 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised 2D Image to 3D Shape Translation with Disentangled Representations
Paper and Code



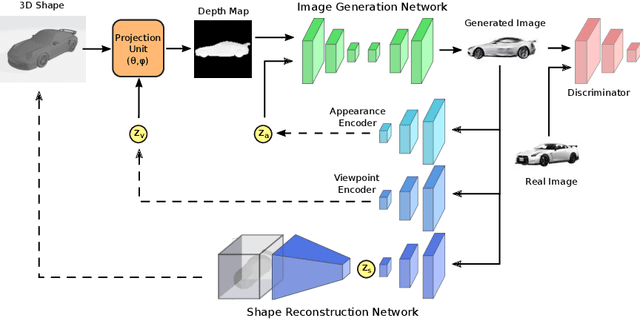
We present a framework to translate between 2D image views and 3D object shapes. Recent progress in deep learning enabled us to learn structure-aware representations from a scene. However, the existing literature assumes that pairs of images and 3D shapes are available for training in full supervision. In this paper, we propose SIST, a Self-supervised Image to Shape Translation framework that fulfills three tasks: (i) reconstructing the 3D shape from a single image; (ii) learning disentangled representations for shape, appearance and viewpoint; and (iii) generating a realistic RGB image from these independent factors. In contrast to the existing approaches, our method does not require image-shape pairs for training. Instead, it uses unpaired image and shape datasets from the same object class and jointly trains image generator and shape reconstruction networks. Our translation method achieves promising results, comparable in quantitative and qualitative terms to the state-of-the-art achieved by fully-supervised methods.