 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Zoning Network: A Unified Principle for Generative Modeling, Representation Learning, and Classification
Sep 19, 2025Generative modeling, representation learning, and classification are three core problems in machine learning (ML), yet their state-of-the-art (SoTA) solutions remain largely disjoint. In this paper, we ask: Can a unified principle address all three? Such unification could simplify ML pipelines and foster greater synergy across tasks. We introduce Latent Zoning Network (LZN) as a step toward this goal. At its core, LZN creates a shared Gaussian latent space that encodes information across all tasks. Each data type (e.g., images, text, labels) is equipped with an encoder that maps samples to disjoint latent zones, and a decoder that maps latents back to data. ML tasks are expressed as compositions of these encoders and decoders: for example, label-conditional image generation uses a label encoder and image decoder; image embedding uses an image encoder; classification uses an image encoder and label decoder. We demonstrate the promise of LZN in three increasingly complex scenarios: (1) LZN can enhance existing models (image generation): When combined with the SoTA Rectified Flow model, LZN improves FID on CIFAR10 from 2.76 to 2.59-without modifying the training objective. (2) LZN can solve tasks independently (representation learning): LZN can implement unsupervised representation learning without auxiliary loss functions, outperforming the seminal MoCo and SimCLR methods by 9.3% and 0.2%, respectively, on downstream linear classification on ImageNet. (3) LZN can solve multiple tasks simultaneously (joint generation and classification): With image and label encoders/decoders, LZN performs both tasks jointly by design, improving FID and achieving SoTA classification accuracy on CIFAR10. The code and trained models are available at https://github.com/microsoft/latent-zoning-networks. The project website is at https://zinanlin.me/blogs/latent_zoning_networks.html.
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
Apr 08, 2024



Diffusion Models (DM) and Consistency Models (CM) are two types of popular generative models with good generation quality on various tasks. When training DM and CM, intermediate weight checkpoints are not fully utilized and only the last converged checkpoint is used. In this work, we find that high-quality model weights often lie in a basin which cannot be reached by SGD but can be obtained by proper checkpoint averaging. Based on these observations, we propose LCSC, a simple but effective and efficient method to enhance the performance of DM and CM, by combining checkpoints along the training trajectory with coefficients deduced from evolutionary search. We demonstrate the value of LCSC through two use cases: $\textbf{(a) Reducing training cost.}$ With LCSC, we only need to train DM/CM with fewer number of iterations and/or lower batch sizes to obtain comparable sample quality with the fully trained model. For example, LCSC achieves considerable training speedups for CM (23$\times$ on CIFAR-10 and 15$\times$ on ImageNet-64). $\textbf{(b) Enhancing pre-trained models.}$ Assuming full training is already done, LCSC can further improve the generation quality or speed of the final converged models. For example, LCSC achieves better performance using 1 number of function evaluation (NFE) than the base model with 2 NFE on consistency distillation, and decreases the NFE of DM from 15 to 9 while maintaining the generation quality on CIFAR-10. Our code is available at https://github.com/imagination-research/LCSC.
Differentially Private Synthetic Data via Foundation Model APIs 2: Text
Mar 04, 2024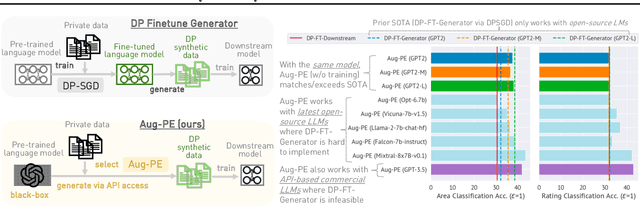
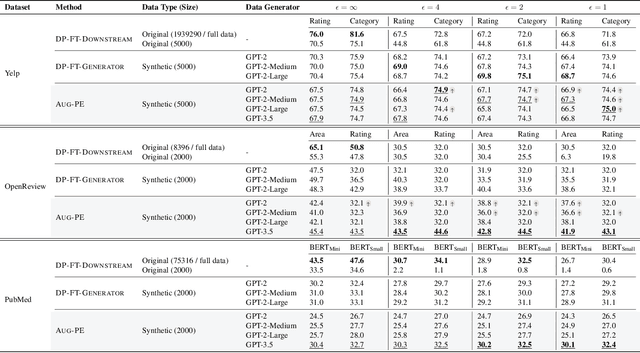
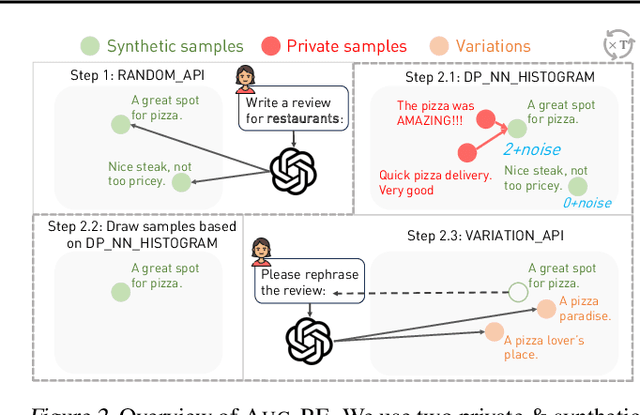
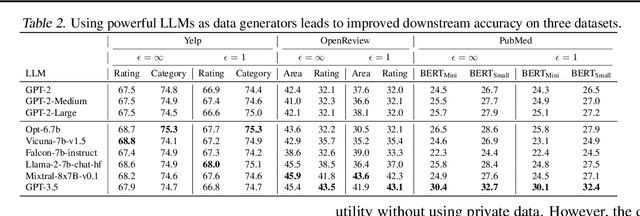
Text data has become extremely valuable due to the emergence of machine learning algorithms that learn from it. A lot of high-quality text data generated in the real world is private and therefore cannot be shared or used freely due to privacy concerns. Generating synthetic replicas of private text data with a formal privacy guarantee, i.e., differential privacy (DP), offers a promising and scalable solution. However, existing methods necessitate DP finetuning of large language models (LLMs) on private data to generate DP synthetic data. This approach is not viable for proprietary LLMs (e.g., GPT-3.5) and also demands considerable computational resources for open-source LLMs. Lin et al. (2024) recently introduced the Private Evolution (PE) algorithm to generate DP synthetic images with only API access to diffusion models. In this work, we propose an augmented PE algorithm, named Aug-PE, that applies to the complex setting of text. We use API access to an LLM and generate DP synthetic text without any model training. We conduct comprehensive experiments on three benchmark datasets. Our results demonstrate that Aug-PE produces DP synthetic text that yields competitive utility with the SOTA DP finetuning baselines. This underscores the feasibility of relying solely on API access of LLMs to produce high-quality DP synthetic texts, thereby facilitating more accessible routes to privacy-preserving LLM applications. Our code and data are available at https://github.com/AI-secure/aug-pe.
Differentially Private Synthetic Data via Foundation Model APIs 1: Images
May 24, 2023

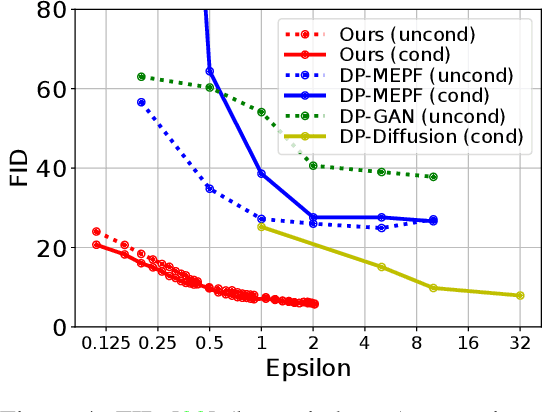

Generating differentially private (DP) synthetic data that closely resembles the original private data without leaking sensitive user information is a scalable way to mitigate privacy concerns in the current data-driven world. In contrast to current practices that train customized models for this task, we aim to generate DP Synthetic Data via APIs (DPSDA), where we treat foundation models as blackboxes and only utilize their inference APIs. Such API-based, training-free approaches are easier to deploy as exemplified by the recent surge in the number of API-based apps. These approaches can also leverage the power of large foundation models which are accessible via their inference APIs while the model weights are unreleased. However, this comes with greater challenges due to strictly more restrictive model access and the additional need to protect privacy from the API provider. In this paper, we present a new framework called Private Evolution (PE) to solve this problem and show its initial promise on synthetic images. Surprisingly, PE can match or even outperform state-of-the-art (SOTA) methods without any model training. For example, on CIFAR10 (with ImageNet as the public data), we achieve FID<=7.9 with privacy cost epsilon=0.67, significantly improving the previous SOTA from epsilon=32. We further demonstrate the promise of applying PE on large foundation models such as Stable Diffusion to tackle challenging private datasets with a small number of high-resolution images.
Differentially Private Fine-tuning of Language Models
Oct 13, 2021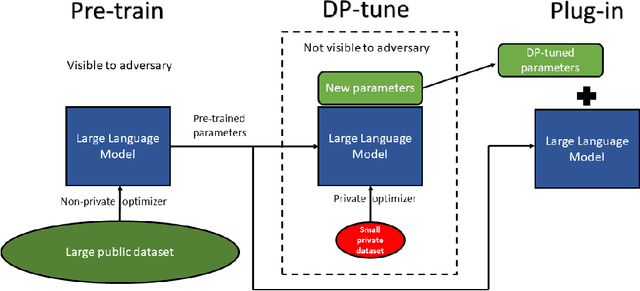


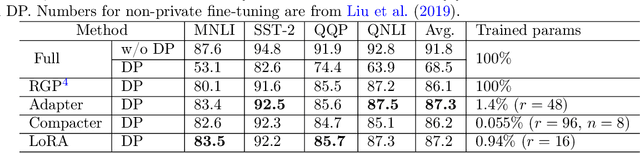
We give simpler, sparser, and faster algorithms for differentially private fine-tuning of large-scale pre-trained language models, which achieve the state-of-the-art privacy versus utility tradeoffs on many standard NLP tasks. We propose a meta-framework for this problem, inspired by the recent success of highly parameter-efficient methods for fine-tuning. Our experiments show that differentially private adaptations of these approaches outperform previous private algorithms in three important dimensions: utility, privacy, and the computational and memory cost of private training. On many commonly studied datasets, the utility of private models approaches that of non-private models. For example, on the MNLI dataset we achieve an accuracy of $87.8\%$ using RoBERTa-Large and $83.5\%$ using RoBERTa-Base with a privacy budget of $\epsilon = 6.7$. In comparison, absent privacy constraints, RoBERTa-Large achieves an accuracy of $90.2\%$. Our findings are similar for natural language generation tasks. Privately fine-tuning with DART, GPT-2-Small, GPT-2-Medium, GPT-2-Large, and GPT-2-XL achieve BLEU scores of 38.5, 42.0, 43.1, and 43.8 respectively (privacy budget of $\epsilon = 6.8,\delta=$ 1e-5) whereas the non-private baseline is $48.1$. All our experiments suggest that larger models are better suited for private fine-tuning: while they are well known to achieve superior accuracy non-privately, we find that they also better maintain their accuracy when privacy is introduced.
Differentially Private n-gram Extraction
Aug 05, 2021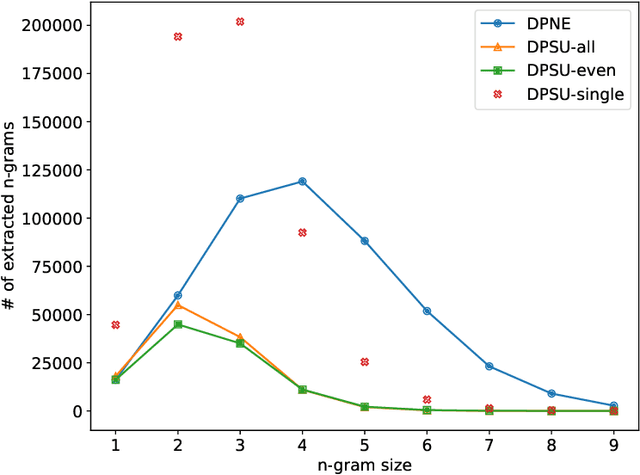


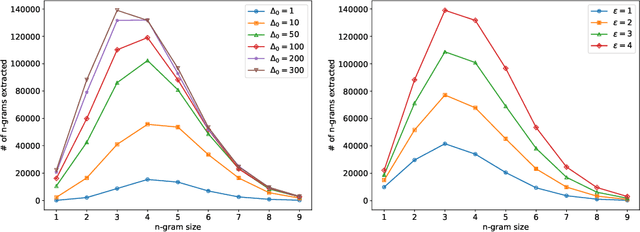
We revisit the problem of $n$-gram extraction in the differential privacy setting. In this problem, given a corpus of private text data, the goal is to release as many $n$-grams as possible while preserving user level privacy. Extracting $n$-grams is a fundamental subroutine in many NLP applications such as sentence completion, response generation for emails etc. The problem also arises in other applications such as sequence mining, and is a generalization of recently studied differentially private set union (DPSU). In this paper, we develop a new differentially private algorithm for this problem which, in our experiments, significantly outperforms the state-of-the-art. Our improvements stem from combining recent advances in DPSU, privacy accounting, and new heuristics for pruning in the tree-based approach initiated by Chen et al. (2012).
Differentially Private Set Union
Feb 22, 2020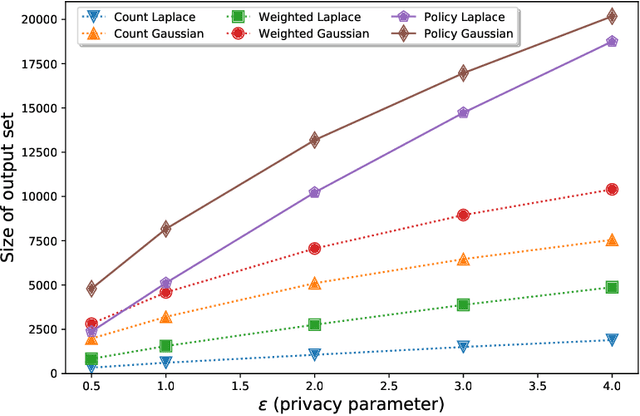



We study the basic operation of set union in the global model of differential privacy. In this problem, we are given a universe $U$ of items, possibly of infinite size, and a database $D$ of users. Each user $i$ contributes a subset $W_i \subseteq U$ of items. We want an ($\epsilon$,$\delta$)-differentially private algorithm which outputs a subset $S \subset \cup_i W_i$ such that the size of $S$ is as large as possible. The problem arises in countless real world applications; it is particularly ubiquitous in natural language processing (NLP) applications as vocabulary extraction. For example, discovering words, sentences, $n$-grams etc., from private text data belonging to users is an instance of the set union problem. Known algorithms for this problem proceed by collecting a subset of items from each user, taking the union of such subsets, and disclosing the items whose noisy counts fall above a certain threshold. Crucially, in the above process, the contribution of each individual user is always independent of the items held by other users, resulting in a wasteful aggregation process, where some item counts happen to be way above the threshold. We deviate from the above paradigm by allowing users to contribute their items in a $\textit{dependent fashion}$, guided by a $\textit{policy}$. In this new setting ensuring privacy is significantly delicate. We prove that any policy which has certain $\textit{contractive}$ properties would result in a differentially private algorithm. We design two new algorithms, one using Laplace noise and other Gaussian noise, as specific instances of policies satisfying the contractive properties. Our experiments show that the new algorithms significantly outperform previously known mechanisms for the problem.