 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
MaskedNet: The First Hardware Inference Engine Aiming Power Side-Channel Protection
Dec 02, 2019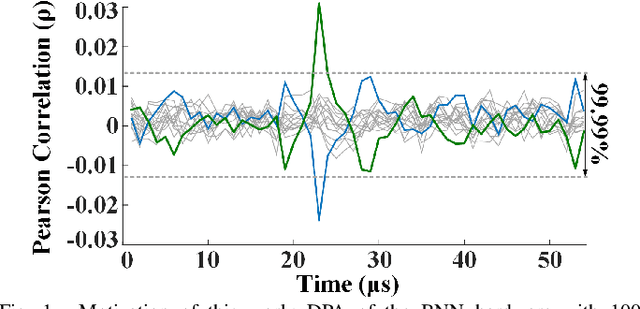
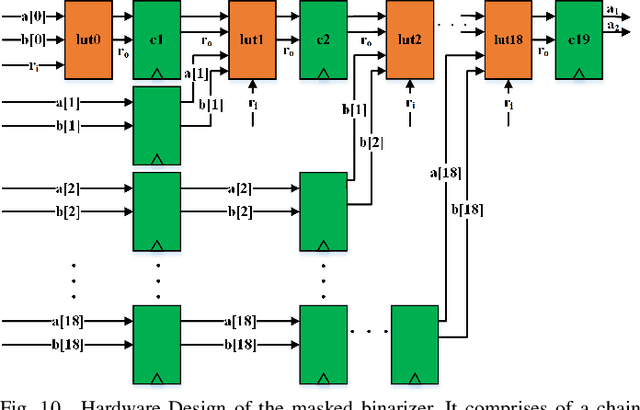
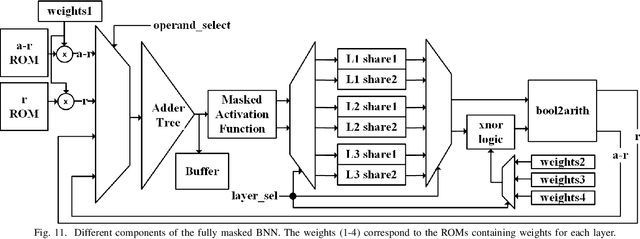
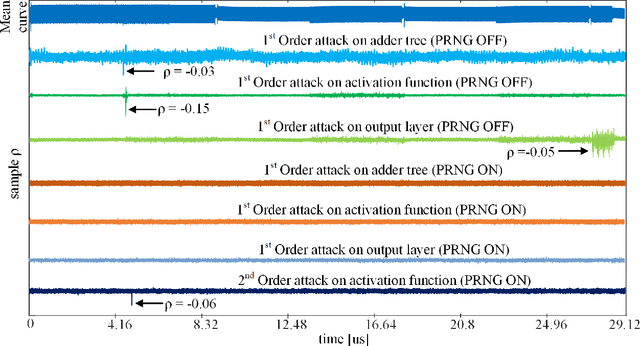
Differential Power Analysis (DPA) has been an active area of research for the past two decades to study the attacks for extracting secret information from cryptographic implementations through power measurements and their defenses. Unfortunately, the research on power side-channels have so far predominantly focused on analyzing implementations of ciphers such as AES, DES, RSA, and recently post-quantum cryptography primitives (e.g., lattices). Meanwhile, machine-learning, and in particular deep-learning applications are becoming ubiquitous with several scenarios where the Machine Learning Models are Intellectual Properties requiring confidentiality. Expanding side-channel analysis to Machine Learning Model extraction, however, is largely unexplored. This paper expands the DPA framework to neural-network classifiers. First, it shows DPA attacks during inference to extract the secret model parameters such as weights and biases of a neural network. Second, it proposes the $\textit{first countermeasures}$ against these attacks by augmenting $\textit{masking}$. The resulting design uses novel masked components such as masked adder trees for fully-connected layers and masked Rectifier Linear Units for activation functions. On a SAKURA-X FPGA board, experiments show that the first-order DPA attacks on the unprotected implementation can succeed with only 200 traces and our protection respectively increases the latency and area-cost by 2.8x and 2.3x.