 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified and Interpretable Emotion Representation and Expression Generation
Apr 01, 2024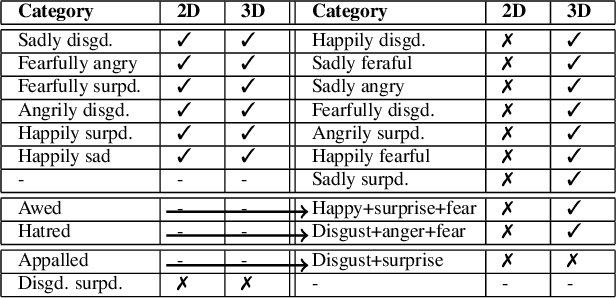
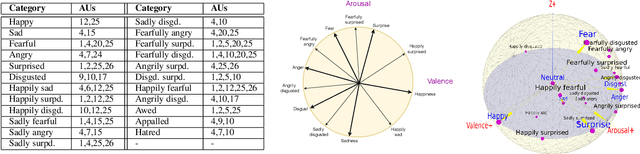

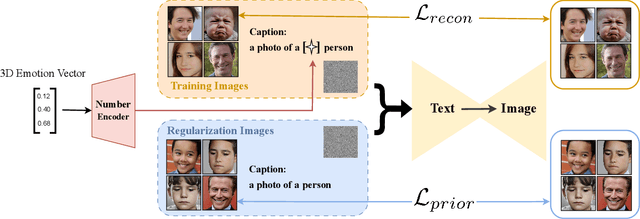
Canonical emotions, such as happy, sad, and fearful, are easy to understand and annotate. However, emotions are often compound, e.g. happily surprised, and can be mapped to the action units (AUs) used for expressing emotions, and trivially to the canonical ones. Intuitively, emotions are continuous as represented by the arousal-valence (AV) model. An interpretable unification of these four modalities - namely, Canonical, Compound, AUs, and AV - is highly desirable, for a better representation and understanding of emotions. However, such unification remains to be unknown in the current literature. In this work, we propose an interpretable and unified emotion model, referred as C2A2. We also develop a method that leverages labels of the non-unified models to annotate the novel unified one. Finally, we modify the text-conditional diffusion models to understand continuous numbers, which are then used to generate continuous expressions using our unified emotion model. Through quantitative and qualitative experiments, we show that our generated images are rich and capture subtle expressions. Our work allows a fine-grained generation of expressions in conjunction with other textual inputs and offers a new label space for emotions at the same time.