 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of a vision based range bearing and heading system for robot swarms
Mar 14, 2021An essential problem of swarm robotics is how members of the swarm knows the positions of other robots. The main aim of this research is to develop a cost-effective and simple vision-based system to detect the range, bearing, and heading of the robots inside a swarm using a multi-purpose passive landmark. A small Zumo robot equipped with Raspberry Pi, PiCamera is utilized for the implementation of the algorithm, and different kinds of multipurpose passive landmarks with nonsymmetrical patterns, which give reliable information about the range, bearing and heading in a single unit, are designed. By comparing the recorded features obtained from image analysis of the landmark through systematical experimentation and the actual measurements, correlations are obtained, and algorithms converting those features into range, bearing and heading are designed. The reliability and accuracy of algorithms are tested and errors are found within an acceptable range.
Deep Spiking Neural Networks for Large Vocabulary Automatic Speech Recognition
Nov 19, 2019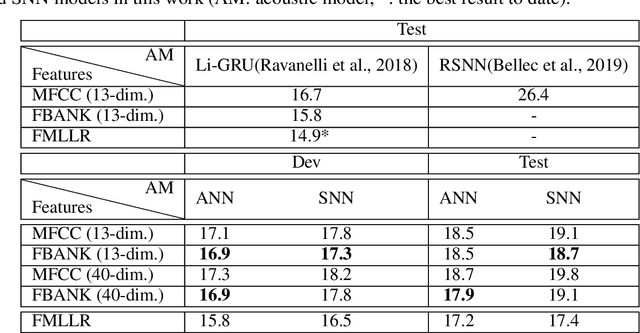
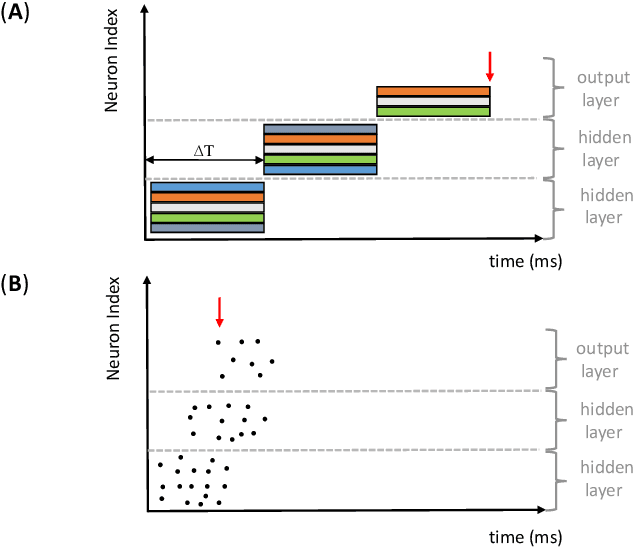
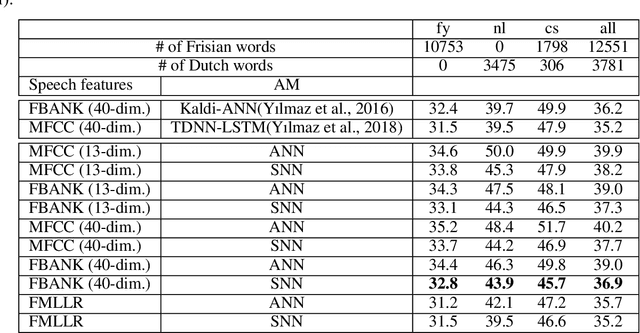
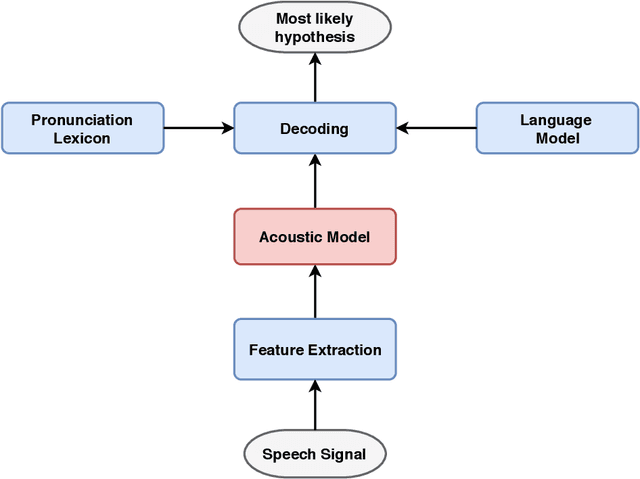
Artificial neural networks (ANN) have become the mainstream acoustic modeling technique for large vocabulary automatic speech recognition (ASR). A conventional ANN features a multi-layer architecture that requires massive amounts of computation. The brain-inspired spiking neural networks (SNN) closely mimic the biological neural networks and can operate on low-power neuromorphic hardware with spike-based computation. Motivated by their unprecedented energyefficiency and rapid information processing capability, we explore the use of SNNs for speech recognition. In this work, we use SNNs for acoustic modeling and evaluate their performance on several large vocabulary recognition scenarios. The experimental results demonstrate competitive ASR accuracies to their ANN counterparts, while require significantly reduced computational cost and inference time. Integrating the algorithmic power of deep SNNs with energy-efficient neuromorphic hardware, therefore, offer an attractive solution for ASR applications running locally on mobile and embedded devices.
Locally Differentially Private Naive Bayes Classification
May 03, 2019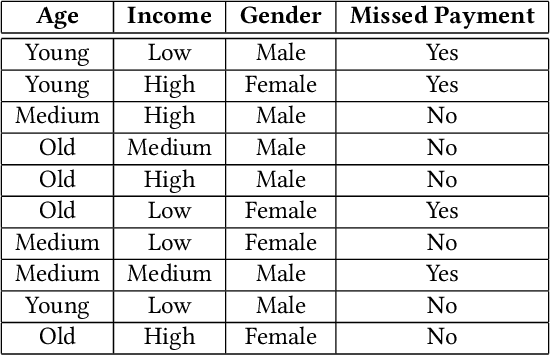
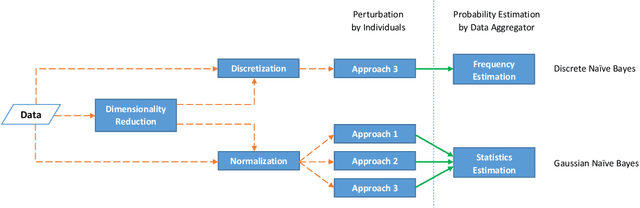
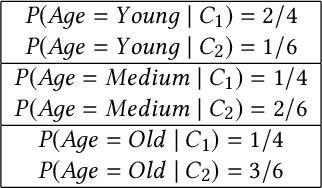
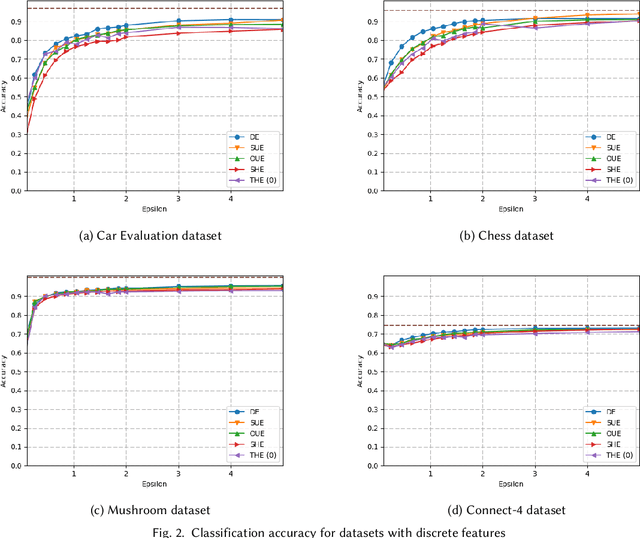
In machine learning, classification models need to be trained in order to predict class labels. When the training data contains personal information about individuals, collecting training data becomes difficult due to privacy concerns. Local differential privacy is a definition to measure the individual privacy when there is no trusted data curator. Individuals interact with an untrusted data aggregator who obtains statistical information about the population without learning personal data. In order to train a Naive Bayes classifier in an untrusted setting, we propose to use methods satisfying local differential privacy. Individuals send their perturbed inputs that keep the relationship between the feature values and class labels. The data aggregator estimates all probabilities needed by the Naive Bayes classifier. Then, new instances can be classified based on the estimated probabilities. We propose solutions for both discrete and continuous data. In order to eliminate high amount of noise and decrease communication cost in multi-dimensional data, we propose utilizing dimensionality reduction techniques which can be applied by individuals before perturbing their inputs. Our experimental results show that the accuracy of the Naive Bayes classifier is maintained even when the individual privacy is guaranteed under local differential privacy, and that using dimensionality reduction enhances the accuracy.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019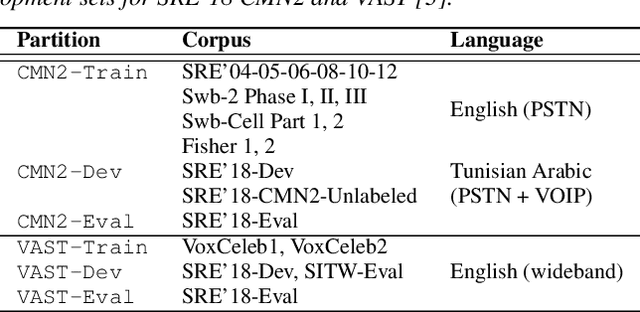
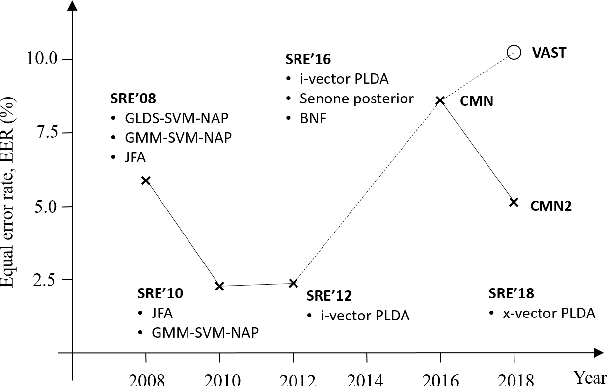
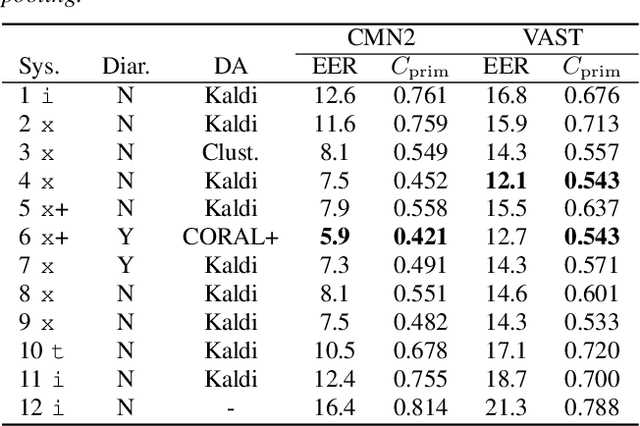
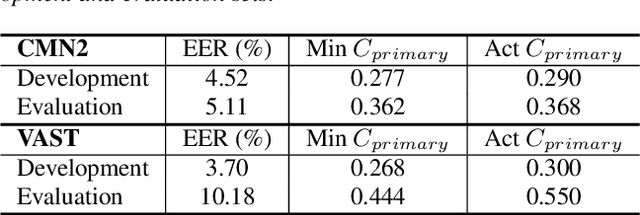
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
ASR-free CNN-DTW keyword spotting using multilingual bottleneck features for almost zero-resource languages
Jul 23, 2018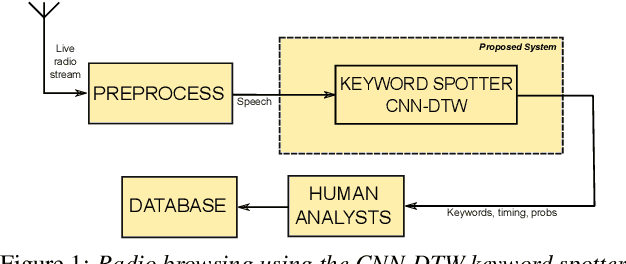
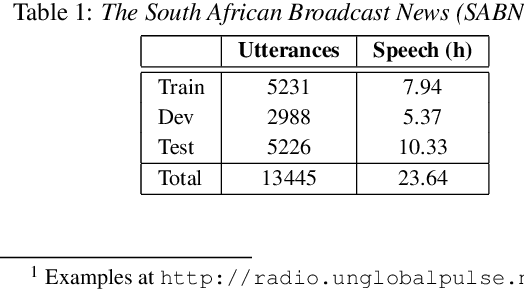
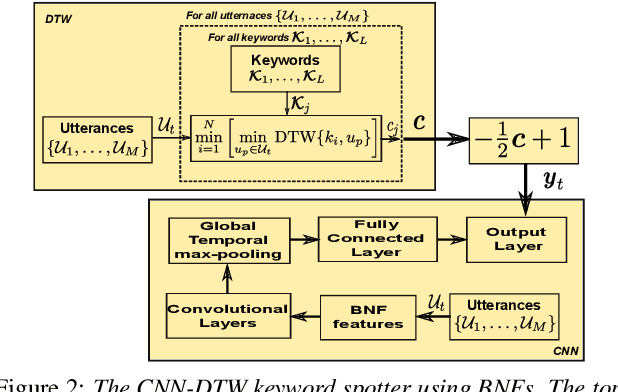
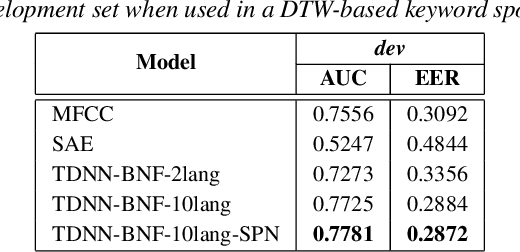
We consider multilingual bottleneck features (BNFs) for nearly zero-resource keyword spotting. This forms part of a United Nations effort using keyword spotting to support humanitarian relief programmes in parts of Africa where languages are severely under-resourced. We use 1920 isolated keywords (40 types, 34 minutes) as exemplars for dynamic time warping (DTW) template matching, which is performed on a much larger body of untranscribed speech. These DTW costs are used as targets for a convolutional neural network (CNN) keyword spotter, giving a much faster system than direct DTW. Here we consider how available data from well-resourced languages can improve this CNN-DTW approach. We show that multilingual BNFs trained on ten languages improve the area under the ROC curve of a CNN-DTW system by 10.9% absolute relative to the MFCC baseline. By combining low-resource DTW-based supervision with information from well-resourced languages, CNN-DTW is a competitive option for low-resource keyword spotting.