 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Multi-Armed Bandits with Unrestricted Delay Distributions
Jun 04, 2021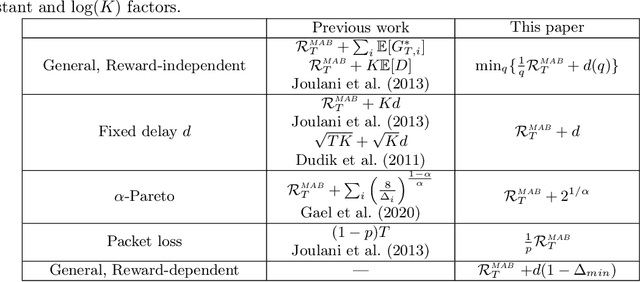
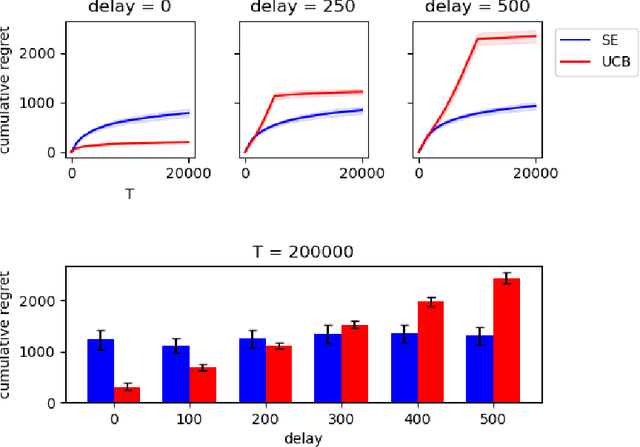
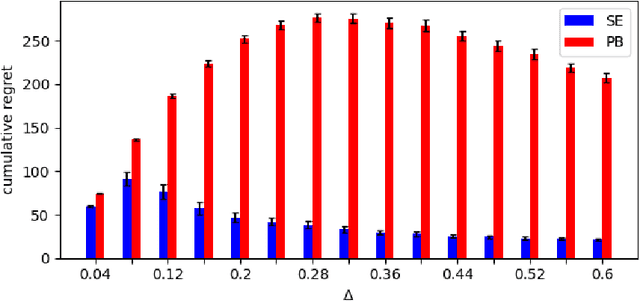
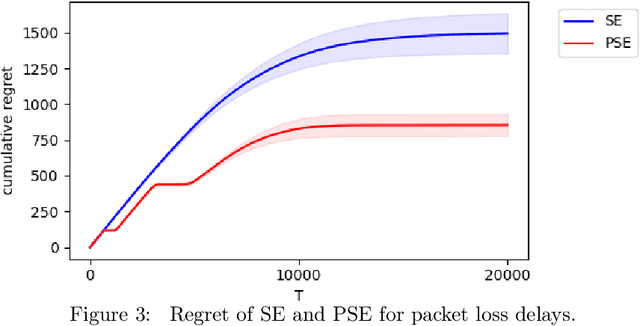
We study the stochastic Multi-Armed Bandit (MAB) problem with random delays in the feedback received by the algorithm. We consider two settings: the reward-dependent delay setting, where realized delays may depend on the stochastic rewards, and the reward-independent delay setting. Our main contribution is algorithms that achieve near-optimal regret in each of the settings, with an additional additive dependence on the quantiles of the delay distribution. Our results do not make any assumptions on the delay distributions: in particular, we do not assume they come from any parametric family of distributions and allow for unbounded support and expectation; we further allow for infinite delays where the algorithm might occasionally not observe any feedback.
Fairness in the Eyes of the Data: Certifying Machine-Learning Models
Sep 03, 2020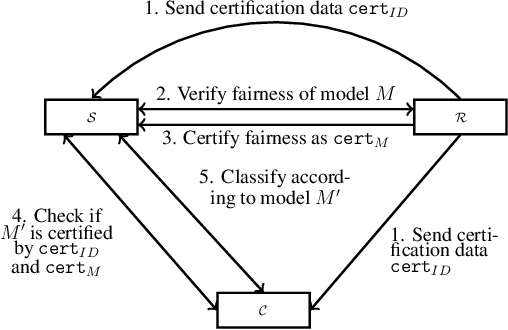

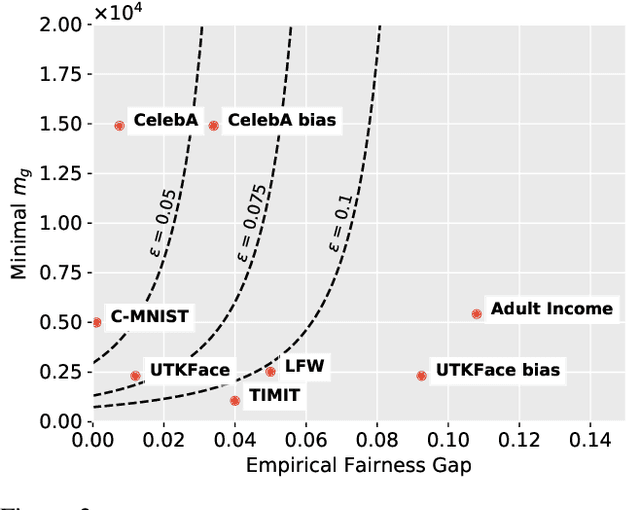
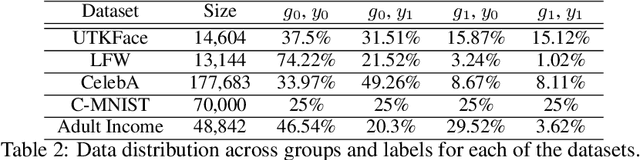
We present a framework that allows to certify the fairness degree of a model based on an interactive and privacy-preserving test. The framework verifies any trained model, regardless of its training process and architecture. Thus, it allows us to evaluate any deep learning model on multiple fairness definitions empirically. We tackle two scenarios, where either the test data is privately available only to the tester or is publicly known in advance, even to the model creator. We investigate the soundness of the proposed approach using theoretical analysis and present statistical guarantees for the interactive test. Finally, we provide a cryptographic technique to automate fairness testing and certified inference with only black-box access to the model at hand while hiding the participants' sensitive data.