 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCough activity detection for automatic tuberculosis screening
Mar 11, 2026The automatic identification of cough segments in audio through the determination of start and end points is pivotal to building scalable screening tools in health technologies for pulmonary related diseases. We propose the application of two current pre-trained architectures to the task of cough activity detection. A dataset of recordings containing cough from patients symptomatic for tuberculosis (TB) who self-present at community-level care centres in South Africa and Uganda is employed. When automatic start and end points are determined using XLS-R, an average precision of 0.96 and an area under the receiver-operating characteristic of 0.99 are achieved for the test set. We show that best average precision is achieved by utilising only the first three layers of the network, which has the dual benefits of reduced computational and memory requirements, pivotal for smartphone-based applications. This XLS-R configuration is shown to outperform an audio spectrogram transformer (AST) as well as a logistic regression baseline by 9% and 27% absolute in test set average precision respectively. Furthermore, a downstream TB classification model trained using the coughs automatically isolated by XLS-R comfortably outperforms a model trained on the coughs isolated by AST, and is only narrowly outperformed by a classifier trained on the ground truth coughs. We conclude that the application of large pre-trained transformer models is an effective approach to identifying cough end-points and that the integration of such a model into a screening tool is feasible.
Fine-Tuned Self-Supervised Speech Representations for Language Diarization in Multilingual Code-Switched Speech
Dec 15, 2023Annotating a multilingual code-switched corpus is a painstaking process requiring specialist linguistic expertise. This is partly due to the large number of language combinations that may appear within and across utterances, which might require several annotators with different linguistic expertise to consider an utterance sequentially. This is time-consuming and costly. It would be useful if the spoken languages in an utterance and the boundaries thereof were known before annotation commences, to allow segments to be assigned to the relevant language experts in parallel. To address this, we investigate the development of a continuous multilingual language diarizer using fine-tuned speech representations extracted from a large pre-trained self-supervised architecture (WavLM). We experiment with a code-switched corpus consisting of five South African languages (isiZulu, isiXhosa, Setswana, Sesotho and English) and show substantial diarization error rate improvements for language families, language groups, and individual languages over baseline systems.
TB or not TB? Acoustic cough analysis for tuberculosis classification
Sep 02, 2022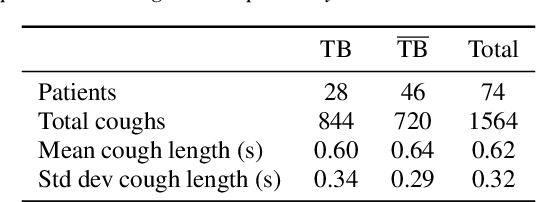
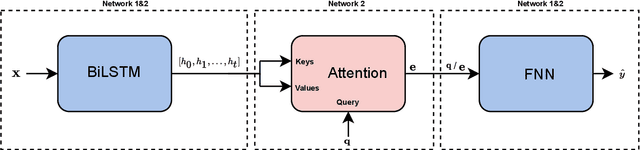
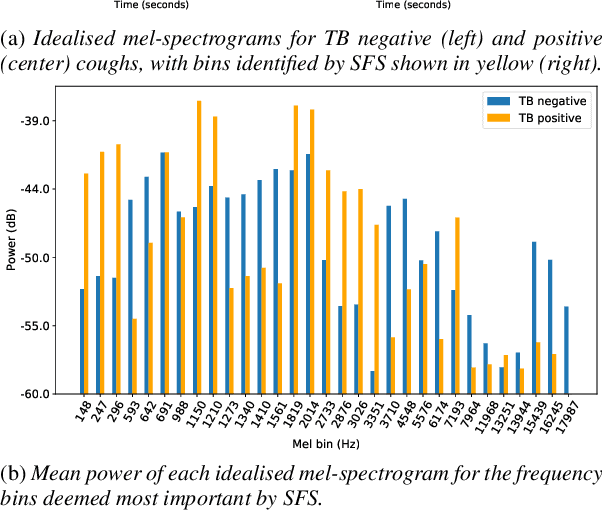
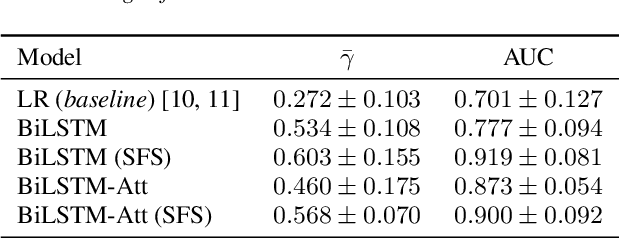
In this work, we explore recurrent neural network architectures for tuberculosis (TB) cough classification. In contrast to previous unsuccessful attempts to implement deep architectures in this domain, we show that a basic bidirectional long short-term memory network (BiLSTM) can achieve improved performance. In addition, we show that by performing greedy feature selection in conjunction with a newly-proposed attention-based architecture that learns patient invariant features, substantially better generalisation can be achieved compared to a baseline and other considered architectures. Furthermore, this attention mechanism allows an inspection of the temporal regions of the audio signal considered to be important for classification to be performed. Finally, we develop a neural style transfer technique to infer idealised inputs which can subsequently be analysed. We find distinct differences between the idealised power spectra of TB and non-TB coughs, which provide clues about the origin of the features in the audio signal.
Automatic Tuberculosis and COVID-19 cough classification using deep learning
May 11, 2022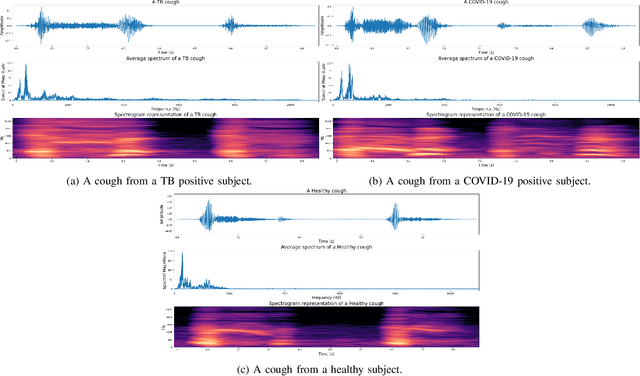
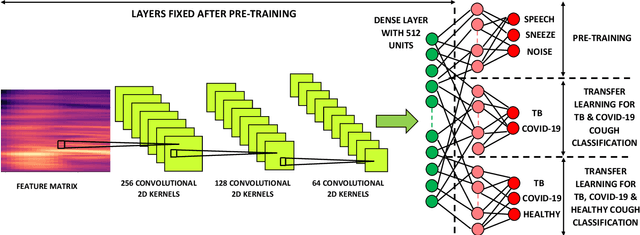
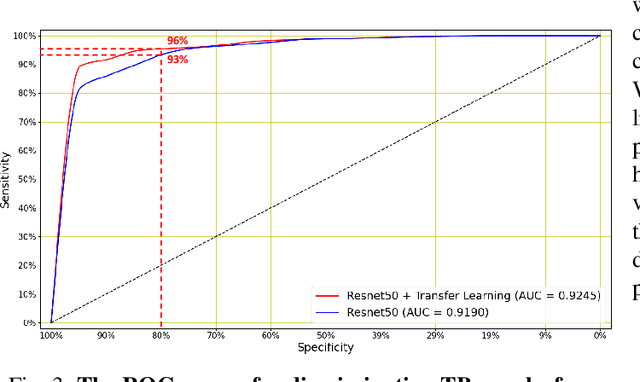
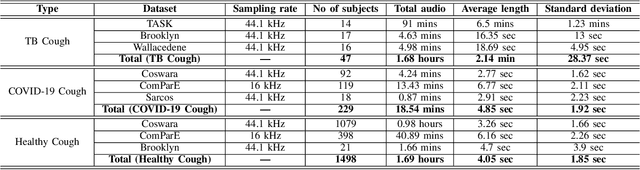
We present a deep learning based automatic cough classifier which can discriminate tuberculosis (TB) coughs from COVID-19 coughs and healthy coughs. Both TB and COVID-19 are respiratory disease, have cough as a predominant symptom and claim thousands of lives each year. The cough audio recordings were collected at both indoor and outdoor settings and also uploaded using smartphones from subjects around the globe, thus contain various levels of noise. This cough data include 1.68 hours of TB coughs, 18.54 minutes of COVID-19 coughs and 1.69 hours of healthy coughs from 47 TB patients, 229 COVID-19 patients and 1498 healthy patients and were used to train and evaluate a CNN, LSTM and Resnet50. These three deep architectures were also pre-trained on 2.14 hours of sneeze, 2.91 hours of speech and 2.79 hours of noise for improved performance. The class-imbalance in our dataset was addressed by using SMOTE data balancing technique and using performance metrics such as F1-score and AUC. Our study shows that the highest F1-scores of 0.9259 and 0.8631 have been achieved from a pre-trained Resnet50 for two-class (TB vs COVID-19) and three-class (TB vs COVID-19 vs healthy) cough classification tasks, respectively. The application of deep transfer learning has improved the classifiers' performance and makes them more robust as they generalise better over the cross-validation folds. Their performances exceed the TB triage test requirements set by the world health organisation (WHO). The features producing the best performance contain higher order of MFCCs suggesting that the differences between TB and COVID-19 coughs are not perceivable by the human ear. This type of cough audio classification is non-contact, cost-effective and can easily be deployed on a smartphone, thus it can be an excellent tool for both TB and COVID-19 screening.
Accelerometer-based Bed Occupancy Detection for Automatic, Non-invasive Long-term Cough Monitoring
Feb 08, 2022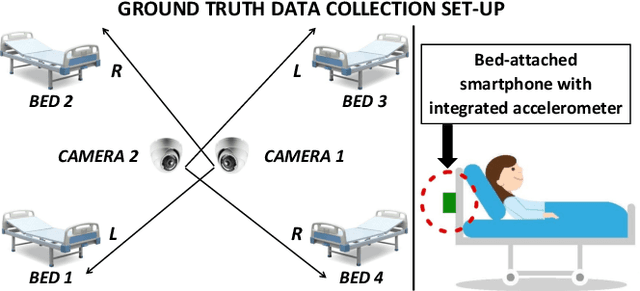
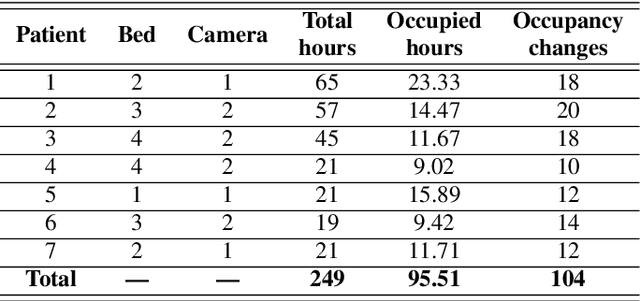

We present a machine learning based long-term cough monitoring system by detecting patient's bed occupancy from a bed-attached smartphone-inbuilt accelerometer automatically. Previously this system was used to detect cough events successfully and long-term cough monitoring requires bed occupancy detection, as the initial experiments show that patients leave their bed very often for long period of time and using video-monitoring or pressure sensors are not patient-favourite alternatives. We have compiled a 249-hour dataset of manually-labelled acceleration signals gathered from seven adult male patients undergoing treatment for tuberculosis (TB). The bed occupancy detection process consists of three detectors, among which the first one classifies occupancy-change with high sensitivity, low specificity and the second one classifies occupancy-interval with high specificity, low sensitivity. The final state detector corrects the miss-classified sections. After using a leave-one-patient-out cross-validation scheme to train and evaluate four classifiers such as LR, MLP, CNN and LSTM; LSTM produces the highest area under the curve (AUC) of 0.94 while comparing the predicted bed occupancy as the output from the final state detector with the actual bed occupancy sample by sample. We have also calculated colony forming unit and time to positivity of the sputum samples of TB positive patients who were monitored for 14 days and the proposed system was used to predict daily cough rates. The results show that patients who improve under TB treatment have decreasing daily cough rates, indicating the proposed automatic, quick, non-invasive, non-intrusive, cost-effective long-term cough monitoring system can be extremely useful in monitoring patients' recovery rate.
Wake-Cough: cough spotting and cougher identification for personalised long-term cough monitoring
Oct 07, 2021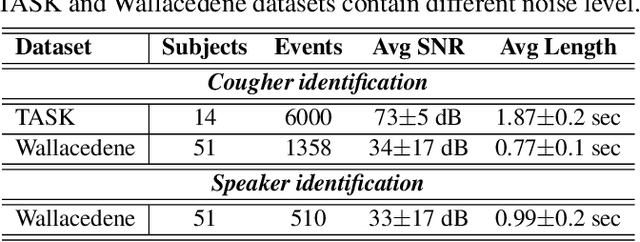

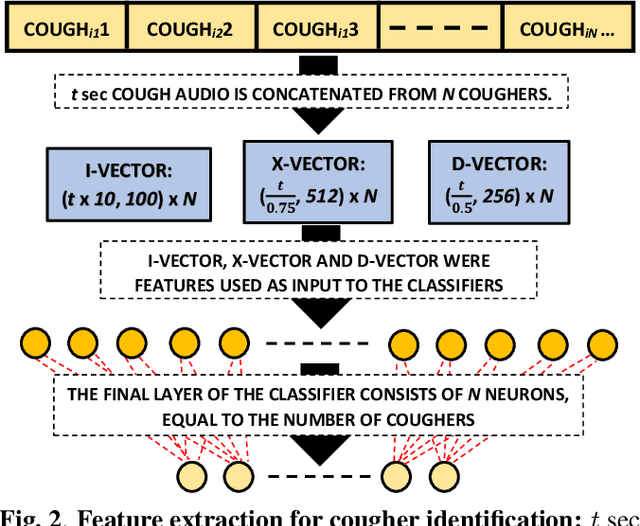
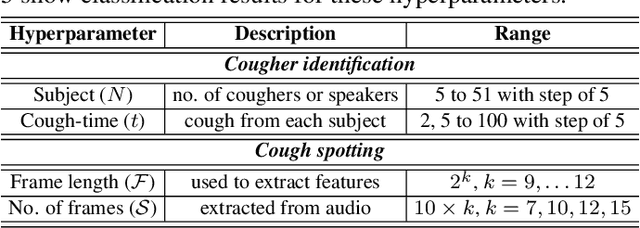
We present 'wake-cough', an application of wake-word spotting to coughs using Resnet50 and identifying coughers using i-vectors, for the purpose of a long-term, personalised cough monitoring system. Coughs, recorded in a quiet (73$\pm$5 dB) and noisy (34$\pm$17 dB) environment, were used to extract i-vectors, x-vectors and d-vectors, used as features to the classifiers. The system achieves 90.02\% accuracy from an MLP to discriminate 51 coughers using 2-sec long cough segments in the noisy environment. When discriminating between 5 and 14 coughers using longer (100 sec) segments in the quiet environment, this accuracy rises to 99.78\% and 98.39\% respectively. Unlike speech, i-vectors outperform x-vectors and d-vectors in identifying coughers. These coughs were added as an extra class in the Google Speech Commands dataset and features were extracted by preserving the end-to-end time-domain information in an event. The highest accuracy of 88.58\% is achieved in spotting coughs among 35 other trigger phrases using a Resnet50. Wake-cough represents a personalised, non-intrusive, cough monitoring system, which is power efficient as using wake-word detection method can keep a smartphone-based monitoring device mostly dormant. This makes wake-cough extremely attractive in multi-bed ward environments to monitor patient's long-term recovery from lung ailments such as tuberculosis and COVID-19.
Automatic non-invasive Cough Detection based on Accelerometer and Audio Signals
Aug 31, 2021
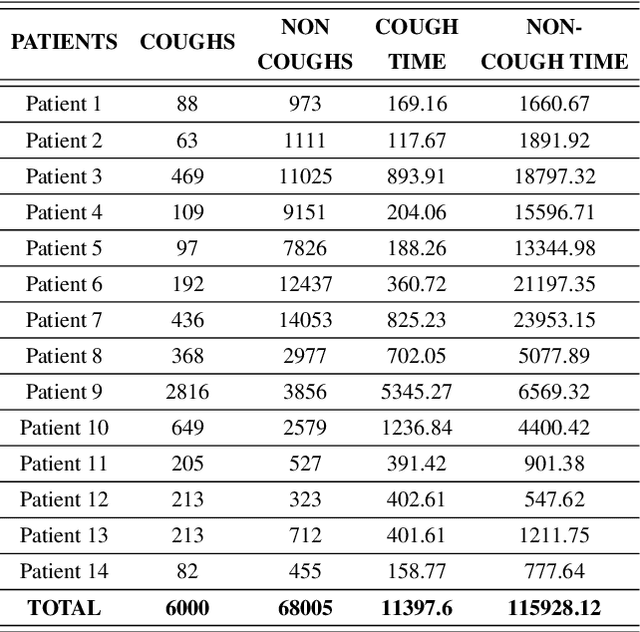
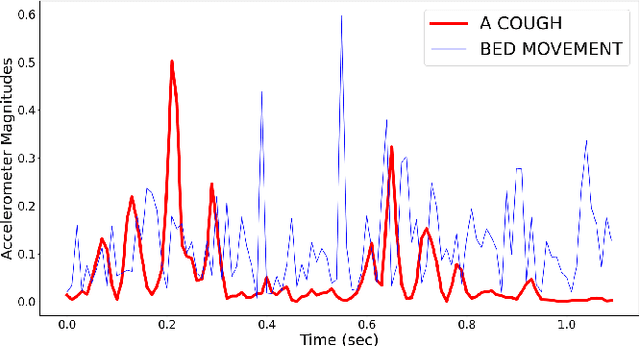
We present an automatic non-invasive way of detecting cough events based on both accelerometer and audio signals. The acceleration signals are captured by a smartphone firmly attached to the patient's bed, using its integrated accelerometer. The audio signals are captured simultaneously by the same smartphone using an external microphone. We have compiled a manually-annotated dataset containing such simultaneously-captured acceleration and audio signals for approximately 6000 cough and 68000 non-cough events from 14 adult male patients in a tuberculosis clinic. LR, SVM and MLP are evaluated as baseline classifiers and compared with deep architectures such as CNN, LSTM, and Resnet50 using a leave-one-out cross-validation scheme. We find that the studied classifiers can use either acceleration or audio signals to distinguish between coughing and other activities including sneezing, throat-clearing, and movement on the bed with high accuracy. However, in all cases, the deep neural networks outperform the shallow classifiers by a clear margin and the Resnet50 offers the best performance by achieving an AUC exceeding 0.98 and 0.99 for acceleration and audio signals respectively. While audio-based classification consistently offers a better performance than acceleration-based classification, we observe that the difference is very small for the best systems. Since the acceleration signal requires less processing power, and since the need to record audio is sidestepped and thus privacy is inherently secured, and since the recording device is attached to the bed and not worn, an accelerometer-based highly accurate non-invasive cough detector may represent a more convenient and readily accepted method in long-term cough monitoring.
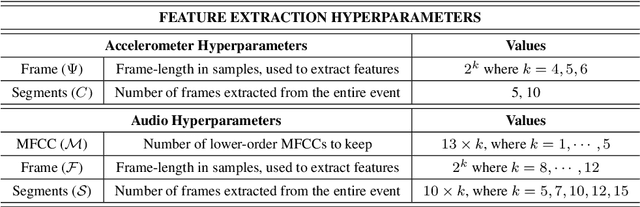
Feature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021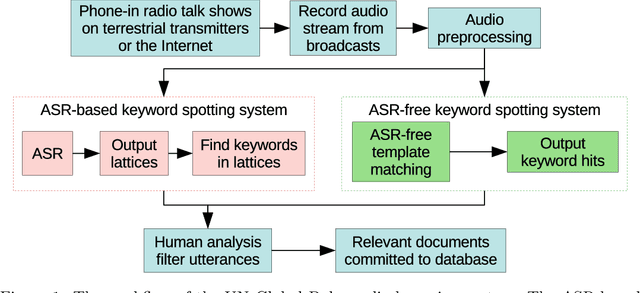
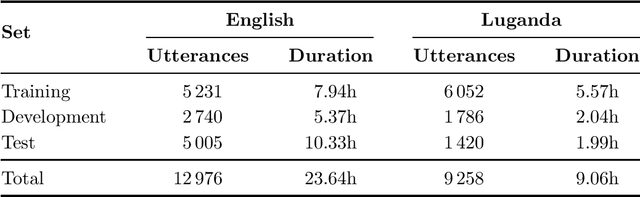

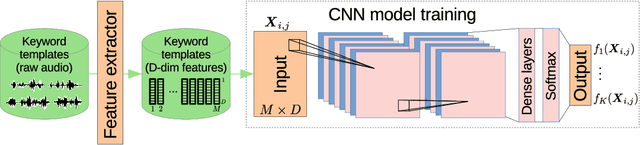
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.
Multilingual training set selection for ASR in under-resourced Malian languages
Aug 13, 2021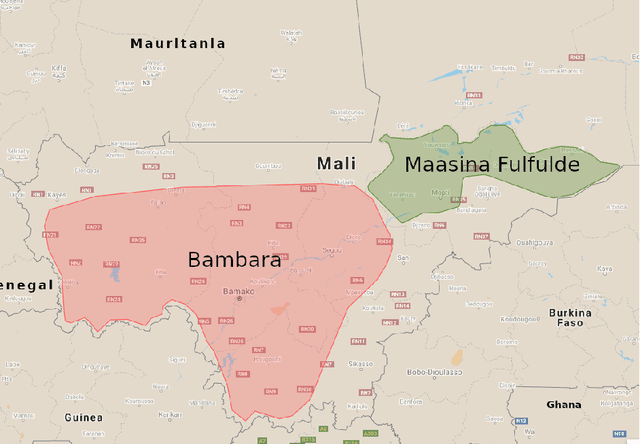

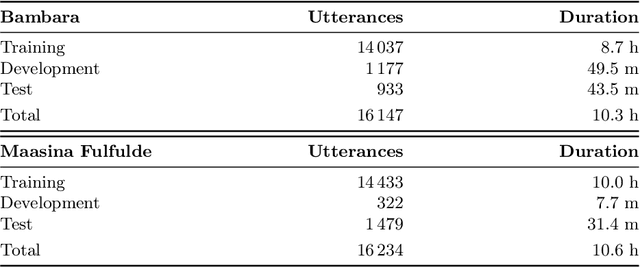
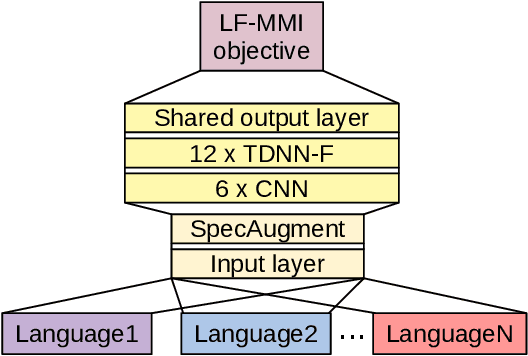
We present first speech recognition systems for the two severely under-resourced Malian languages Bambara and Maasina Fulfulde. These systems will be used by the United Nations as part of a monitoring system to inform and support humanitarian programmes in rural Africa. We have compiled datasets in Bambara and Maasina Fulfulde, but since these are very small, we take advantage of six similarly under-resourced datasets in other languages for multilingual training. We focus specifically on the best composition of the multilingual pool of speech data for multilingual training. We find that, although maximising the training pool by including all six additional languages provides improved speech recognition in both target languages, substantially better performance can be achieved by a more judicious choice. Our experiments show that the addition of just one language provides best performance. For Bambara, this additional language is Maasina Fulfulde, and its introduction leads to a relative word error rate reduction of 6.7%, as opposed to a 2.4% relative reduction achieved when pooling all six additional languages. For the case of Maasina Fulfulde, best performance was achieved when adding only Luganda, leading to a relative word error rate improvement of 9.4% as opposed to a 3.9% relative improvement when pooling all six languages. We conclude that careful selection of the out-of-language data is worthwhile for multilingual training even in highly under-resourced settings, and that the general assumption that more data is better does not always hold.
Machine Learning based COVID-19 Detection from Smartphone Recordings: Cough, Breath and Speech
Apr 12, 2021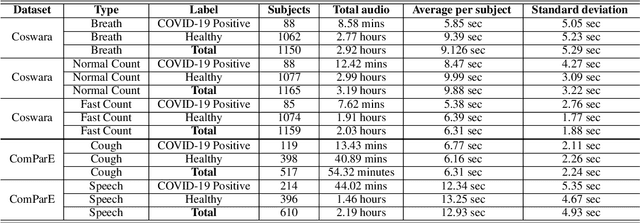
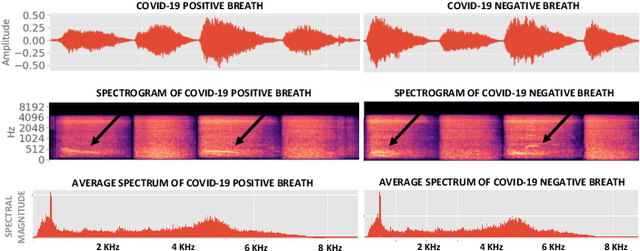
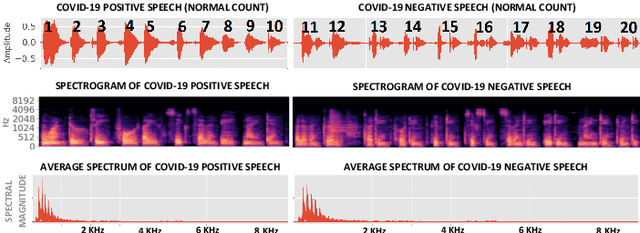
We present an experimental investigation into the automatic detection of COVID-19 from smartphone recordings of coughs, breaths and speech. This type of screening is attractive because it is non-contact, does not require specialist medical expertise or laboratory facilities and can easily be deployed on inexpensive consumer hardware. We base our experiments on two datasets, Coswara and ComParE, containing recordings of coughing, breathing and speech from subjects around the globe. We have considered seven machine learning classifiers and all of them are trained and evaluated using leave-p-out cross-validation. For the Coswara data, the highest AUC of 0.92 was achieved using a Resnet50 architecture on breaths. For the ComParE data, the highest AUC of 0.93 was achieved using a k-nearest neighbours (KNN) classifier on cough recordings after selecting the best 12 features using sequential forward selection (SFS) and the highest AUC of 0.91 was also achieved on speech by a multilayer perceptron (MLP) when using SFS to select the best 23 features. We conclude that among all vocal audio, coughs carry the strongest COVID-19 signature followed by breath and speech. Although these signatures are not perceivable by human ear, machine learning based COVID-19 detection is possible from vocal audio recorded via smartphone.