sub-goal policies. More specifically, by treating an on-policy trajectory as a sentence sampled from the policy-conditioned language of the environment, we identify hierarchical constituents with the help of unsupervised grammatical inference. The resulting set of temporal abstractions is called action grammars (Pastra & Aloimonos, 2012) and can be used to enable efficient imitation, transfer and online learning.