 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanting and Mitigating Memorized Content in Predictive-Text Language Models
Dec 16, 2022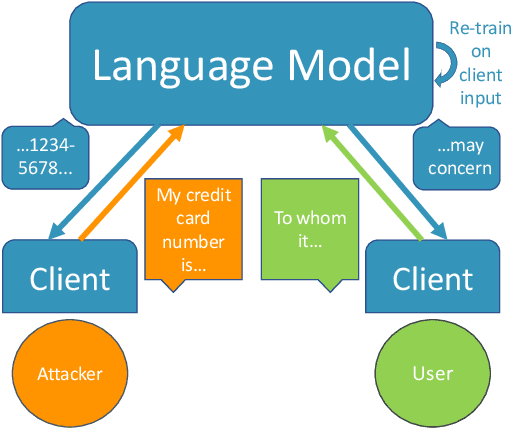
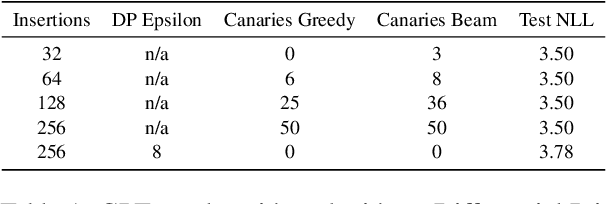
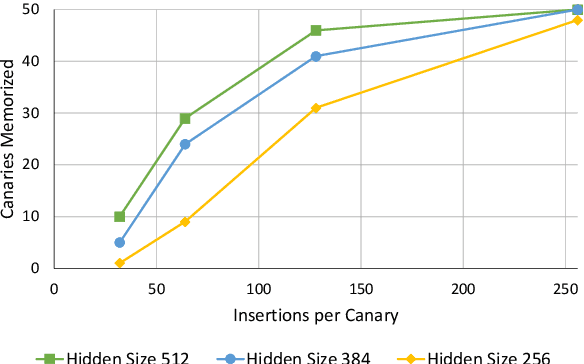
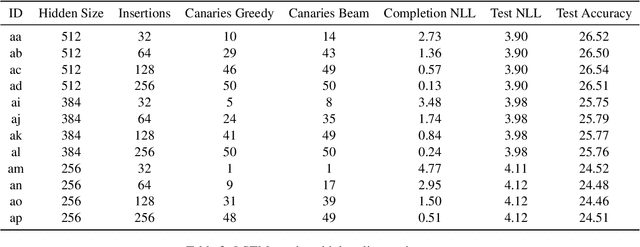
Language models are widely deployed to provide automatic text completion services in user products. However, recent research has revealed that language models (especially large ones) bear considerable risk of memorizing private training data, which is then vulnerable to leakage and extraction by adversaries. In this study, we test the efficacy of a range of privacy-preserving techniques to mitigate unintended memorization of sensitive user text, while varying other factors such as model size and adversarial conditions. We test both "heuristic" mitigations (those without formal privacy guarantees) and Differentially Private training, which provides provable levels of privacy at the cost of some model performance. Our experiments show that (with the exception of L2 regularization), heuristic mitigations are largely ineffective in preventing memorization in our test suite, possibly because they make too strong of assumptions about the characteristics that define "sensitive" or "private" text. In contrast, Differential Privacy reliably prevents memorization in our experiments, despite its computational and model-performance costs.
Trustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation
Dec 27, 2019
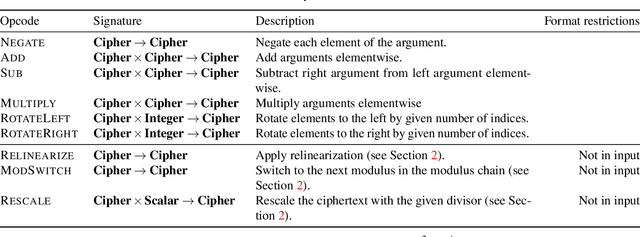
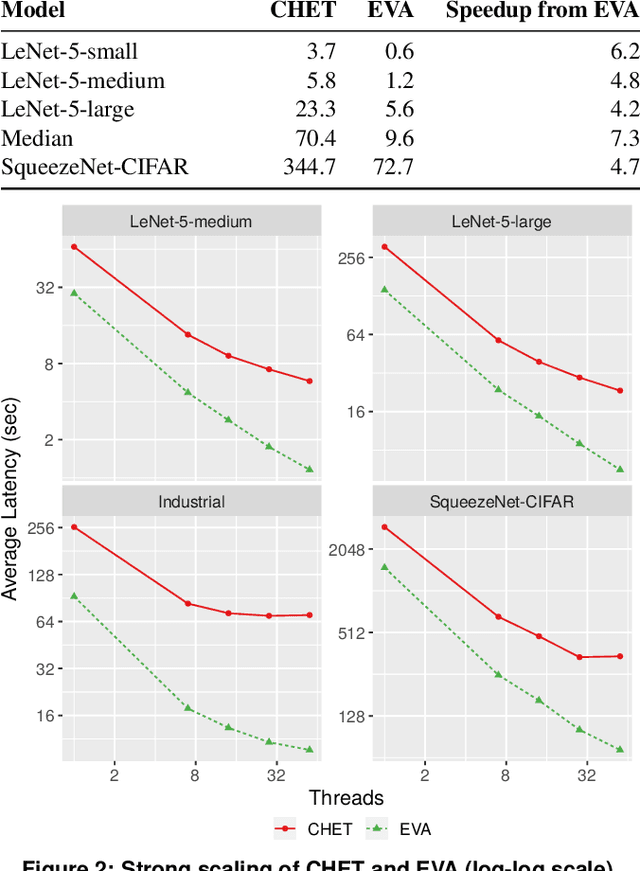
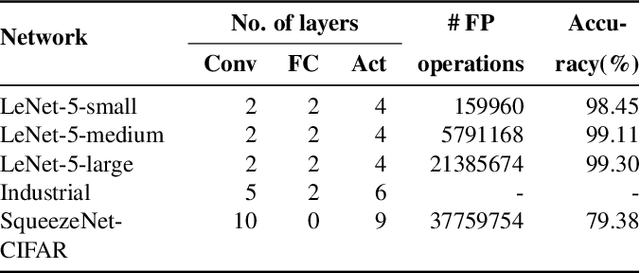
Fully-Homomorphic Encryption (FHE) offers powerful capabilities by enabling secure offloading of both storage and computation, and recent innovations in schemes and implementation have made it all the more attractive. At the same time, FHE is notoriously hard to use with a very constrained programming model, a very unusual performance profile, and many cryptographic constraints. Existing compilers for FHE either target simpler but less efficient FHE schemes or only support specific domains where they can rely on expert provided high-level runtimes to hide complications. This paper presents a new FHE language called Encrypted Vector Arithmetic (EVA), which includes an optimizing compiler that generates correct and secure FHE programs, while hiding all the complexities of the target FHE scheme. Bolstered by our optimizing compiler, programmers can develop efficient general purpose FHE applications directly in EVA. For example, we have developed image processing applications using EVA, with very few lines of code. EVA is designed to also work as an intermediate representation that can be a target for compiling higher-level domain-specific languages. To demonstrate this we have re-targeted CHET, an existing domain-specific compiler for neural network inference, onto EVA. Due to the novel optimizations in EVA, its programs are on average 5.3x faster than those generated by CHET. We believe EVA would enable a wider adoption of FHE by making it easier to develop FHE applications and domain-specific FHE compilers.
HEAX: High-Performance Architecture for Computation on Homomorphically Encrypted Data in the Cloud
Sep 20, 2019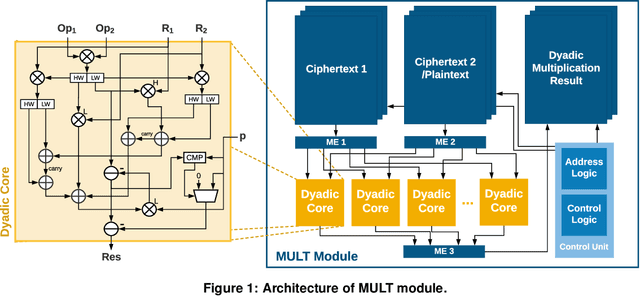
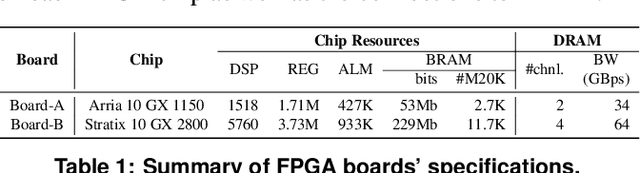
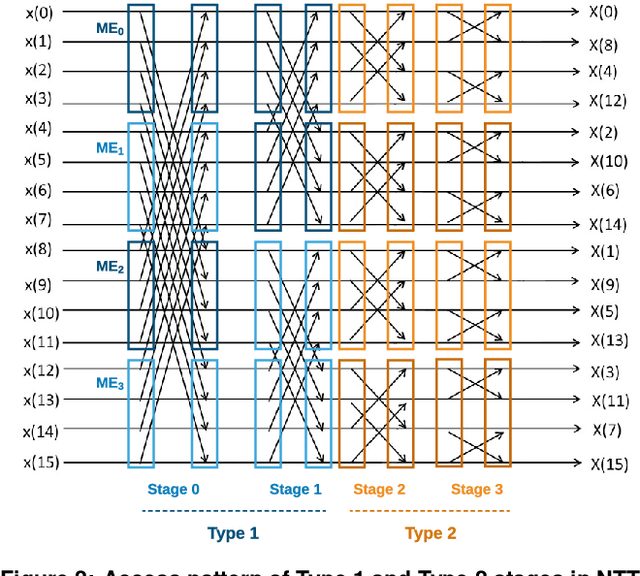

With the rapid increase in cloud computing, concerns surrounding data privacy, security, and confidentiality also have been increased significantly. Not only cloud providers are susceptible to internal and external hacks, but also in some scenarios, data owners cannot outsource the computation due to privacy laws such as GDPR, HIPAA, or CCPA. Fully Homomorphic Encryption (FHE) is a groundbreaking invention in cryptography that, unlike traditional cryptosystems, enables computation on encrypted data without ever decrypting it. However, the most critical obstacle in deploying FHE at large-scale is the enormous computation overhead. In this paper, we present HEAX, a novel hardware architecture for FHE that achieves unprecedented performance improvement. HEAX leverages multiple levels of parallelism, ranging from ciphertext-level to fine-grained modular arithmetic level. Our first contribution is a new highly-parallelizable architecture for number-theoretic transform (NTT) which can be of independent interest as NTT is frequently used in many lattice-based cryptography systems. Building on top of NTT engine, we design a novel architecture for computation on homomorphically encrypted data. We also introduce several techniques to enable an end-to-end, fully pipelined design as well as reducing on-chip memory consumption. Our implementation on reconfigurable hardware demonstrates 164-268x performance improvement for a wide range of FHE parameters.
PrivFT: Private and Fast Text Classification with Homomorphic Encryption
Aug 19, 2019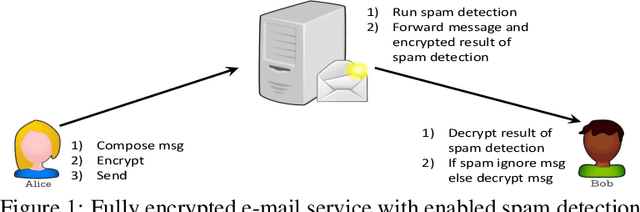

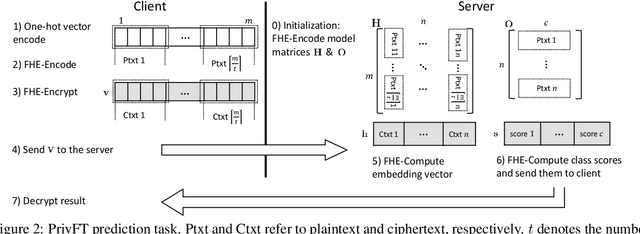
Privacy and security have increasingly become a concern for computing services in recent years. In this work, we present an efficient method for Text Classification while preserving the privacy of the content, using Fully Homomorphic Encryption (FHE). We train a simple supervised model on unencrypted data to achieve competitive results with recent approaches and outline a system for performing inferences directly on encrypted data with zero loss to prediction accuracy. This system is implemented with GPU hardware acceleration to achieve a run time per inference of less than 0.66 seconds, resulting in more than 12$\times$ speedup over its CPU counterpart. Finally, we show how to train this model from scratch using fully encrypted data to generate an encrypted model.
CHET: Compiler and Runtime for Homomorphic Evaluation of Tensor Programs
Oct 01, 2018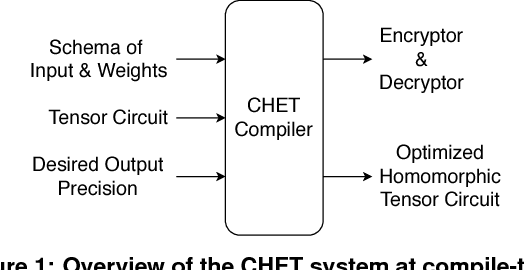
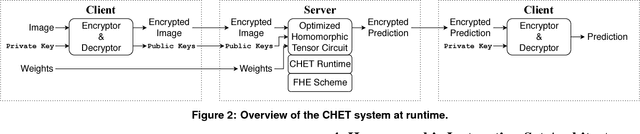
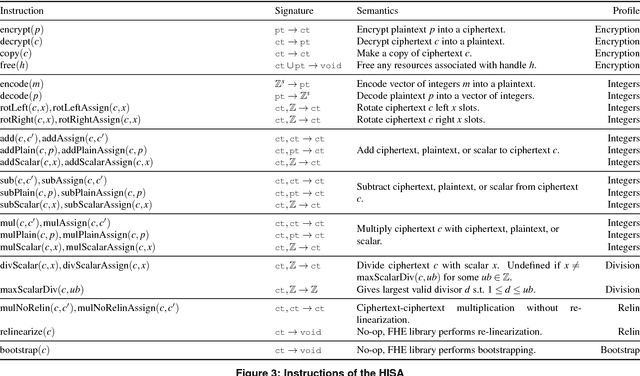
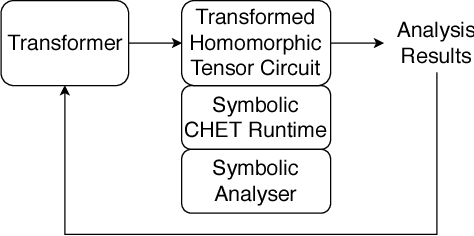
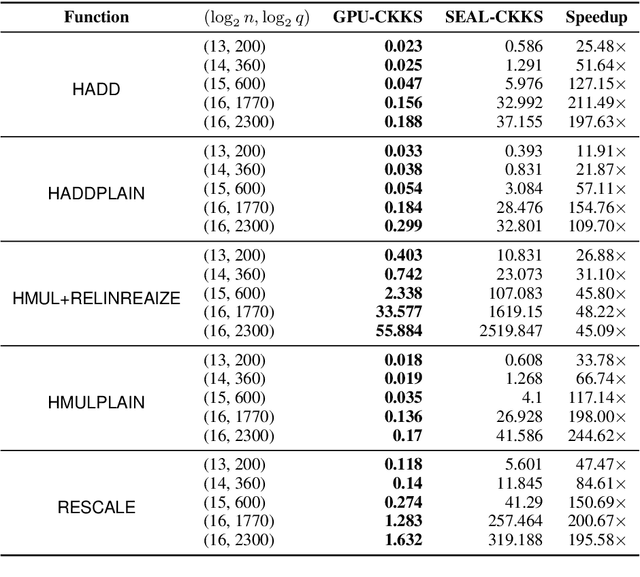
Fully Homomorphic Encryption (FHE) refers to a set of encryption schemes that allow computations to be applied directly on encrypted data without requiring a secret key. This enables novel application scenarios where a client can safely offload storage and computation to a third-party cloud provider without having to trust the software and the hardware vendors with the decryption keys. Recent advances in both FHE schemes and implementations have moved such applications from theoretical possibilities into the realm of practicalities. This paper proposes a compact and well-reasoned interface called the Homomorphic Instruction Set Architecture (HISA) for developing FHE applications. Just as the hardware ISA interface enabled hardware advances to proceed independent of software advances in the compiler and language runtimes, HISA decouples compiler optimizations and runtimes for supporting FHE applications from advancements in the underlying FHE schemes. This paper demonstrates the capabilities of HISA by building an end-to-end software stack for evaluating neural network models on encrypted data. Our stack includes an end-to-end compiler, runtime, and a set of optimizations. Our approach shows generated code, on a set of popular neural network architectures, is faster than hand-optimized implementations.