 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Pre-training for Private Fine-tuning
May 23, 2023



Suppose we want to train text prediction models in email clients or word processors. The models must preserve the privacy of user data and adhere to a specific fixed size to meet memory and inference time requirements. We introduce a generic framework to solve this problem. Specifically, we are given a public dataset $D_\text{pub}$ and a private dataset $D_\text{priv}$ corresponding to a downstream task $T$. How should we pre-train a fixed-size model $M$ on $D_\text{pub}$ and fine-tune it on $D_\text{priv}$ such that performance of $M$ with respect to $T$ is maximized and $M$ satisfies differential privacy with respect to $D_\text{priv}$? We show that pre-training on a {\em subset} of dataset $D_\text{pub}$ that brings the public distribution closer to the private distribution is a crucial ingredient to maximize the transfer learning abilities of $M$ after pre-training, especially in the regimes where model sizes are relatively small. Besides performance improvements, our framework also shows that with careful pre-training and private fine-tuning, {\em smaller models} can match the performance of much larger models, highlighting the promise of differentially private training as a tool for model compression and efficiency.
Planting and Mitigating Memorized Content in Predictive-Text Language Models
Dec 16, 2022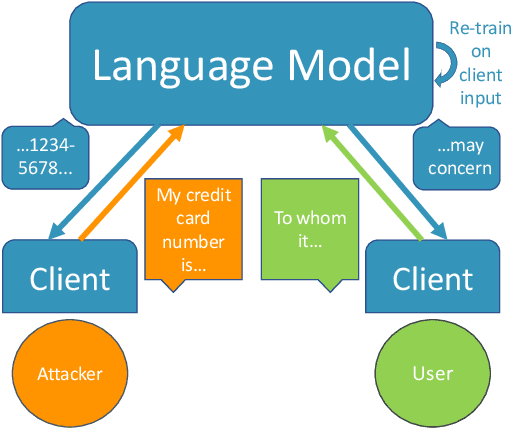
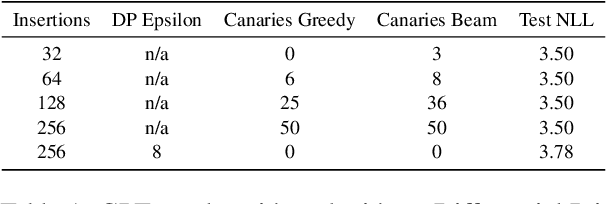
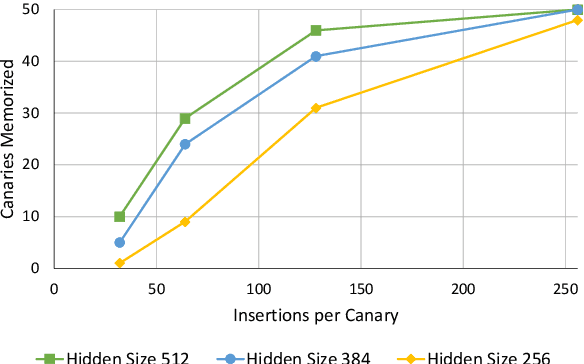
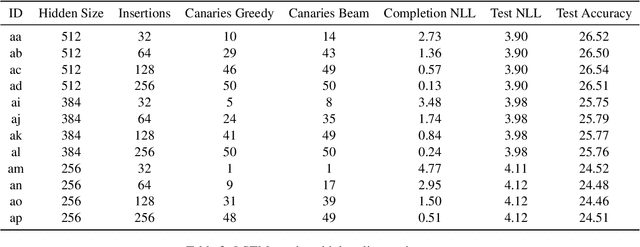
Language models are widely deployed to provide automatic text completion services in user products. However, recent research has revealed that language models (especially large ones) bear considerable risk of memorizing private training data, which is then vulnerable to leakage and extraction by adversaries. In this study, we test the efficacy of a range of privacy-preserving techniques to mitigate unintended memorization of sensitive user text, while varying other factors such as model size and adversarial conditions. We test both "heuristic" mitigations (those without formal privacy guarantees) and Differentially Private training, which provides provable levels of privacy at the cost of some model performance. Our experiments show that (with the exception of L2 regularization), heuristic mitigations are largely ineffective in preventing memorization in our test suite, possibly because they make too strong of assumptions about the characteristics that define "sensitive" or "private" text. In contrast, Differential Privacy reliably prevents memorization in our experiments, despite its computational and model-performance costs.
Differentially Private Fine-tuning of Language Models
Oct 13, 2021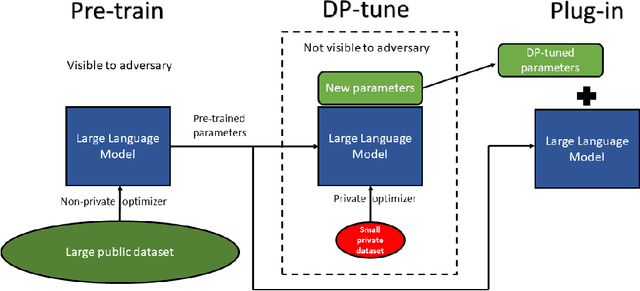


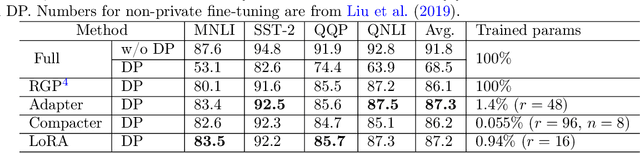
We give simpler, sparser, and faster algorithms for differentially private fine-tuning of large-scale pre-trained language models, which achieve the state-of-the-art privacy versus utility tradeoffs on many standard NLP tasks. We propose a meta-framework for this problem, inspired by the recent success of highly parameter-efficient methods for fine-tuning. Our experiments show that differentially private adaptations of these approaches outperform previous private algorithms in three important dimensions: utility, privacy, and the computational and memory cost of private training. On many commonly studied datasets, the utility of private models approaches that of non-private models. For example, on the MNLI dataset we achieve an accuracy of $87.8\%$ using RoBERTa-Large and $83.5\%$ using RoBERTa-Base with a privacy budget of $\epsilon = 6.7$. In comparison, absent privacy constraints, RoBERTa-Large achieves an accuracy of $90.2\%$. Our findings are similar for natural language generation tasks. Privately fine-tuning with DART, GPT-2-Small, GPT-2-Medium, GPT-2-Large, and GPT-2-XL achieve BLEU scores of 38.5, 42.0, 43.1, and 43.8 respectively (privacy budget of $\epsilon = 6.8,\delta=$ 1e-5) whereas the non-private baseline is $48.1$. All our experiments suggest that larger models are better suited for private fine-tuning: while they are well known to achieve superior accuracy non-privately, we find that they also better maintain their accuracy when privacy is introduced.