 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned Self-Supervised Speech Representations for Language Diarization in Multilingual Code-Switched Speech
Dec 15, 2023Annotating a multilingual code-switched corpus is a painstaking process requiring specialist linguistic expertise. This is partly due to the large number of language combinations that may appear within and across utterances, which might require several annotators with different linguistic expertise to consider an utterance sequentially. This is time-consuming and costly. It would be useful if the spoken languages in an utterance and the boundaries thereof were known before annotation commences, to allow segments to be assigned to the relevant language experts in parallel. To address this, we investigate the development of a continuous multilingual language diarizer using fine-tuned speech representations extracted from a large pre-trained self-supervised architecture (WavLM). We experiment with a code-switched corpus consisting of five South African languages (isiZulu, isiXhosa, Setswana, Sesotho and English) and show substantial diarization error rate improvements for language families, language groups, and individual languages over baseline systems.
TB or not TB? Acoustic cough analysis for tuberculosis classification
Sep 02, 2022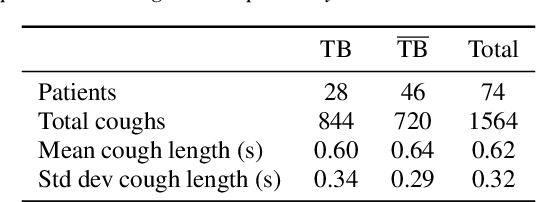
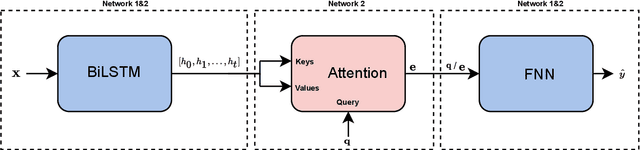
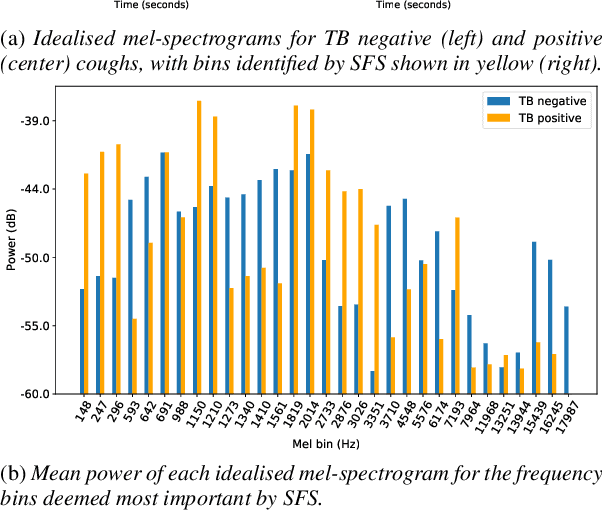
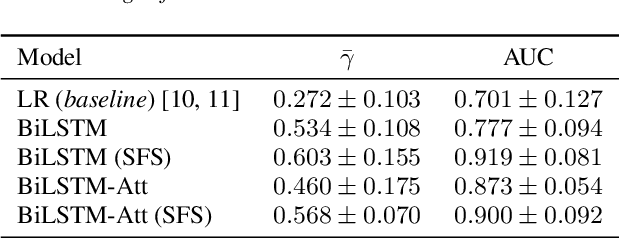
In this work, we explore recurrent neural network architectures for tuberculosis (TB) cough classification. In contrast to previous unsuccessful attempts to implement deep architectures in this domain, we show that a basic bidirectional long short-term memory network (BiLSTM) can achieve improved performance. In addition, we show that by performing greedy feature selection in conjunction with a newly-proposed attention-based architecture that learns patient invariant features, substantially better generalisation can be achieved compared to a baseline and other considered architectures. Furthermore, this attention mechanism allows an inspection of the temporal regions of the audio signal considered to be important for classification to be performed. Finally, we develop a neural style transfer technique to infer idealised inputs which can subsequently be analysed. We find distinct differences between the idealised power spectra of TB and non-TB coughs, which provide clues about the origin of the features in the audio signal.