 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSunflower: A New Approach To Expanding Coverage of African Languages in Large Language Models
Oct 08, 2025There are more than 2000 living languages in Africa, most of which have been bypassed by advances in language technology. Current leading LLMs exhibit strong performance on a number of the most common languages (e.g. Swahili or Yoruba), but prioritise support for the languages with the most speakers first, resulting in piecemeal ability across disparate languages. We contend that a regionally focussed approach is more efficient, and present a case study for Uganda, a country with high linguistic diversity. We describe the development of Sunflower 14B and 32B, a pair of models based on Qwen 3 with state of the art comprehension in the majority of all Ugandan languages. These models are open source and can be used to reduce language barriers in a number of important practical applications.
How much speech data is necessary for ASR in African languages? An evaluation of data scaling in Kinyarwanda and Kikuyu
Oct 08, 2025
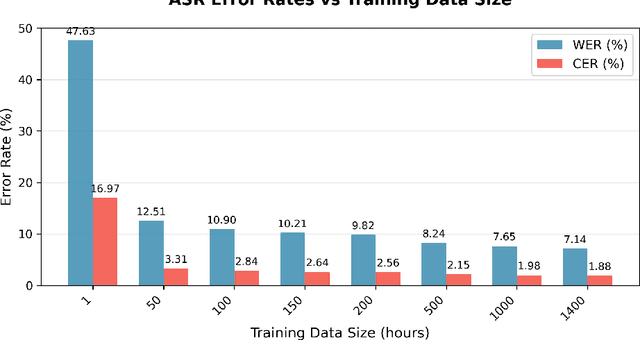

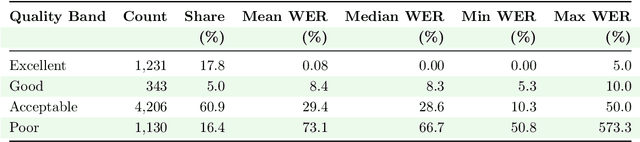
The development of Automatic Speech Recognition (ASR) systems for low-resource African languages remains challenging due to limited transcribed speech data. While recent advances in large multilingual models like OpenAI's Whisper offer promising pathways for low-resource ASR development, critical questions persist regarding practical deployment requirements. This paper addresses two fundamental concerns for practitioners: determining the minimum data volumes needed for viable performance and characterizing the primary failure modes that emerge in production systems. We evaluate Whisper's performance through comprehensive experiments on two Bantu languages: systematic data scaling analysis on Kinyarwanda using training sets from 1 to 1,400 hours, and detailed error characterization on Kikuyu using 270 hours of training data. Our scaling experiments demonstrate that practical ASR performance (WER < 13\%) becomes achievable with as little as 50 hours of training data, with substantial improvements continuing through 200 hours (WER < 10\%). Complementing these volume-focused findings, our error analysis reveals that data quality issues, particularly noisy ground truth transcriptions, account for 38.6\% of high-error cases, indicating that careful data curation is as critical as data volume for robust system performance. These results provide actionable benchmarks and deployment guidance for teams developing ASR systems across similar low-resource language contexts. We release accompanying and models see https://github.com/SunbirdAI/kinyarwanda-whisper-eval
Building a Luganda Text-to-Speech Model From Crowdsourced Data
May 16, 2024

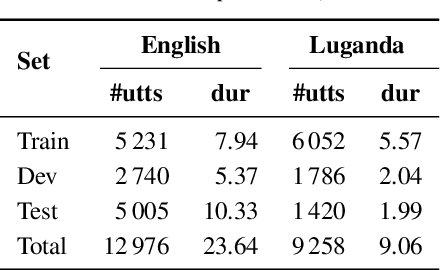
Text-to-speech (TTS) development for African languages such as Luganda is still limited, primarily due to the scarcity of high-quality, single-speaker recordings essential for training TTS models. Prior work has focused on utilizing the Luganda Common Voice recordings of multiple speakers aged between 20-49. Although the generated speech is intelligible, it is still of lower quality than the model trained on studio-grade recordings. This is due to the insufficient data preprocessing methods applied to improve the quality of the Common Voice recordings. Furthermore, speech convergence is more difficult to achieve due to varying intonations, as well as background noise. In this paper, we show that the quality of Luganda TTS from Common Voice can improve by training on multiple speakers of close intonation in addition to further preprocessing of the training data. Specifically, we selected six female speakers with close intonation determined by subjectively listening and comparing their voice recordings. In addition to trimming out silent portions from the beginning and end of the recordings, we applied a pre-trained speech enhancement model to reduce background noise and enhance audio quality. We also utilized a pre-trained, non-intrusive, self-supervised Mean Opinion Score (MOS) estimation model to filter recordings with an estimated MOS over 3.5, indicating high perceived quality. Subjective MOS evaluations from nine native Luganda speakers demonstrate that our TTS model achieves a significantly better MOS of 3.55 compared to the reported 2.5 MOS of the existing model. Moreover, for a fair comparison, our model trained on six speakers outperforms models trained on a single-speaker (3.13 MOS) or two speakers (3.22 MOS). This showcases the effectiveness of compensating for the lack of data from one speaker with data from multiple speakers of close intonation to improve TTS quality.
High-Resolution Building and Road Detection from Sentinel-2
Oct 17, 2023



Mapping buildings and roads automatically with remote sensing typically requires high-resolution imagery, which is expensive to obtain and often sparsely available. In this work we demonstrate how multiple 10 m resolution Sentinel-2 images can be used to generate 50 cm resolution building and road segmentation masks. This is done by training a `student' model with access to Sentinel-2 images to reproduce the predictions of a `teacher' model which has access to corresponding high-resolution imagery. While the predictions do not have all the fine detail of the teacher model, we find that we are able to retain much of the performance: for building segmentation we achieve 78.3% mIoU, compared to the high-resolution teacher model accuracy of 85.3% mIoU. We also describe a related method for counting individual buildings in a Sentinel-2 patch which achieves R^2 = 0.91 against true counts. This work opens up new possibilities for using freely available Sentinel-2 imagery for a range of tasks that previously could only be done with high-resolution satellite imagery.
Feature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021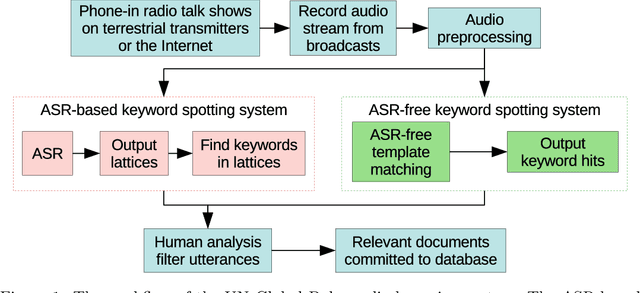
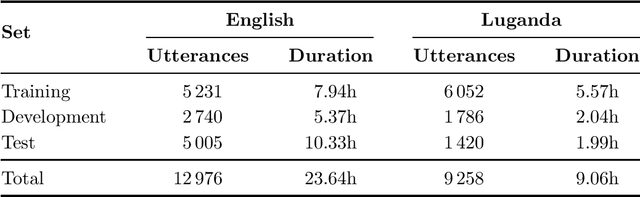

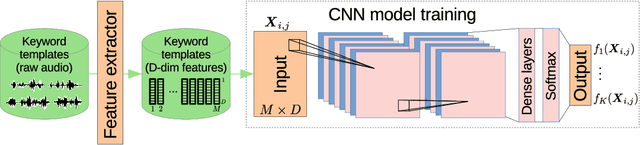
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.
Continental-Scale Building Detection from High Resolution Satellite Imagery
Jul 29, 2021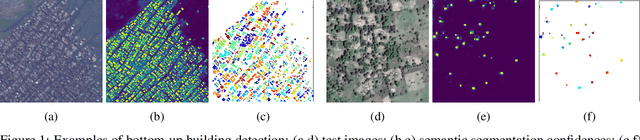
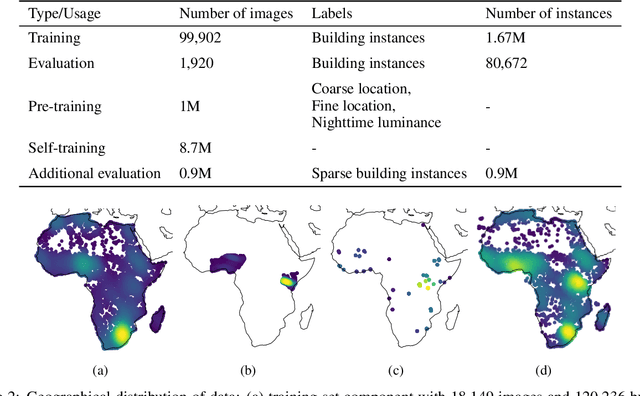

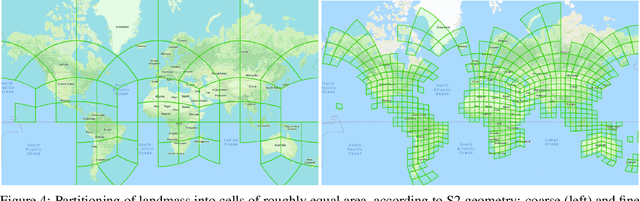
Identifying the locations and footprints of buildings is vital for many practical and scientific purposes. Such information can be particularly useful in developing regions where alternative data sources may be scarce. In this work, we describe a model training pipeline for detecting buildings across the entire continent of Africa, using 50 cm satellite imagery. Starting with the U-Net model, widely used in satellite image analysis, we study variations in architecture, loss functions, regularization, pre-training, self-training and post-processing that increase instance segmentation performance. Experiments were carried out using a dataset of 100k satellite images across Africa containing 1.75M manually labelled building instances, and further datasets for pre-training and self-training. We report novel methods for improving performance of building detection with this type of model, including the use of mixup (mAP +0.12) and self-training with soft KL loss (mAP +0.06). The resulting pipeline obtains good results even on a wide variety of challenging rural and urban contexts, and was used to create the Open Buildings dataset of 516M Africa-wide detected footprints.
Almost Zero-Resource ASR-free Keyword Spotting using Multilingual Bottleneck Features and Correspondence Autoencoders
Nov 14, 2018
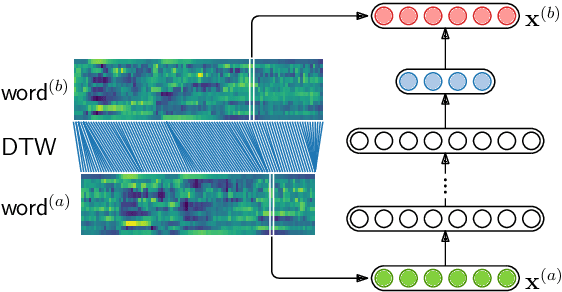

We compare features for dynamic time warping based keyword spotting in an almost zero-resource setting. The objective is to support United Nations (UN) humanitarian relief efforts in parts of Africa with severely under-resourced languages. As supervised resource, we restrict ourselves to an easily-compiled small set of isolated keywords. For feature extraction, we integrate a multilingual bottleneck feature extractor (BNF), trained on well-resourced out-of-domain languages, with a correspondence autoencoder (CAE), trained on extremely sparse in-domain data. We find that, on their own, BNFs and CAE features achieve more than 2% absolute performance improvement over baseline MFCCs. However, by using BNFs as input to the CAE, even better performance is achieved, with an 11% absolute improvement in ROC AUC over MFCCs and twice as many top-10 retrievals. We conclude that integrating BNFs with the CAE allows both large out-of-domain and sparse in-domain resources to be exploited for improved ASR-free keyword spotting.
Automatic Speech Recognition for Humanitarian Applications in Somali
Jul 23, 2018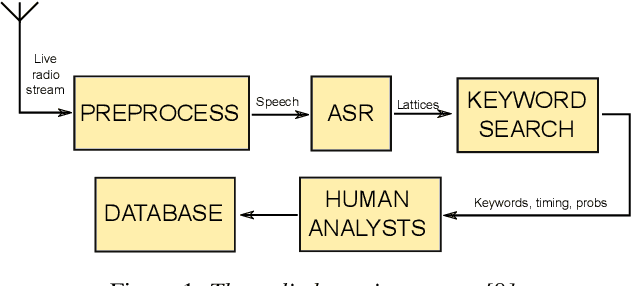
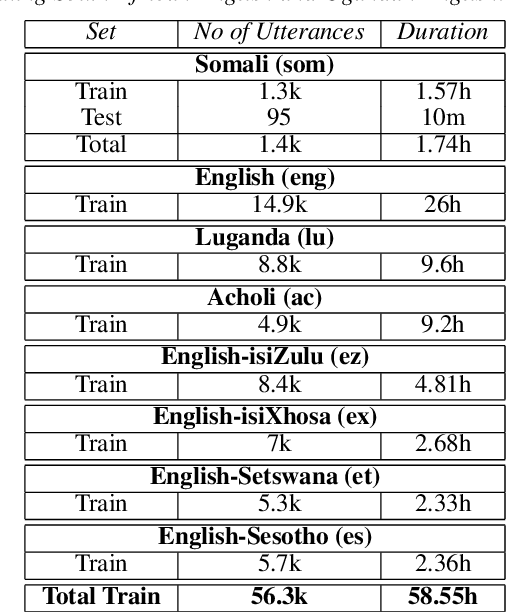
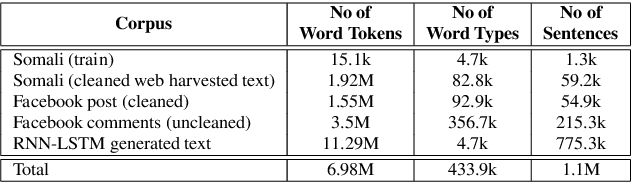
We present our first efforts in building an automatic speech recognition system for Somali, an under-resourced language, using 1.57 hrs of annotated speech for acoustic model training. The system is part of an ongoing effort by the United Nations (UN) to implement keyword spotting systems supporting humanitarian relief programmes in parts of Africa where languages are severely under-resourced. We evaluate several types of acoustic model, including recent neural architectures. Language model data augmentation using a combination of recurrent neural networks (RNN) and long short-term memory neural networks (LSTMs) as well as the perturbation of acoustic data are also considered. We find that both types of data augmentation are beneficial to performance, with our best system using a combination of convolutional neural networks (CNNs), time-delay neural networks (TDNNs) and bi-directional long short term memory (BLSTMs) to achieve a word error rate of 53.75%.
ASR-free CNN-DTW keyword spotting using multilingual bottleneck features for almost zero-resource languages
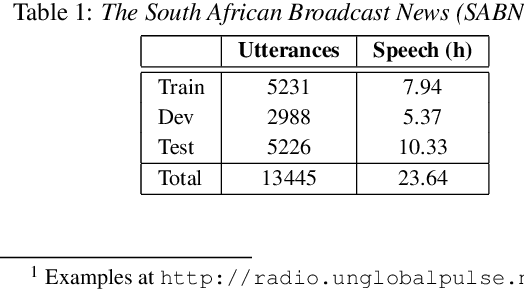
Jul 23, 2018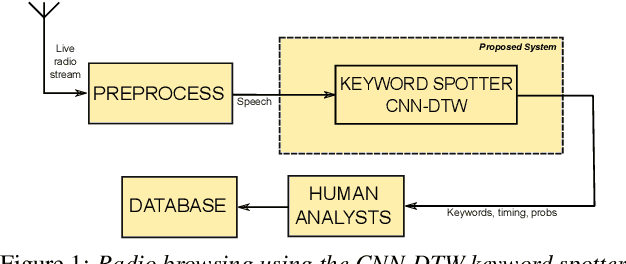
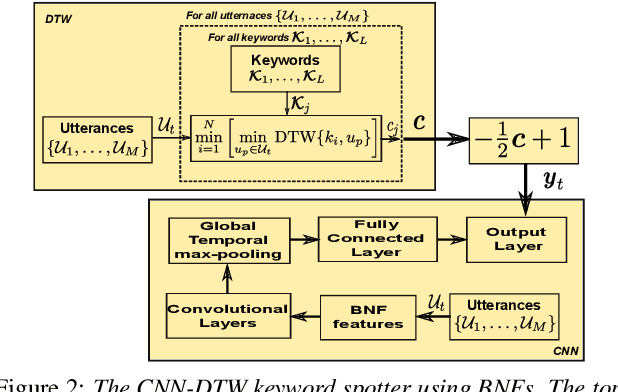
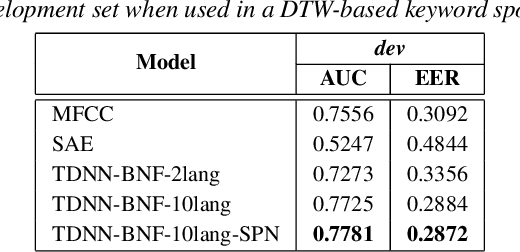
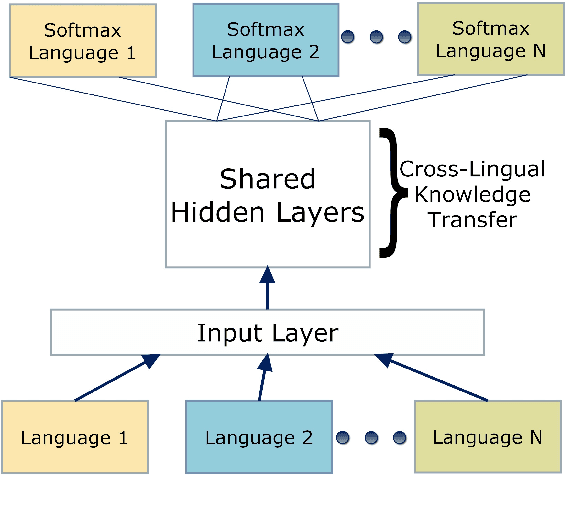
We consider multilingual bottleneck features (BNFs) for nearly zero-resource keyword spotting. This forms part of a United Nations effort using keyword spotting to support humanitarian relief programmes in parts of Africa where languages are severely under-resourced. We use 1920 isolated keywords (40 types, 34 minutes) as exemplars for dynamic time warping (DTW) template matching, which is performed on a much larger body of untranscribed speech. These DTW costs are used as targets for a convolutional neural network (CNN) keyword spotter, giving a much faster system than direct DTW. Here we consider how available data from well-resourced languages can improve this CNN-DTW approach. We show that multilingual BNFs trained on ten languages improve the area under the ROC curve of a CNN-DTW system by 10.9% absolute relative to the MFCC baseline. By combining low-resource DTW-based supervision with information from well-resourced languages, CNN-DTW is a competitive option for low-resource keyword spotting.
Fast ASR-free and almost zero-resource keyword spotting using DTW and CNNs for humanitarian monitoring
Jun 25, 2018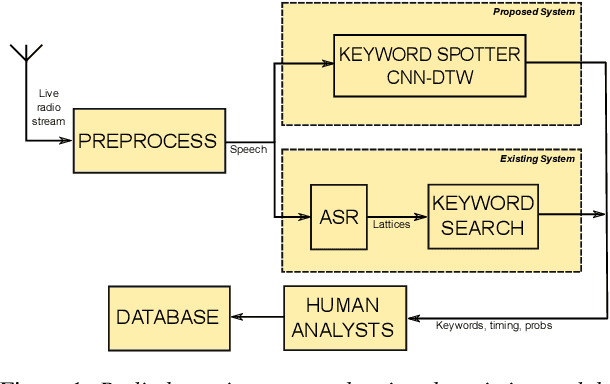
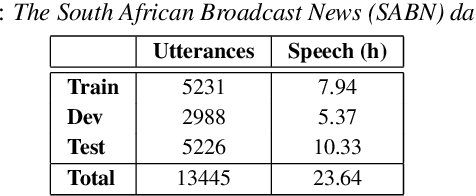
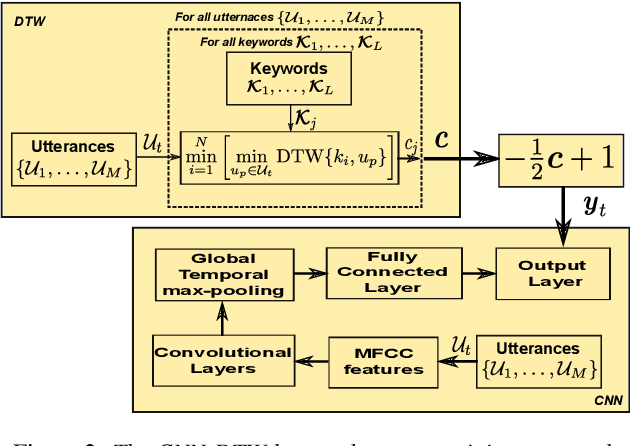
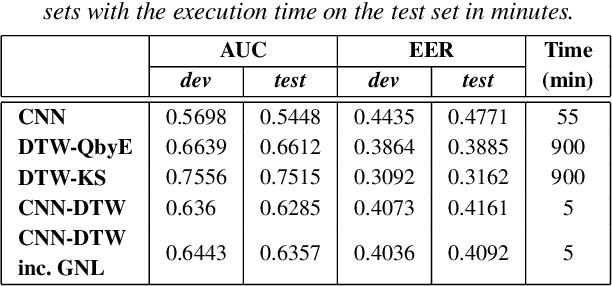
We use dynamic time warping (DTW) as supervision for training a convolutional neural network (CNN) based keyword spotting system using a small set of spoken isolated keywords. The aim is to allow rapid deployment of a keyword spotting system in a new language to support urgent United Nations (UN) relief programmes in parts of Africa where languages are extremely under-resourced and the development of annotated speech resources is infeasible. First, we use 1920 recorded keywords (40 keyword types, 34 minutes of speech) as exemplars in a DTW-based template matching system and apply it to untranscribed broadcast speech. Then, we use the resulting DTW scores as targets to train a CNN on the same unlabelled speech. In this way we use just 34 minutes of labelled speech, but leverage a large amount of unlabelled data for training. While the resulting CNN keyword spotter cannot match the performance of the DTW-based system, it substantially outperforms a CNN classifier trained only on the keywords, improving the area under the ROC curve from 0.54 to 0.64. Because our CNN system is several orders of magnitude faster at runtime than the DTW system, it represents the most viable keyword spotter on this extremely limited dataset.