 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASR-free CNN-DTW keyword spotting using multilingual bottleneck features for almost zero-resource languages
Paper and Code
Jul 23, 2018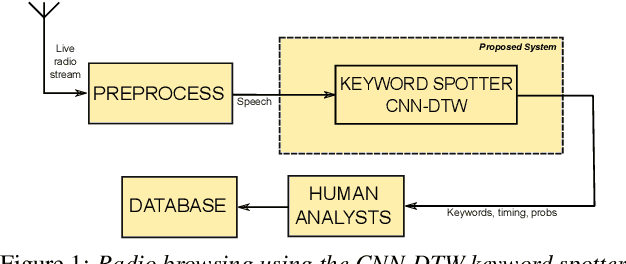
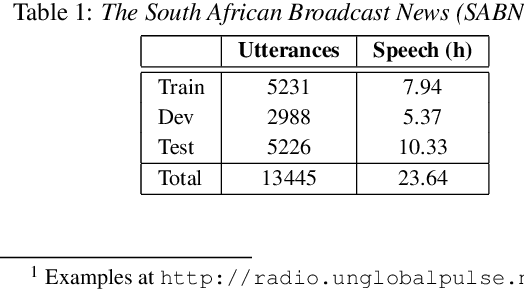
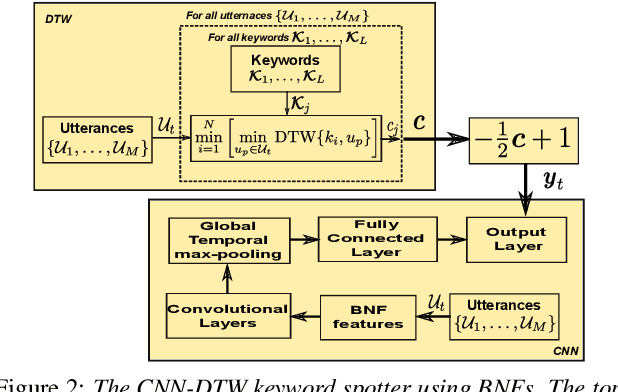
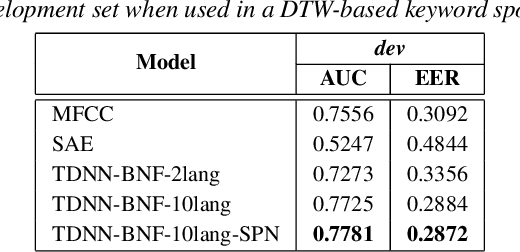
We consider multilingual bottleneck features (BNFs) for nearly zero-resource keyword spotting. This forms part of a United Nations effort using keyword spotting to support humanitarian relief programmes in parts of Africa where languages are severely under-resourced. We use 1920 isolated keywords (40 types, 34 minutes) as exemplars for dynamic time warping (DTW) template matching, which is performed on a much larger body of untranscribed speech. These DTW costs are used as targets for a convolutional neural network (CNN) keyword spotter, giving a much faster system than direct DTW. Here we consider how available data from well-resourced languages can improve this CNN-DTW approach. We show that multilingual BNFs trained on ten languages improve the area under the ROC curve of a CNN-DTW system by 10.9% absolute relative to the MFCC baseline. By combining low-resource DTW-based supervision with information from well-resourced languages, CNN-DTW is a competitive option for low-resource keyword spotting.