 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScionFL: Secure Quantized Aggregation for Federated Learning
Oct 13, 2022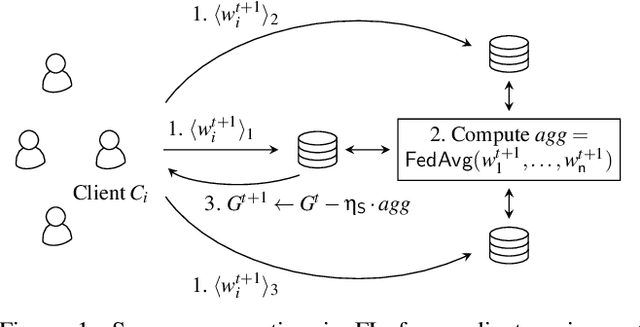

Privacy concerns in federated learning (FL) are commonly addressed with secure aggregation schemes that prevent a central party from observing plaintext client updates. However, most such schemes neglect orthogonal FL research that aims at reducing communication between clients and the aggregator and is instrumental in facilitating cross-device FL with thousands and even millions of (mobile) participants. In particular, quantization techniques can typically reduce client-server communication by a factor of 32x. In this paper, we unite both research directions by introducing an efficient secure aggregation framework based on outsourced multi-party computation (MPC) that supports any linear quantization scheme. Specifically, we design a novel approximate version of an MPC-based secure aggregation protocol with support for multiple stochastic quantization schemes, including ones that utilize the randomized Hadamard transform and Kashin's representation. In our empirical performance evaluation, we show that with no additional overhead for clients and moderate inter-server communication, we achieve similar training accuracy as insecure schemes for standard FL benchmarks. Beyond this, we present an efficient extension to our secure quantized aggregation framework that effectively defends against state-of-the-art untargeted poisoning attacks.
Fairness in the Eyes of the Data: Certifying Machine-Learning Models
Sep 03, 2020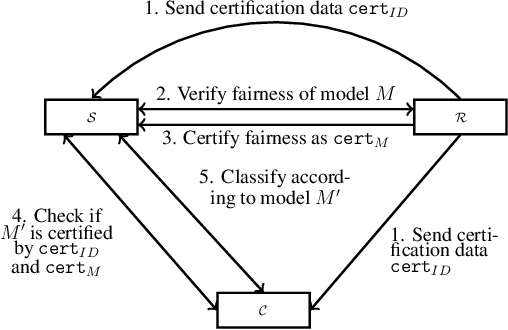

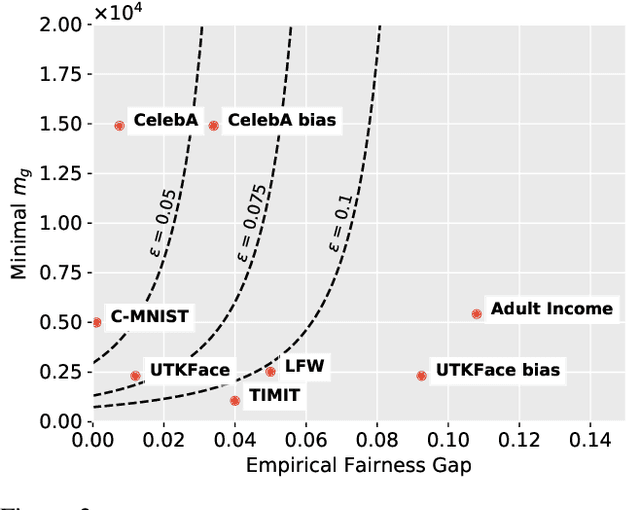
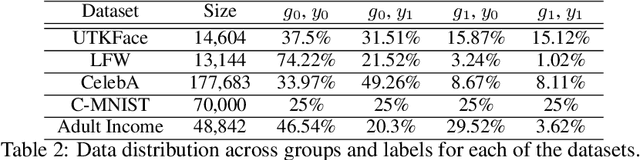
We present a framework that allows to certify the fairness degree of a model based on an interactive and privacy-preserving test. The framework verifies any trained model, regardless of its training process and architecture. Thus, it allows us to evaluate any deep learning model on multiple fairness definitions empirically. We tackle two scenarios, where either the test data is privately available only to the tester or is publicly known in advance, even to the model creator. We investigate the soundness of the proposed approach using theoretical analysis and present statistical guarantees for the interactive test. Finally, we provide a cryptographic technique to automate fairness testing and certified inference with only black-box access to the model at hand while hiding the participants' sensitive data.
Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring
Jun 11, 2018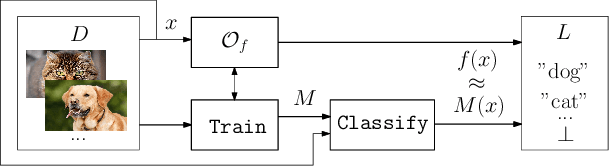
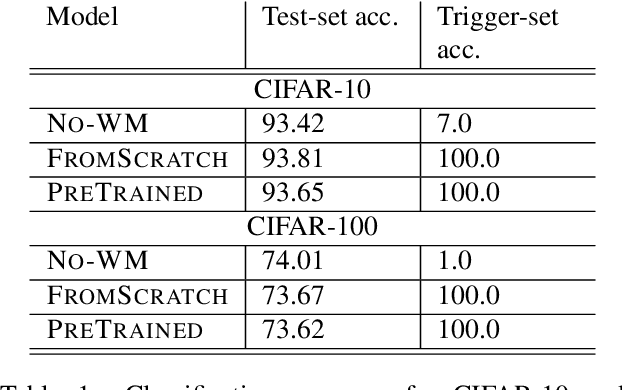
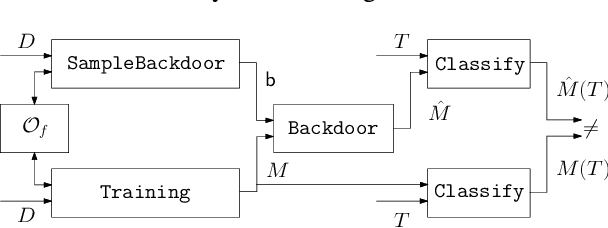

Deep Neural Networks have recently gained lots of success after enabling several breakthroughs in notoriously challenging problems. Training these networks is computationally expensive and requires vast amounts of training data. Selling such pre-trained models can, therefore, be a lucrative business model. Unfortunately, once the models are sold they can be easily copied and redistributed. To avoid this, a tracking mechanism to identify models as the intellectual property of a particular vendor is necessary. In this work, we present an approach for watermarking Deep Neural Networks in a black-box way. Our scheme works for general classification tasks and can easily be combined with current learning algorithms. We show experimentally that such a watermark has no noticeable impact on the primary task that the model is designed for and evaluate the robustness of our proposal against a multitude of practical attacks. Moreover, we provide a theoretical analysis, relating our approach to previous work on backdooring.
Deceiving End-to-End Deep Learning Malware Detectors using Adversarial Examples
May 13, 2018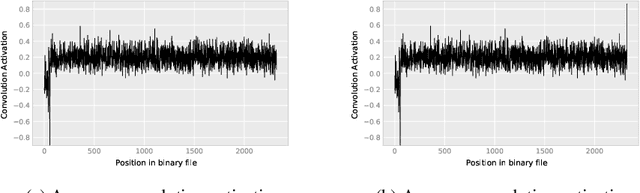
In recent years, deep learning has shown performance breakthroughs in many applications, such as image detection, image segmentation, pose estimation, and speech recognition. However, this comes with a major concern: deep networks have been found to be vulnerable to adversarial examples. Adversarial examples are slightly modified inputs that are intentionally designed to cause a misclassification by the model. In the domains of images and speech, the modifications are so small that they are not seen or heard by humans, but nevertheless greatly affect the classification of the model. Deep learning models have been successfully applied to malware detection. In this domain, generating adversarial examples is not straightforward, as small modifications to the bytes of the file could lead to significant changes in its functionality and validity. We introduce a novel loss function for generating adversarial examples specifically tailored for discrete input sets, such as executable bytes. We modify malicious binaries so that they would be detected as benign, while preserving their original functionality, by injecting a small sequence of bytes (payload) in the binary file. We applied this approach to an end-to-end convolutional deep learning malware detection model and show a high rate of detection evasion. Moreover, we show that our generated payload is robust enough to be transferable within different locations of the same file and across different files, and that its entropy is low and similar to that of benign data sections.