 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
Variance Reduction in Deep Learning: More Momentum is All You Need
Nov 23, 2021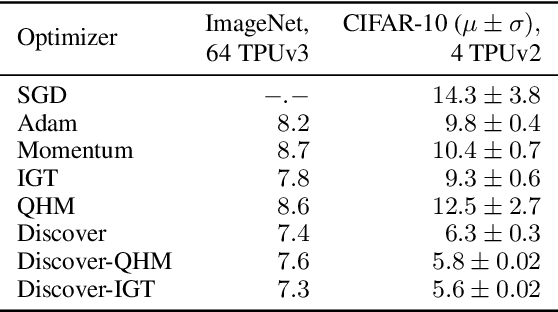
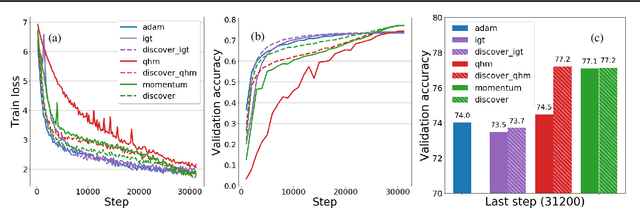
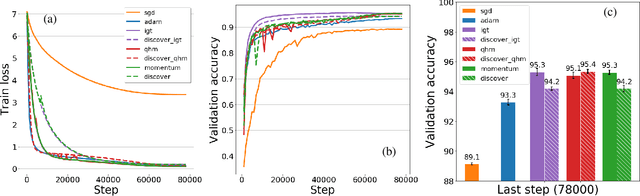
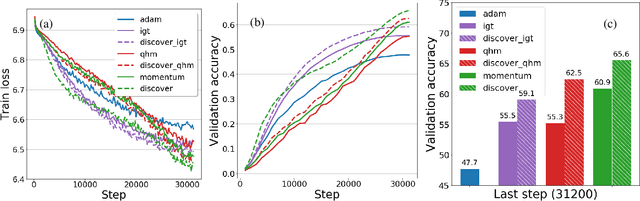
Variance reduction (VR) techniques have contributed significantly to accelerating learning with massive datasets in the smooth and strongly convex setting (Schmidt et al., 2017; Johnson & Zhang, 2013; Roux et al., 2012). However, such techniques have not yet met the same success in the realm of large-scale deep learning due to various factors such as the use of data augmentation or regularization methods like dropout (Defazio & Bottou, 2019). This challenge has recently motivated the design of novel variance reduction techniques tailored explicitly for deep learning (Arnold et al., 2019; Ma & Yarats, 2018). This work is an additional step in this direction. In particular, we exploit the ubiquitous clustering structure of rich datasets used in deep learning to design a family of scalable variance reduced optimization procedures by combining existing optimizers (e.g., SGD+Momentum, Quasi Hyperbolic Momentum, Implicit Gradient Transport) with a multi-momentum strategy (Yuan et al., 2019). Our proposal leads to faster convergence than vanilla methods on standard benchmark datasets (e.g., CIFAR and ImageNet). It is robust to label noise and amenable to distributed optimization. We provide a parallel implementation in JAX.
Continental-Scale Building Detection from High Resolution Satellite Imagery
Jul 29, 2021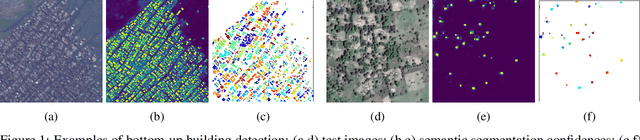
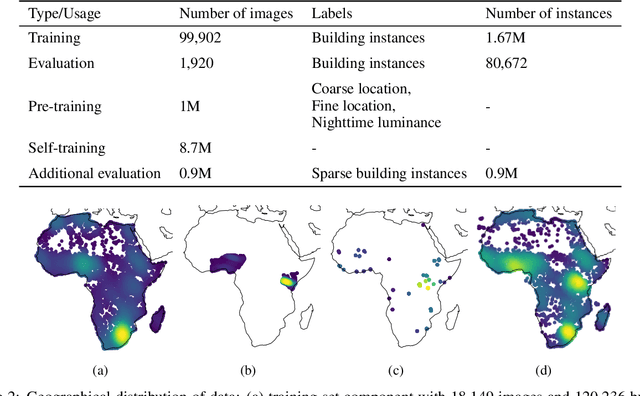

Identifying the locations and footprints of buildings is vital for many practical and scientific purposes. Such information can be particularly useful in developing regions where alternative data sources may be scarce. In this work, we describe a model training pipeline for detecting buildings across the entire continent of Africa, using 50 cm satellite imagery. Starting with the U-Net model, widely used in satellite image analysis, we study variations in architecture, loss functions, regularization, pre-training, self-training and post-processing that increase instance segmentation performance. Experiments were carried out using a dataset of 100k satellite images across Africa containing 1.75M manually labelled building instances, and further datasets for pre-training and self-training. We report novel methods for improving performance of building detection with this type of model, including the use of mixup (mAP +0.12) and self-training with soft KL loss (mAP +0.06). The resulting pipeline obtains good results even on a wide variety of challenging rural and urban contexts, and was used to create the Open Buildings dataset of 516M Africa-wide detected footprints.
Fairness with Overlapping Groups
Jun 24, 2020
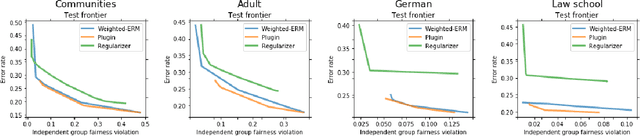

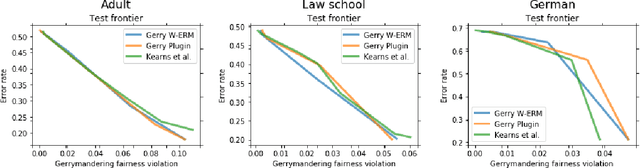
In algorithmically fair prediction problems, a standard goal is to ensure the equality of fairness metrics across multiple overlapping groups simultaneously. We reconsider this standard fair classification problem using a probabilistic population analysis, which, in turn, reveals the Bayes-optimal classifier. Our approach unifies a variety of existing group-fair classification methods and enables extensions to a wide range of non-decomposable multiclass performance metrics and fairness measures. The Bayes-optimal classifier further inspires consistent procedures for algorithmically fair classification with overlapping groups. On a variety of real datasets, the proposed approach outperforms baselines in terms of its fairness-performance tradeoff.
ConvNets and ImageNet Beyond Accuracy: Understanding Mistakes and Uncovering Biases
Jul 20, 2018
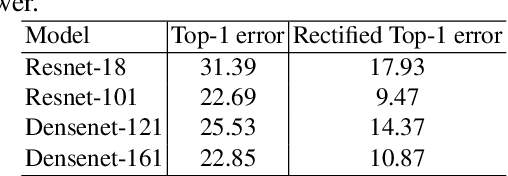
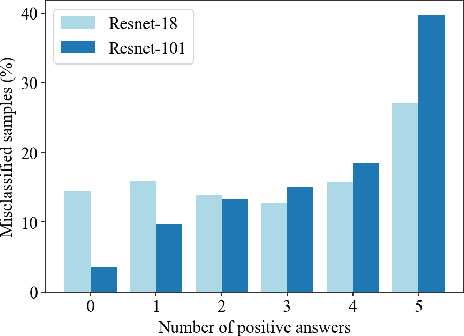

ConvNets and Imagenet have driven the recent success of deep learning for image classification. However, the marked slowdown in performance improvement combined with the lack of robustness of neural networks to adversarial examples and their tendency to exhibit undesirable biases question the reliability of these methods. This work investigates these questions from the perspective of the end-user by using human subject studies and explanations. The contribution of this study is threefold. We first experimentally demonstrate that the accuracy and robustness of ConvNets measured on Imagenet are vastly underestimated. Next, we show that explanations can mitigate the impact of misclassified adversarial examples from the perspective of the end-user. We finally introduce a novel tool for uncovering the undesirable biases learned by a model. These contributions also show that explanations are a valuable tool both for improving our understanding of ConvNets' predictions and for designing more reliable models.
Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring
Jun 11, 2018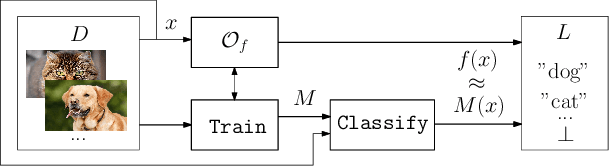
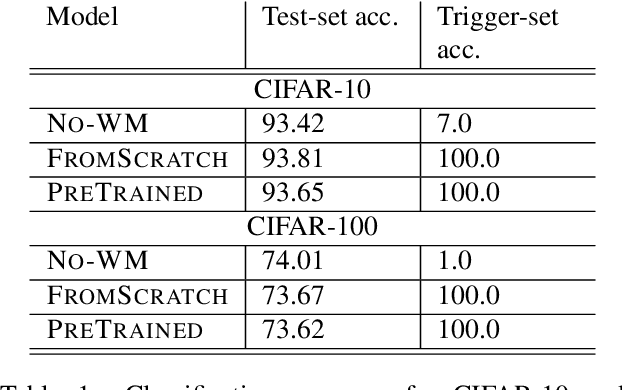
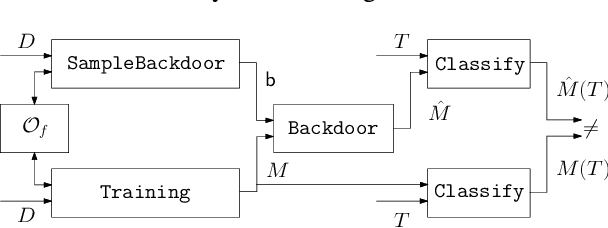

Deep Neural Networks have recently gained lots of success after enabling several breakthroughs in notoriously challenging problems. Training these networks is computationally expensive and requires vast amounts of training data. Selling such pre-trained models can, therefore, be a lucrative business model. Unfortunately, once the models are sold they can be easily copied and redistributed. To avoid this, a tracking mechanism to identify models as the intellectual property of a particular vendor is necessary. In this work, we present an approach for watermarking Deep Neural Networks in a black-box way. Our scheme works for general classification tasks and can easily be combined with current learning algorithms. We show experimentally that such a watermark has no noticeable impact on the primary task that the model is designed for and evaluate the robustness of our proposal against a multitude of practical attacks. Moreover, we provide a theoretical analysis, relating our approach to previous work on backdooring.
mixup: Beyond Empirical Risk Minimization
Apr 27, 2018
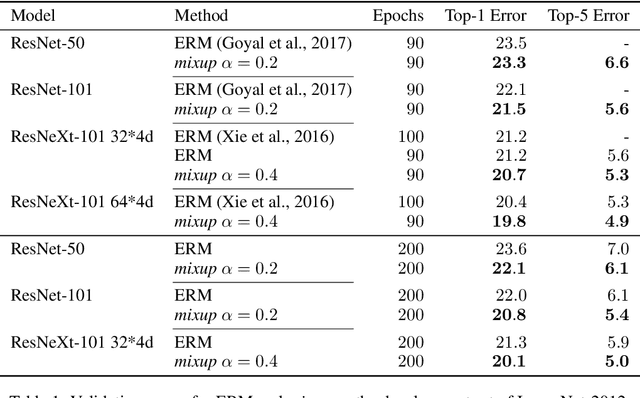
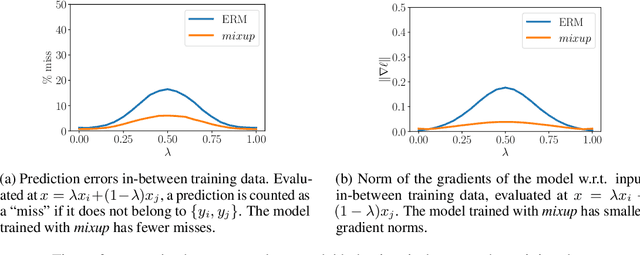
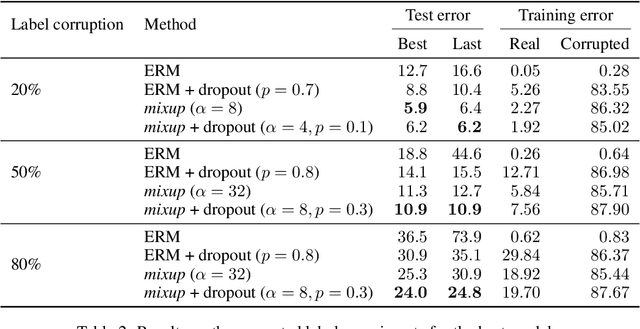
Large deep neural networks are powerful, but exhibit undesirable behaviors such as memorization and sensitivity to adversarial examples. In this work, we propose mixup, a simple learning principle to alleviate these issues. In essence, mixup trains a neural network on convex combinations of pairs of examples and their labels. By doing so, mixup regularizes the neural network to favor simple linear behavior in-between training examples. Our experiments on the ImageNet-2012, CIFAR-10, CIFAR-100, Google commands and UCI datasets show that mixup improves the generalization of state-of-the-art neural network architectures. We also find that mixup reduces the memorization of corrupt labels, increases the robustness to adversarial examples, and stabilizes the training of generative adversarial networks.
Fooling End-to-end Speaker Verification by Adversarial Examples
Feb 16, 2018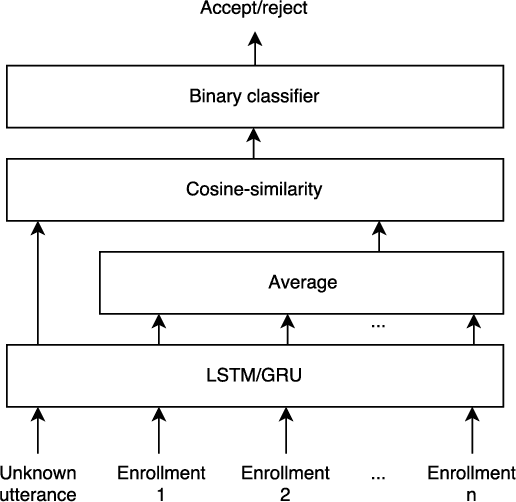
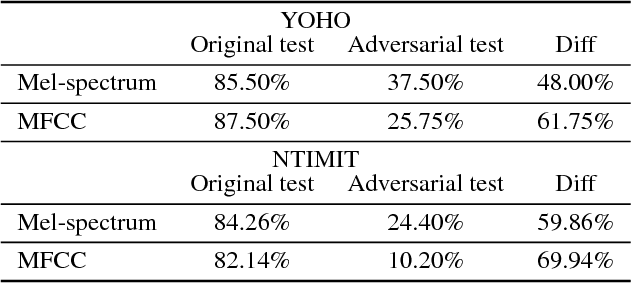

Automatic speaker verification systems are increasingly used as the primary means to authenticate costumers. Recently, it has been proposed to train speaker verification systems using end-to-end deep neural models. In this paper, we show that such systems are vulnerable to adversarial example attack. Adversarial examples are generated by adding a peculiar noise to original speaker examples, in such a way that they are almost indistinguishable from the original examples by a human listener. Yet, the generated waveforms, which sound as speaker A can be used to fool such a system by claiming as if the waveforms were uttered by speaker B. We present white-box attacks on an end-to-end deep network that was either trained on YOHO or NTIMIT. We also present two black-box attacks: where the adversarial examples were generated with a system that was trained on YOHO, but the attack is on a system that was trained on NTIMIT; and when the adversarial examples were generated with a system that was trained on Mel-spectrum feature set, but the attack is on a system that was trained on MFCC. Results suggest that the accuracy of the attacked system was decreased and the false-positive rate was dramatically increased.
Countering Adversarial Images using Input Transformations
Jan 25, 2018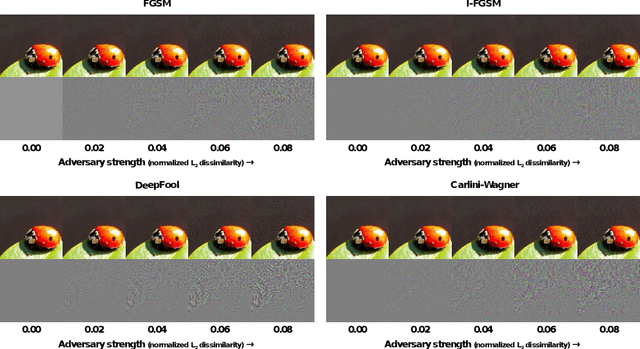



This paper investigates strategies that defend against adversarial-example attacks on image-classification systems by transforming the inputs before feeding them to the system. Specifically, we study applying image transformations such as bit-depth reduction, JPEG compression, total variance minimization, and image quilting before feeding the image to a convolutional network classifier. Our experiments on ImageNet show that total variance minimization and image quilting are very effective defenses in practice, in particular, when the network is trained on transformed images. The strength of those defenses lies in their non-differentiable nature and their inherent randomness, which makes it difficult for an adversary to circumvent the defenses. Our best defense eliminates 60% of strong gray-box and 90% of strong black-box attacks by a variety of major attack methods
Unbounded cache model for online language modeling with open vocabulary
Nov 07, 2017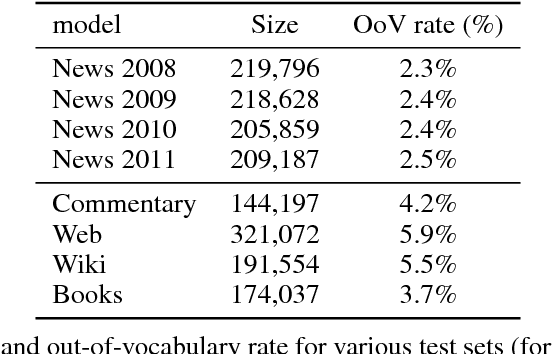
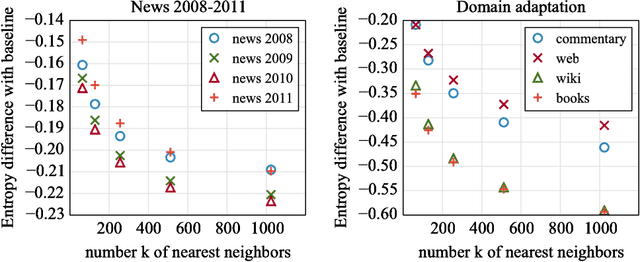
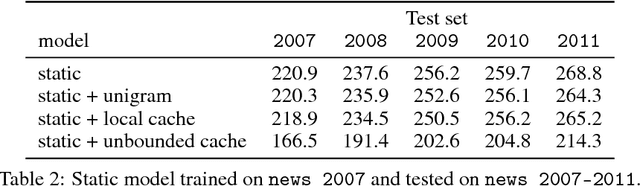
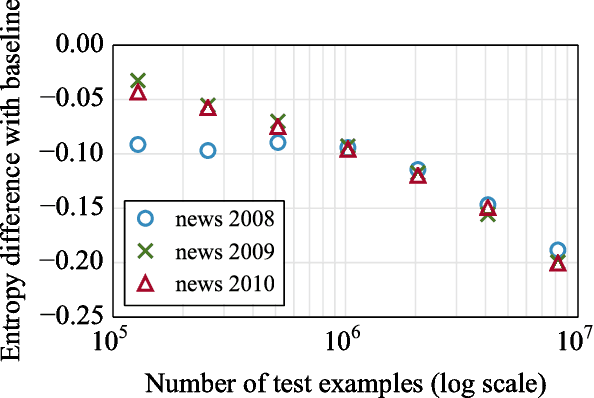
Recently, continuous cache models were proposed as extensions to recurrent neural network language models, to adapt their predictions to local changes in the data distribution. These models only capture the local context, of up to a few thousands tokens. In this paper, we propose an extension of continuous cache models, which can scale to larger contexts. In particular, we use a large scale non-parametric memory component that stores all the hidden activations seen in the past. We leverage recent advances in approximate nearest neighbor search and quantization algorithms to store millions of representations while searching them efficiently. We conduct extensive experiments showing that our approach significantly improves the perplexity of pre-trained language models on new distributions, and can scale efficiently to much larger contexts than previously proposed local cache models.