 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021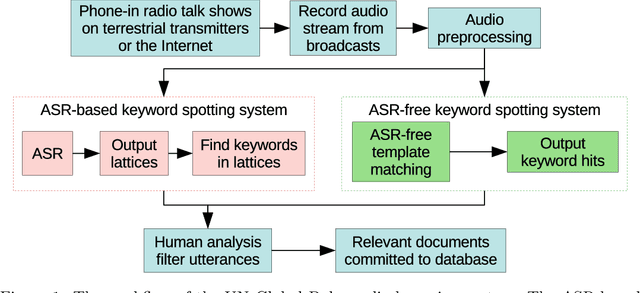
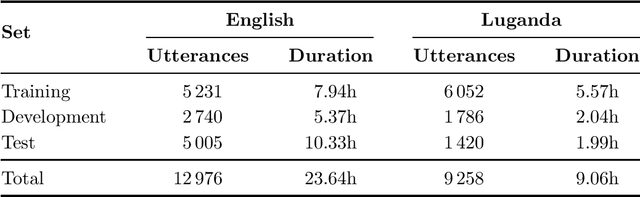

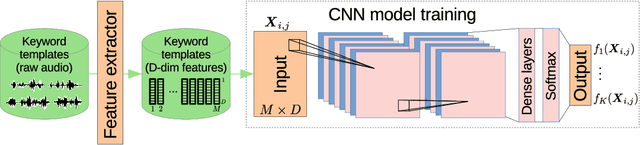
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.
Improved low-resource Somali speech recognition by semi-supervised acoustic and language model training
Jul 06, 2019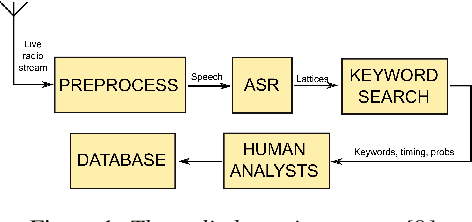
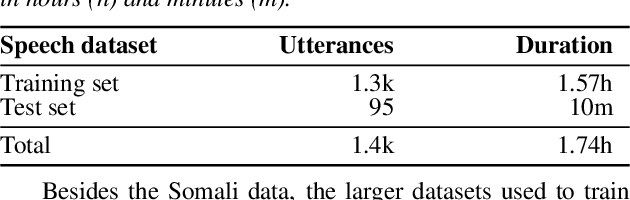
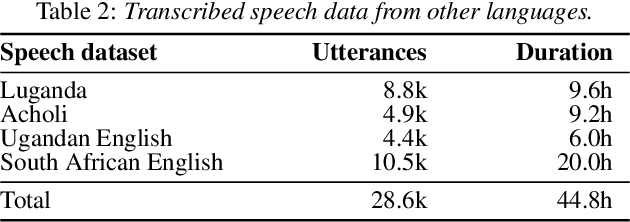
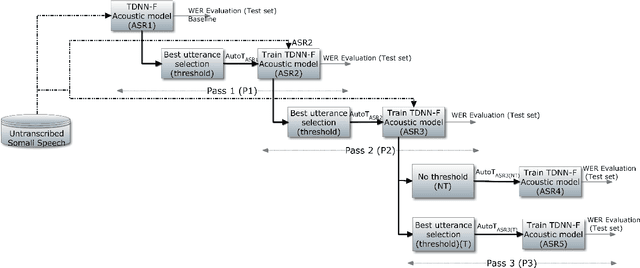
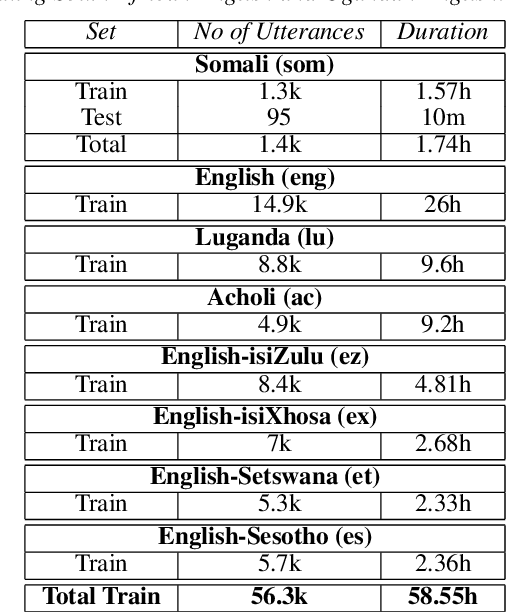
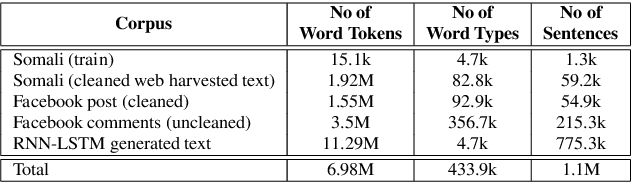
We present improvements in automatic speech recognition (ASR) for Somali, a currently extremely under-resourced language. This forms part of a continuing United Nations (UN) effort to employ ASR-based keyword spotting systems to support humanitarian relief programmes in rural Africa. Using just 1.57 hours of annotated speech data as a seed corpus, we increase the pool of training data by applying semi-supervised training to 17.55 hours of untranscribed speech. We make use of factorised time-delay neural networks (TDNN-F) for acoustic modelling, since these have recently been shown to be effective in resource-scarce situations. Three semi-supervised training passes were performed, where the decoded output from each pass was used for acoustic model training in the subsequent pass. The automatic transcriptions from the best performing pass were used for language model augmentation. To ensure the quality of automatic transcriptions, decoder confidence is used as a threshold. The acoustic and language models obtained from the semi-supervised approach show significant improvement in terms of WER and perplexity compared to the baseline. Incorporating the automatically generated transcriptions yields a 6.55\% improvement in language model perplexity. The use of 17.55 hour of Somali acoustic data in semi-supervised training shows an improvement of 7.74\% relative over the baseline.
Almost Zero-Resource ASR-free Keyword Spotting using Multilingual Bottleneck Features and Correspondence Autoencoders
Nov 14, 2018
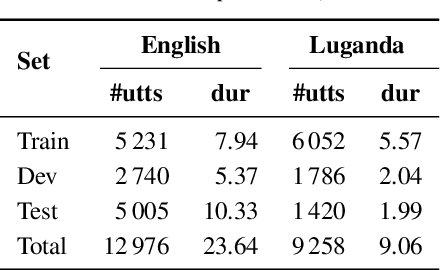
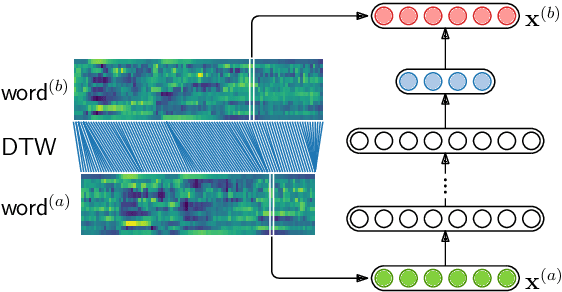

We compare features for dynamic time warping based keyword spotting in an almost zero-resource setting. The objective is to support United Nations (UN) humanitarian relief efforts in parts of Africa with severely under-resourced languages. As supervised resource, we restrict ourselves to an easily-compiled small set of isolated keywords. For feature extraction, we integrate a multilingual bottleneck feature extractor (BNF), trained on well-resourced out-of-domain languages, with a correspondence autoencoder (CAE), trained on extremely sparse in-domain data. We find that, on their own, BNFs and CAE features achieve more than 2% absolute performance improvement over baseline MFCCs. However, by using BNFs as input to the CAE, even better performance is achieved, with an 11% absolute improvement in ROC AUC over MFCCs and twice as many top-10 retrievals. We conclude that integrating BNFs with the CAE allows both large out-of-domain and sparse in-domain resources to be exploited for improved ASR-free keyword spotting.
Automatic Speech Recognition for Humanitarian Applications in Somali
Jul 23, 2018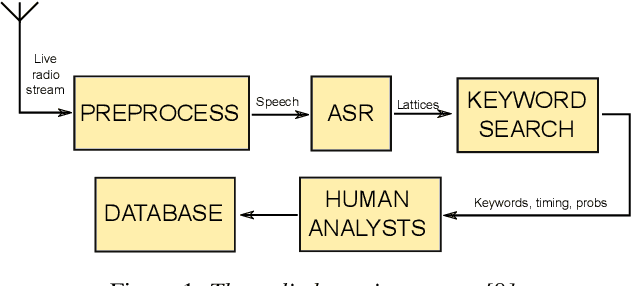
We present our first efforts in building an automatic speech recognition system for Somali, an under-resourced language, using 1.57 hrs of annotated speech for acoustic model training. The system is part of an ongoing effort by the United Nations (UN) to implement keyword spotting systems supporting humanitarian relief programmes in parts of Africa where languages are severely under-resourced. We evaluate several types of acoustic model, including recent neural architectures. Language model data augmentation using a combination of recurrent neural networks (RNN) and long short-term memory neural networks (LSTMs) as well as the perturbation of acoustic data are also considered. We find that both types of data augmentation are beneficial to performance, with our best system using a combination of convolutional neural networks (CNNs), time-delay neural networks (TDNNs) and bi-directional long short term memory (BLSTMs) to achieve a word error rate of 53.75%.
ASR-free CNN-DTW keyword spotting using multilingual bottleneck features for almost zero-resource languages
Jul 23, 2018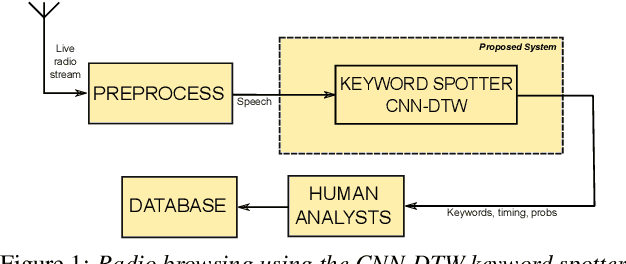
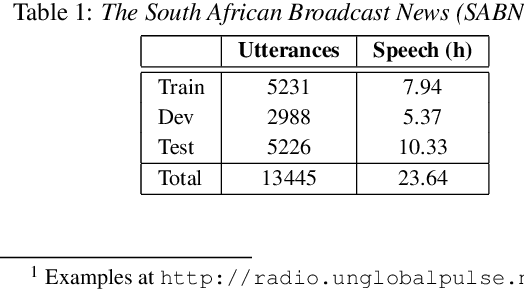
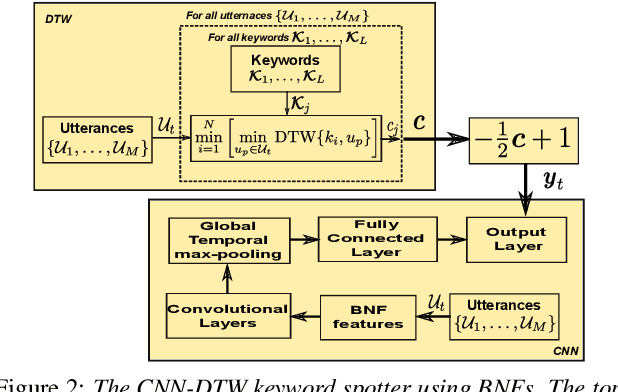
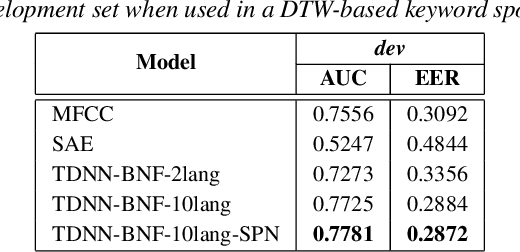
We consider multilingual bottleneck features (BNFs) for nearly zero-resource keyword spotting. This forms part of a United Nations effort using keyword spotting to support humanitarian relief programmes in parts of Africa where languages are severely under-resourced. We use 1920 isolated keywords (40 types, 34 minutes) as exemplars for dynamic time warping (DTW) template matching, which is performed on a much larger body of untranscribed speech. These DTW costs are used as targets for a convolutional neural network (CNN) keyword spotter, giving a much faster system than direct DTW. Here we consider how available data from well-resourced languages can improve this CNN-DTW approach. We show that multilingual BNFs trained on ten languages improve the area under the ROC curve of a CNN-DTW system by 10.9% absolute relative to the MFCC baseline. By combining low-resource DTW-based supervision with information from well-resourced languages, CNN-DTW is a competitive option for low-resource keyword spotting.
Fast ASR-free and almost zero-resource keyword spotting using DTW and CNNs for humanitarian monitoring
Jun 25, 2018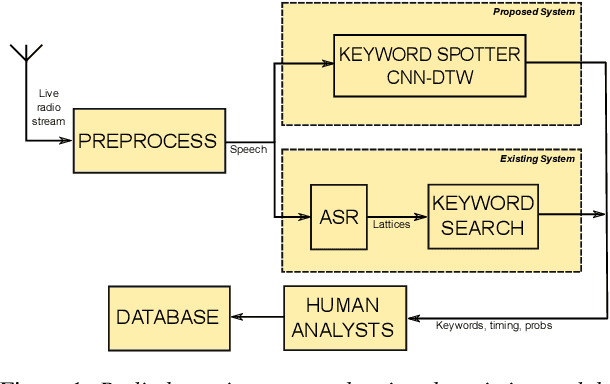
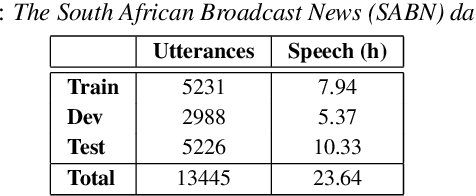
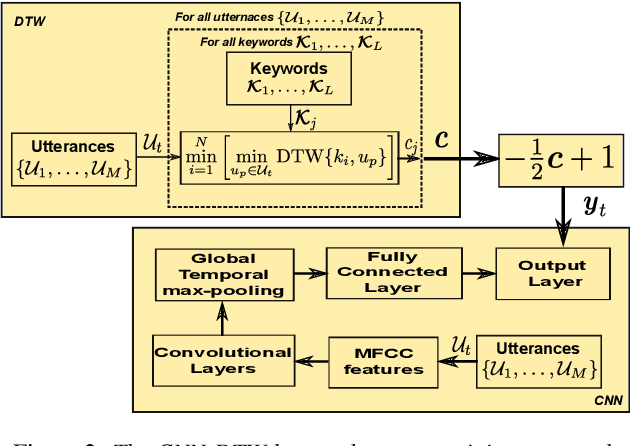
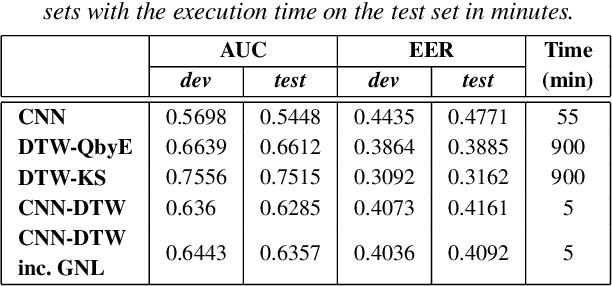
We use dynamic time warping (DTW) as supervision for training a convolutional neural network (CNN) based keyword spotting system using a small set of spoken isolated keywords. The aim is to allow rapid deployment of a keyword spotting system in a new language to support urgent United Nations (UN) relief programmes in parts of Africa where languages are extremely under-resourced and the development of annotated speech resources is infeasible. First, we use 1920 recorded keywords (40 keyword types, 34 minutes of speech) as exemplars in a DTW-based template matching system and apply it to untranscribed broadcast speech. Then, we use the resulting DTW scores as targets to train a CNN on the same unlabelled speech. In this way we use just 34 minutes of labelled speech, but leverage a large amount of unlabelled data for training. While the resulting CNN keyword spotter cannot match the performance of the DTW-based system, it substantially outperforms a CNN classifier trained only on the keywords, improving the area under the ROC curve from 0.54 to 0.64. Because our CNN system is several orders of magnitude faster at runtime than the DTW system, it represents the most viable keyword spotter on this extremely limited dataset.