 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Fine-tuning of Language Models
Paper and Code
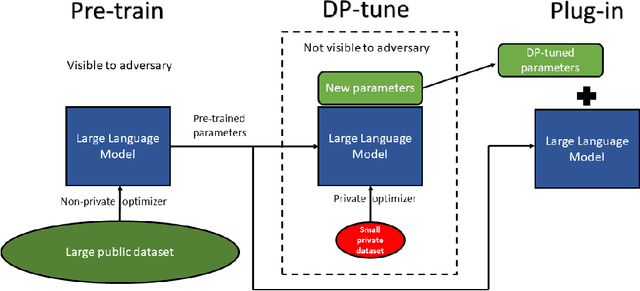


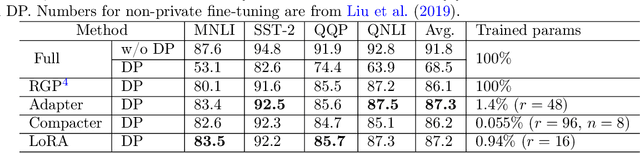
We give simpler, sparser, and faster algorithms for differentially private fine-tuning of large-scale pre-trained language models, which achieve the state-of-the-art privacy versus utility tradeoffs on many standard NLP tasks. We propose a meta-framework for this problem, inspired by the recent success of highly parameter-efficient methods for fine-tuning. Our experiments show that differentially private adaptations of these approaches outperform previous private algorithms in three important dimensions: utility, privacy, and the computational and memory cost of private training. On many commonly studied datasets, the utility of private models approaches that of non-private models. For example, on the MNLI dataset we achieve an accuracy of $87.8\%$ using RoBERTa-Large and $83.5\%$ using RoBERTa-Base with a privacy budget of $\epsilon = 6.7$. In comparison, absent privacy constraints, RoBERTa-Large achieves an accuracy of $90.2\%$. Our findings are similar for natural language generation tasks. Privately fine-tuning with DART, GPT-2-Small, GPT-2-Medium, GPT-2-Large, and GPT-2-XL achieve BLEU scores of 38.5, 42.0, 43.1, and 43.8 respectively (privacy budget of $\epsilon = 6.8,\delta=$ 1e-5) whereas the non-private baseline is $48.1$. All our experiments suggest that larger models are better suited for private fine-tuning: while they are well known to achieve superior accuracy non-privately, we find that they also better maintain their accuracy when privacy is introduced.