 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance Pooling For Facial Expression Recognition
Paper and Code


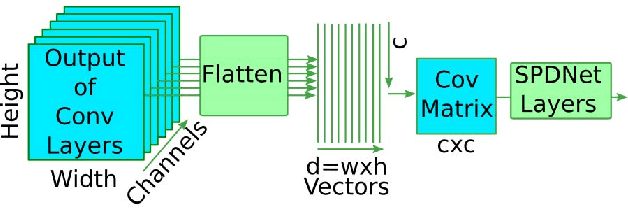
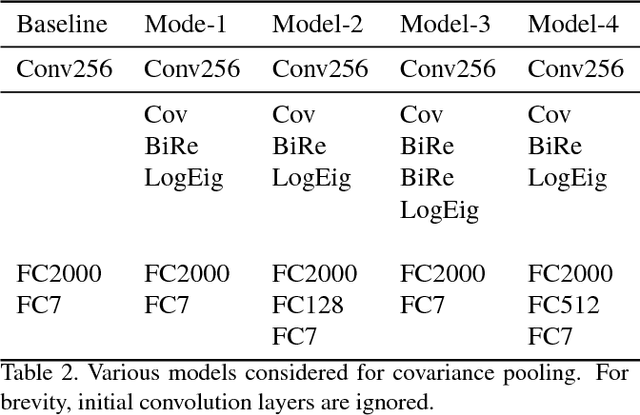
Classifying facial expressions into different categories requires capturing regional distortions of facial landmarks. We believe that second-order statistics such as covariance is better able to capture such distortions in regional facial fea- tures. In this work, we explore the benefits of using a man- ifold network structure for covariance pooling to improve facial expression recognition. In particular, we first employ such kind of manifold networks in conjunction with tradi- tional convolutional networks for spatial pooling within in- dividual image feature maps in an end-to-end deep learning manner. By doing so, we are able to achieve a recognition accuracy of 58.14% on the validation set of Static Facial Expressions in the Wild (SFEW 2.0) and 87.0% on the vali- dation set of Real-World Affective Faces (RAF) Database. Both of these results are the best results we are aware of. Besides, we leverage covariance pooling to capture the tem- poral evolution of per-frame features for video-based facial expression recognition. Our reported results demonstrate the advantage of pooling image-set features temporally by stacking the designed manifold network of covariance pool-ing on top of convolutional network layers.