 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in the Eyes of the Data: Certifying Machine-Learning Models
Sep 03, 2020

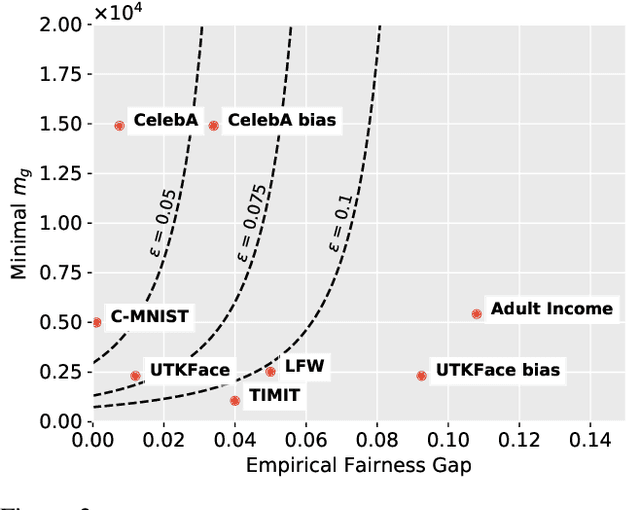
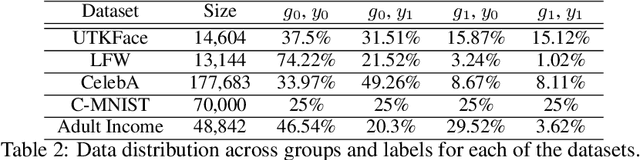
We present a framework that allows to certify the fairness degree of a model based on an interactive and privacy-preserving test. The framework verifies any trained model, regardless of its training process and architecture. Thus, it allows us to evaluate any deep learning model on multiple fairness definitions empirically. We tackle two scenarios, where either the test data is privately available only to the tester or is publicly known in advance, even to the model creator. We investigate the soundness of the proposed approach using theoretical analysis and present statistical guarantees for the interactive test. Finally, we provide a cryptographic technique to automate fairness testing and certified inference with only black-box access to the model at hand while hiding the participants' sensitive data.
Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring
Jun 11, 2018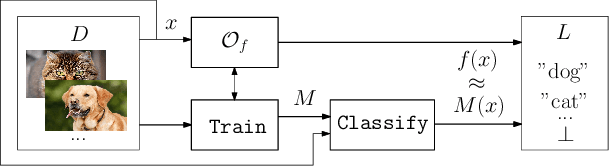
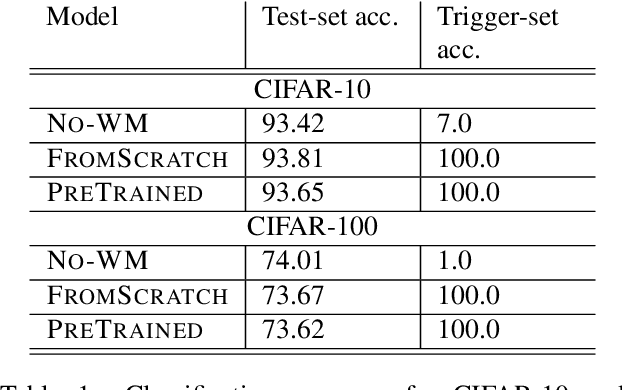
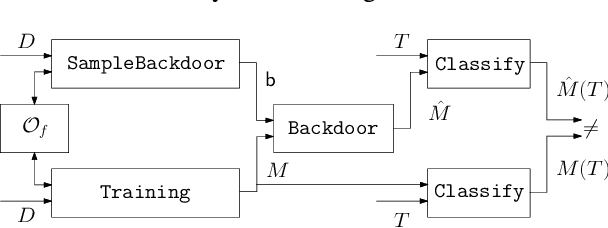

Deep Neural Networks have recently gained lots of success after enabling several breakthroughs in notoriously challenging problems. Training these networks is computationally expensive and requires vast amounts of training data. Selling such pre-trained models can, therefore, be a lucrative business model. Unfortunately, once the models are sold they can be easily copied and redistributed. To avoid this, a tracking mechanism to identify models as the intellectual property of a particular vendor is necessary. In this work, we present an approach for watermarking Deep Neural Networks in a black-box way. Our scheme works for general classification tasks and can easily be combined with current learning algorithms. We show experimentally that such a watermark has no noticeable impact on the primary task that the model is designed for and evaluate the robustness of our proposal against a multitude of practical attacks. Moreover, we provide a theoretical analysis, relating our approach to previous work on backdooring.