 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyFL: A Hybrid Approach For Private Federated Learning
Feb 20, 2023



As a distributed machine learning paradigm, federated learning (FL) conveys a sense of privacy to contributing participants because training data never leaves their devices. However, gradient updates and the aggregated model still reveal sensitive information. In this work, we propose HyFL, a new framework that combines private training and inference with secure aggregation and hierarchical FL to provide end-to-end protection and facilitate large-scale global deployments. Additionally, we show that HyFL strictly limits the attack surface for malicious participants: they are restricted to data-poisoning attacks and cannot significantly reduce accuracy.
ScionFL: Secure Quantized Aggregation for Federated Learning
Oct 13, 2022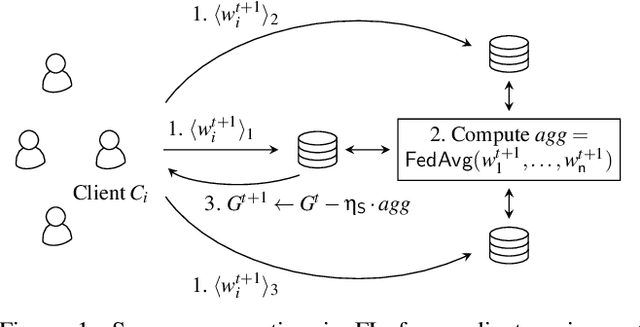
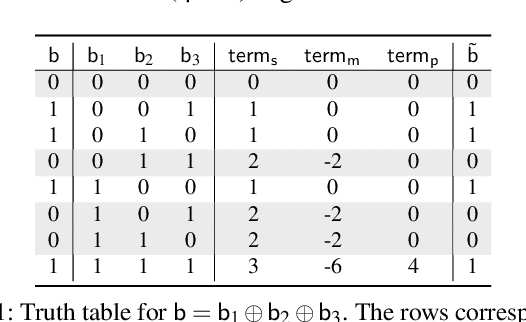

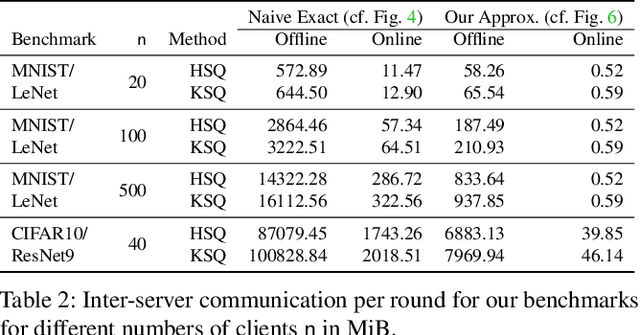
Privacy concerns in federated learning (FL) are commonly addressed with secure aggregation schemes that prevent a central party from observing plaintext client updates. However, most such schemes neglect orthogonal FL research that aims at reducing communication between clients and the aggregator and is instrumental in facilitating cross-device FL with thousands and even millions of (mobile) participants. In particular, quantization techniques can typically reduce client-server communication by a factor of 32x. In this paper, we unite both research directions by introducing an efficient secure aggregation framework based on outsourced multi-party computation (MPC) that supports any linear quantization scheme. Specifically, we design a novel approximate version of an MPC-based secure aggregation protocol with support for multiple stochastic quantization schemes, including ones that utilize the randomized Hadamard transform and Kashin's representation. In our empirical performance evaluation, we show that with no additional overhead for clients and moderate inter-server communication, we achieve similar training accuracy as insecure schemes for standard FL benchmarks. Beyond this, we present an efficient extension to our secure quantized aggregation framework that effectively defends against state-of-the-art untargeted poisoning attacks.
Trustworthy AI Inference Systems: An Industry Research View
Aug 10, 2020In this work, we provide an industry research view for approaching the design, deployment, and operation of trustworthy Artificial Intelligence (AI) inference systems. Such systems provide customers with timely, informed, and customized inferences to aid their decision, while at the same time utilizing appropriate security protection mechanisms for AI models. Additionally, such systems should also use Privacy-Enhancing Technologies (PETs) to protect customers' data at any time. To approach the subject, we start by introducing trends in AI inference systems. We continue by elaborating on the relationship between Intellectual Property (IP) and private data protection in such systems. Regarding the protection mechanisms, we survey the security and privacy building blocks instrumental in designing, building, deploying, and operating private AI inference systems. For example, we highlight opportunities and challenges in AI systems using trusted execution environments combined with more recent advances in cryptographic techniques to protect data in use. Finally, we outline areas of further development that require the global collective attention of industry, academia, and government researchers to sustain the operation of trustworthy AI inference systems.
CryptoSPN: Privacy-preserving Sum-Product Network Inference
Feb 03, 2020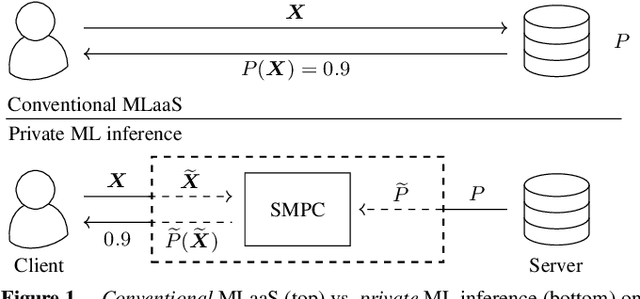
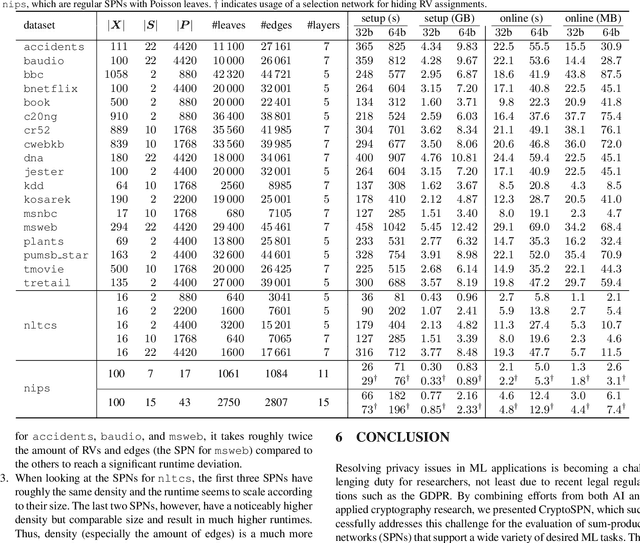
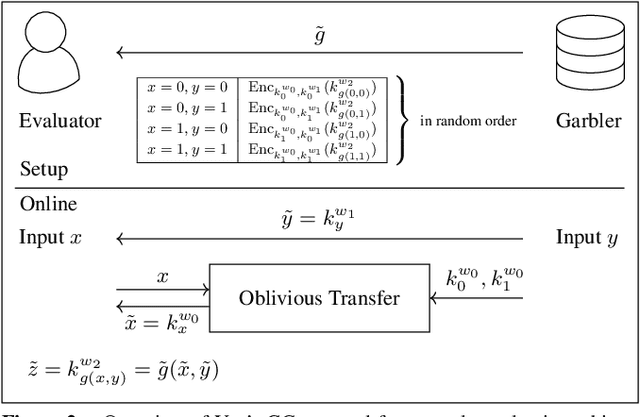
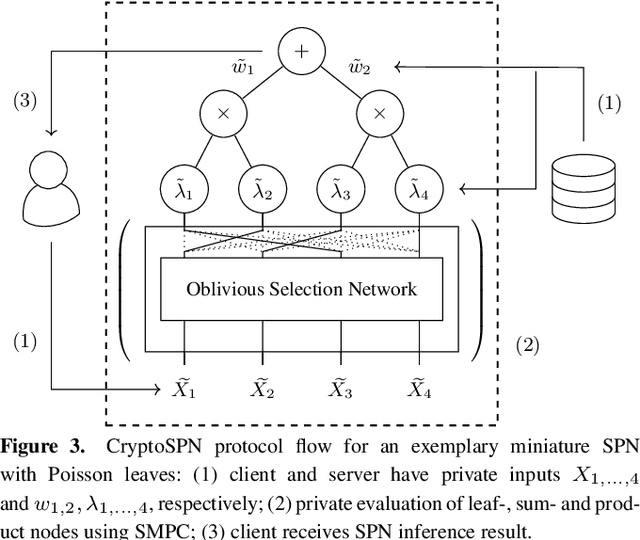
AI algorithms, and machine learning (ML) techniques in particular, are increasingly important to individuals' lives, but have caused a range of privacy concerns addressed by, e.g., the European GDPR. Using cryptographic techniques, it is possible to perform inference tasks remotely on sensitive client data in a privacy-preserving way: the server learns nothing about the input data and the model predictions, while the client learns nothing about the ML model (which is often considered intellectual property and might contain traces of sensitive data). While such privacy-preserving solutions are relatively efficient, they are mostly targeted at neural networks, can degrade the predictive accuracy, and usually reveal the network's topology. Furthermore, existing solutions are not readily accessible to ML experts, as prototype implementations are not well-integrated into ML frameworks and require extensive cryptographic knowledge. In this paper, we present CryptoSPN, a framework for privacy-preserving inference of sum-product networks (SPNs). SPNs are a tractable probabilistic graphical model that allows a range of exact inference queries in linear time. Specifically, we show how to efficiently perform SPN inference via secure multi-party computation (SMPC) without accuracy degradation while hiding sensitive client and training information with provable security guarantees. Next to foundations, CryptoSPN encompasses tools to easily transform existing SPNs into privacy-preserving executables. Our empirical results demonstrate that CryptoSPN achieves highly efficient and accurate inference in the order of seconds for medium-sized SPNs.
Chameleon: A Hybrid Secure Computation Framework for Machine Learning Applications
Jan 10, 2018
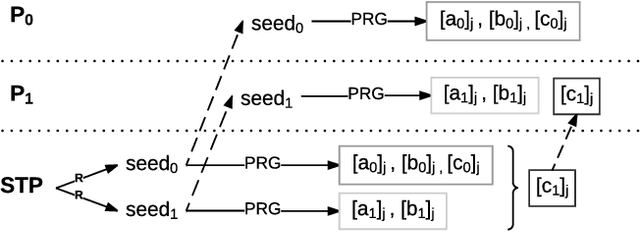

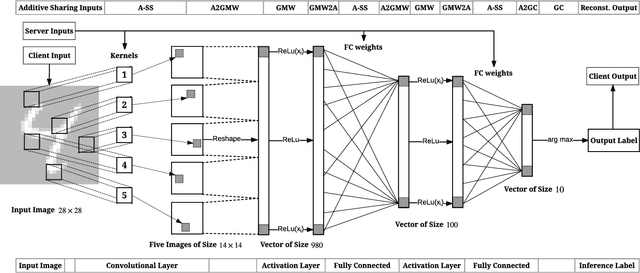
We present Chameleon, a novel hybrid (mixed-protocol) framework for secure function evaluation (SFE) which enables two parties to jointly compute a function without disclosing their private inputs. Chameleon combines the best aspects of generic SFE protocols with the ones that are based upon additive secret sharing. In particular, the framework performs linear operations in the ring $\mathbb{Z}_{2^l}$ using additively secret shared values and nonlinear operations using Yao's Garbled Circuits or the Goldreich-Micali-Wigderson protocol. Chameleon departs from the common assumption of additive or linear secret sharing models where three or more parties need to communicate in the online phase: the framework allows two parties with private inputs to communicate in the online phase under the assumption of a third node generating correlated randomness in an offline phase. Almost all of the heavy cryptographic operations are precomputed in an offline phase which substantially reduces the communication overhead. Chameleon is both scalable and significantly more efficient than the ABY framework (NDSS'15) it is based on. Our framework supports signed fixed-point numbers. In particular, Chameleon's vector dot product of signed fixed-point numbers improves the efficiency of mining and classification of encrypted data for algorithms based upon heavy matrix multiplications. Our evaluation of Chameleon on a 5 layer convolutional deep neural network shows 133x and 4.2x faster executions than Microsoft CryptoNets (ICML'16) and MiniONN (CCS'17), respectively.