 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-Radial Projection for Constrained End-to-End Learning
Feb 03, 2026Integrating hard constraints into deep learning is essential for safety-critical systems. Yet existing constructive layers that project predictions onto constraint boundaries face a fundamental bottleneck: gradient saturation. By collapsing exterior points onto lower-dimensional surfaces, standard orthogonal projections induce rank-deficient Jacobians, which nullify gradients orthogonal to active constraints and hinder optimization. We introduce Soft-Radial Projection, a differentiable reparameterization layer that circumvents this issue through a radial mapping from Euclidean space into the interior of the feasible set. This construction guarantees strict feasibility while preserving a full-rank Jacobian almost everywhere, thereby preventing the optimization stalls typical of boundary-based methods. We theoretically prove that the architecture retains the universal approximation property and empirically show improved convergence behavior and solution quality over state-of-the-art optimization- and projection-based baselines.
Contrastive Geometric Learning Unlocks Unified Structure- and Ligand-Based Drug Design
Jan 14, 2026Structure-based and ligand-based computational drug design have traditionally relied on disjoint data sources and modeling assumptions, limiting their joint use at scale. In this work, we introduce Contrastive Geometric Learning for Unified Computational Drug Design (ConGLUDe), a single contrastive geometric model that unifies structure- and ligand-based training. ConGLUDe couples a geometric protein encoder that produces whole-protein representations and implicit embeddings of predicted binding sites with a fast ligand encoder, removing the need for pre-defined pockets. By aligning ligands with both global protein representations and multiple candidate binding sites through contrastive learning, ConGLUDe supports ligand-conditioned pocket prediction in addition to virtual screening and target fishing, while being trained jointly on protein-ligand complexes and large-scale bioactivity data. Across diverse benchmarks, ConGLUDe achieves state-of-the-art zero-shot virtual screening performance in settings where no binding pocket information is provided as input, substantially outperforms existing methods on a challenging target fishing task, and demonstrates competitive ligand-conditioned pocket selection. These results highlight the advantages of unified structure-ligand training and position ConGLUDe as a step toward general-purpose foundation models for drug discovery.
Efficient Best-of-Both-Worlds Algorithms for Contextual Combinatorial Semi-Bandits
Aug 26, 2025
We introduce the first best-of-both-worlds algorithm for contextual combinatorial semi-bandits that simultaneously guarantees $\widetilde{\mathcal{O}}(\sqrt{T})$ regret in the adversarial regime and $\widetilde{\mathcal{O}}(\ln T)$ regret in the corrupted stochastic regime. Our approach builds on the Follow-the-Regularized-Leader (FTRL) framework equipped with a Shannon entropy regularizer, yielding a flexible method that admits efficient implementations. Beyond regret bounds, we tackle the practical bottleneck in FTRL (or, equivalently, Online Stochastic Mirror Descent) arising from the high-dimensional projection step encountered in each round of interaction. By leveraging the Karush-Kuhn-Tucker conditions, we transform the $K$-dimensional convex projection problem into a single-variable root-finding problem, dramatically accelerating each round. Empirical evaluations demonstrate that this combined strategy not only attains the attractive regret bounds of best-of-both-worlds algorithms but also delivers substantial per-round speed-ups, making it well-suited for large-scale, real-time applications.
Global Group Fairness in Federated Learning via Function Tracking
Mar 19, 2025



We investigate group fairness regularizers in federated learning, aiming to train a globally fair model in a distributed setting. Ensuring global fairness in distributed training presents unique challenges, as fairness regularizers typically involve probability metrics between distributions across all clients and are not naturally separable by client. To address this, we introduce a function-tracking scheme for the global fairness regularizer based on a Maximum Mean Discrepancy (MMD), which incurs a small communication overhead. This scheme seamlessly integrates into most federated learning algorithms while preserving rigorous convergence guarantees, as demonstrated in the context of FedAvg. Additionally, when enforcing differential privacy, the kernel-based MMD regularization enables straightforward analysis through a change of kernel, leveraging an intuitive interpretation of kernel convolution. Numerical experiments confirm our theoretical insights.
Towards Optimal Offline Reinforcement Learning
Mar 15, 2025We study offline reinforcement learning problems with a long-run average reward objective. The state-action pairs generated by any fixed behavioral policy thus follow a Markov chain, and the {\em empirical} state-action-next-state distribution satisfies a large deviations principle. We use the rate function of this large deviations principle to construct an uncertainty set for the unknown {\em true} state-action-next-state distribution. We also construct a distribution shift transformation that maps any distribution in this uncertainty set to a state-action-next-state distribution of the Markov chain generated by a fixed evaluation policy, which may differ from the unknown behavioral policy. We prove that the worst-case average reward of the evaluation policy with respect to all distributions in the shifted uncertainty set provides, in a rigorous statistical sense, the least conservative estimator for the average reward under the unknown true distribution. This guarantee is available even if one has only access to one single trajectory of serially correlated state-action pairs. The emerging robust optimization problem can be viewed as a robust Markov decision process with a non-rectangular uncertainty set. We adapt an efficient policy gradient algorithm to solve this problem. Numerical experiments show that our methods compare favorably against state-of-the-art methods.
Optimism in the Face of Ambiguity Principle for Multi-Armed Bandits
Sep 30, 2024
Follow-The-Regularized-Leader (FTRL) algorithms often enjoy optimal regret for adversarial as well as stochastic bandit problems and allow for a streamlined analysis. Nonetheless, FTRL algorithms require the solution of an optimization problem in every iteration and are thus computationally challenging. In contrast, Follow-The-Perturbed-Leader (FTPL) algorithms achieve computational efficiency by perturbing the estimates of the rewards of the arms, but their regret analysis is cumbersome. We propose a new FTPL algorithm that generates optimal policies for both adversarial and stochastic multi-armed bandits. Like FTRL, our algorithm admits a unified regret analysis, and similar to FTPL, it offers low computational costs. Unlike existing FTPL algorithms that rely on independent additive disturbances governed by a \textit{known} distribution, we allow for disturbances governed by an \textit{ambiguous} distribution that is only known to belong to a given set and propose a principle of optimism in the face of ambiguity. Consequently, our framework generalizes existing FTPL algorithms. It also encapsulates a broad range of FTRL methods as special cases, including several optimal ones, which appears to be impossible with current FTPL methods. Finally, we use techniques from discrete choice theory to devise an efficient bisection algorithm for computing the optimistic arm sampling probabilities. This algorithm is up to $10^4$ times faster than standard FTRL algorithms that solve an optimization problem in every iteration. Our results not only settle existing conjectures but also provide new insights into the impact of perturbations by mapping FTRL to FTPL.
A Geometric Unification of Distributionally Robust Covariance Estimators: Shrinking the Spectrum by Inflating the Ambiguity Set
May 30, 2024



The state-of-the-art methods for estimating high-dimensional covariance matrices all shrink the eigenvalues of the sample covariance matrix towards a data-insensitive shrinkage target. The underlying shrinkage transformation is either chosen heuristically - without compelling theoretical justification - or optimally in view of restrictive distributional assumptions. In this paper, we propose a principled approach to construct covariance estimators without imposing restrictive assumptions. That is, we study distributionally robust covariance estimation problems that minimize the worst-case Frobenius error with respect to all data distributions close to a nominal distribution, where the proximity of distributions is measured via a divergence on the space of covariance matrices. We identify mild conditions on this divergence under which the resulting minimizers represent shrinkage estimators. We show that the corresponding shrinkage transformations are intimately related to the geometrical properties of the underlying divergence. We also prove that our robust estimators are efficiently computable and asymptotically consistent and that they enjoy finite-sample performance guarantees. We exemplify our general methodology by synthesizing explicit estimators induced by the Kullback-Leibler, Fisher-Rao, and Wasserstein divergences. Numerical experiments based on synthetic and real data show that our robust estimators are competitive with state-of-the-art estimators.
A Large Deviations Perspective on Policy Gradient Algorithms
Nov 13, 2023We derive the first large deviation rate function for the stochastic iterates generated by policy gradient methods with a softmax parametrization and an entropy regularized objective. Leveraging the contraction principle from large deviations theory, we also develop a general recipe for deriving exponential convergence rates for a wide spectrum of other policy parametrizations. This approach unifies several results from the literature and simplifies existing proof techniques.
Contextual Stochastic Bilevel Optimization
Oct 27, 2023
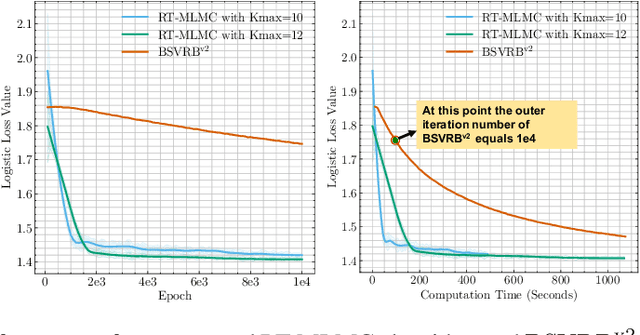


We introduce contextual stochastic bilevel optimization (CSBO) -- a stochastic bilevel optimization framework with the lower-level problem minimizing an expectation conditioned on some contextual information and the upper-level decision variable. This framework extends classical stochastic bilevel optimization when the lower-level decision maker responds optimally not only to the decision of the upper-level decision maker but also to some side information and when there are multiple or even infinite many followers. It captures important applications such as meta-learning, personalized federated learning, end-to-end learning, and Wasserstein distributionally robust optimization with side information (WDRO-SI). Due to the presence of contextual information, existing single-loop methods for classical stochastic bilevel optimization are unable to converge. To overcome this challenge, we introduce an efficient double-loop gradient method based on the Multilevel Monte-Carlo (MLMC) technique and establish its sample and computational complexities. When specialized to stochastic nonconvex optimization, our method matches existing lower bounds. For meta-learning, the complexity of our method does not depend on the number of tasks. Numerical experiments further validate our theoretical results.
Unifying Distributionally Robust Optimization via Optimal Transport Theory
Aug 10, 2023


In the past few years, there has been considerable interest in two prominent approaches for Distributionally Robust Optimization (DRO): Divergence-based and Wasserstein-based methods. The divergence approach models misspecification in terms of likelihood ratios, while the latter models it through a measure of distance or cost in actual outcomes. Building upon these advances, this paper introduces a novel approach that unifies these methods into a single framework based on optimal transport (OT) with conditional moment constraints. Our proposed approach, for example, makes it possible for optimal adversarial distributions to simultaneously perturb likelihood and outcomes, while producing an optimal (in an optimal transport sense) coupling between the baseline model and the adversarial model.Additionally, the paper investigates several duality results and presents tractable reformulations that enhance the practical applicability of this unified framework.