 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature learning for efficient ASR-free keyword spotting in low-resource languages
Aug 13, 2021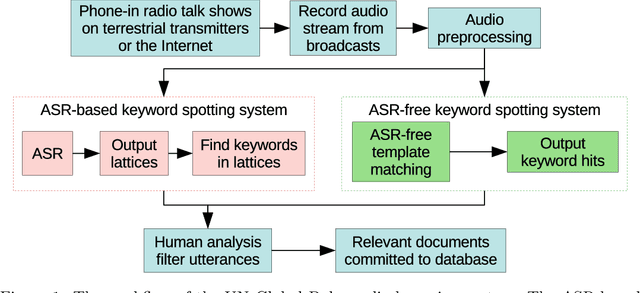
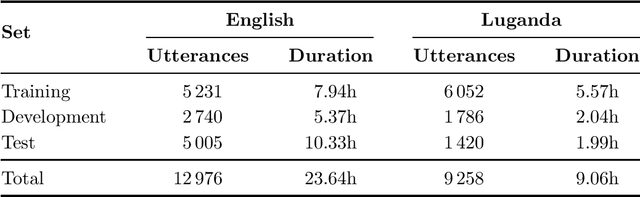

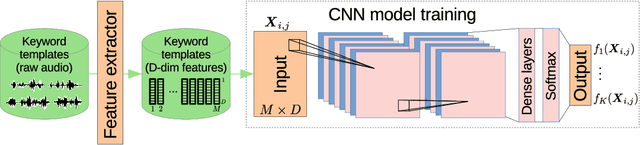
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.
Multilingual training set selection for ASR in under-resourced Malian languages
Aug 13, 2021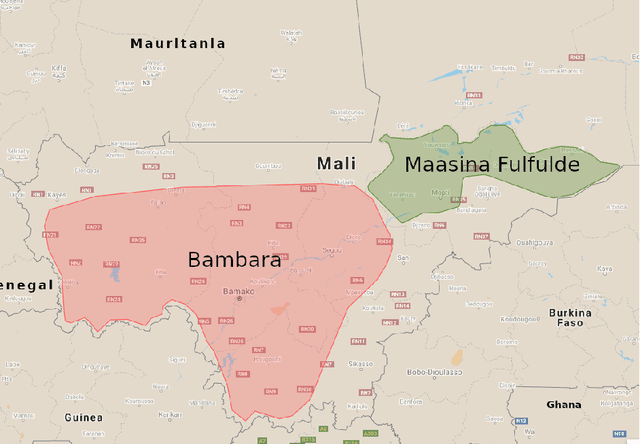

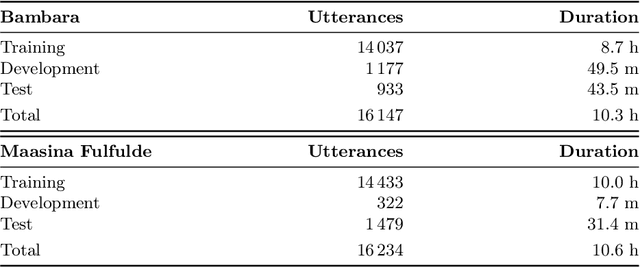
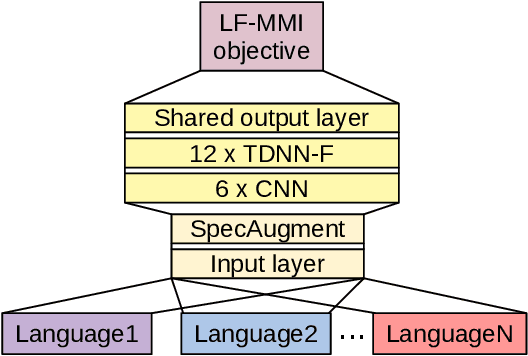
We present first speech recognition systems for the two severely under-resourced Malian languages Bambara and Maasina Fulfulde. These systems will be used by the United Nations as part of a monitoring system to inform and support humanitarian programmes in rural Africa. We have compiled datasets in Bambara and Maasina Fulfulde, but since these are very small, we take advantage of six similarly under-resourced datasets in other languages for multilingual training. We focus specifically on the best composition of the multilingual pool of speech data for multilingual training. We find that, although maximising the training pool by including all six additional languages provides improved speech recognition in both target languages, substantially better performance can be achieved by a more judicious choice. Our experiments show that the addition of just one language provides best performance. For Bambara, this additional language is Maasina Fulfulde, and its introduction leads to a relative word error rate reduction of 6.7%, as opposed to a 2.4% relative reduction achieved when pooling all six additional languages. For the case of Maasina Fulfulde, best performance was achieved when adding only Luganda, leading to a relative word error rate improvement of 9.4% as opposed to a 3.9% relative improvement when pooling all six languages. We conclude that careful selection of the out-of-language data is worthwhile for multilingual training even in highly under-resourced settings, and that the general assumption that more data is better does not always hold.
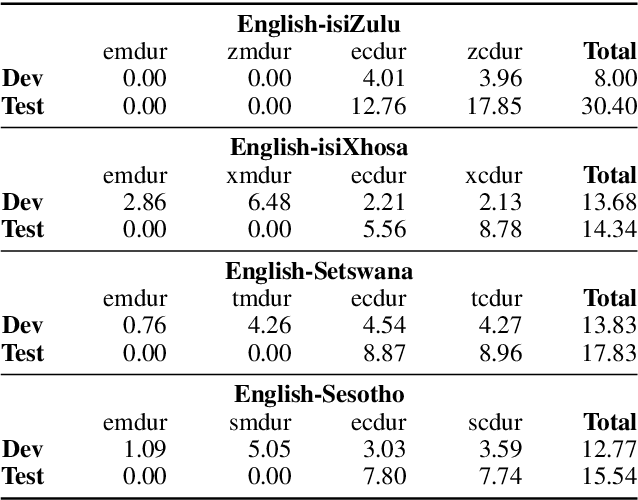
Multilingual Bottleneck Features for Improving ASR Performance of Code-Switched Speech in Under-Resourced Languages
Oct 31, 2020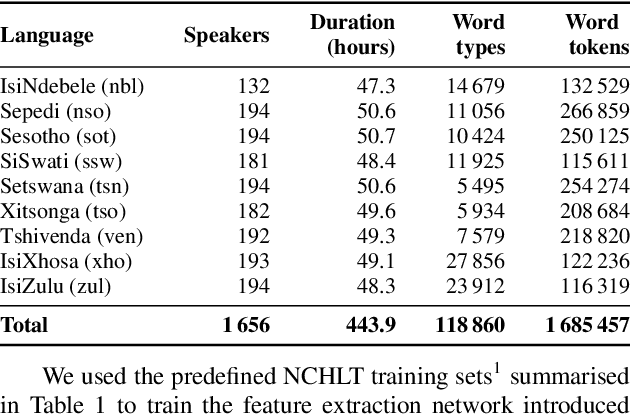
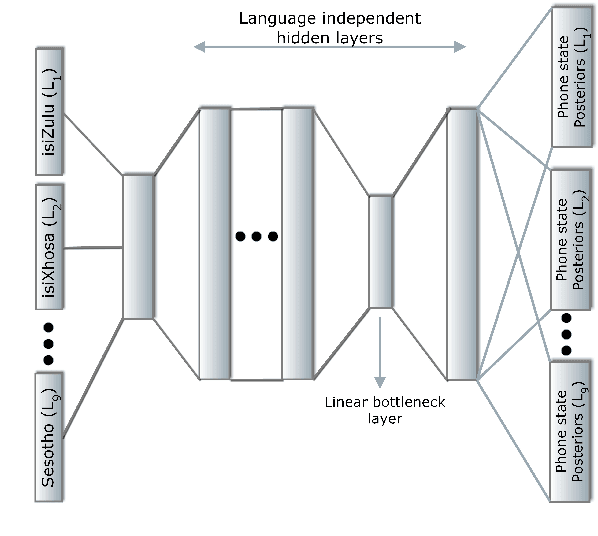
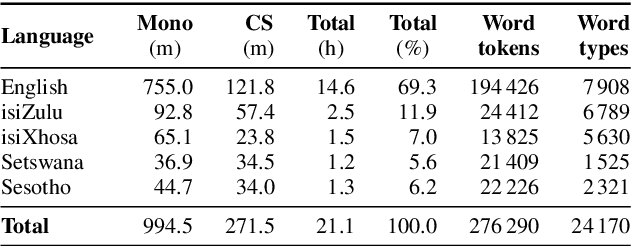
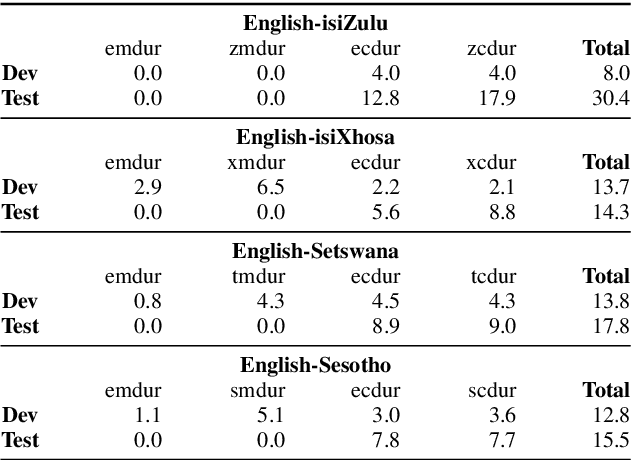
In this work, we explore the benefits of using multilingual bottleneck features (mBNF) in acoustic modelling for the automatic speech recognition of code-switched (CS) speech in African languages. The unavailability of annotated corpora in the languages of interest has always been a primary challenge when developing speech recognition systems for this severely under-resourced type of speech. Hence, it is worthwhile to investigate the potential of using speech corpora available for other better-resourced languages to improve speech recognition performance. To achieve this, we train a mBNF extractor using nine Southern Bantu languages that form part of the freely available multilingual NCHLT corpus. We append these mBNFs to the existing MFCCs, pitch features and i-vectors to train acoustic models for automatic speech recognition (ASR) in the target code-switched languages. Our results show that the inclusion of the mBNF features leads to clear performance improvements over a baseline trained without the mBNFs for code-switched English-isiZulu, English-isiXhosa, English-Sesotho and English-Setswana speech.
* In Proceedings of The First Workshop on Speech Technologies for Code-Switching in Multilingual Communities
Semi-supervised Development of ASR Systems for Multilingual Code-switched Speech in Under-resourced Languages
Mar 06, 2020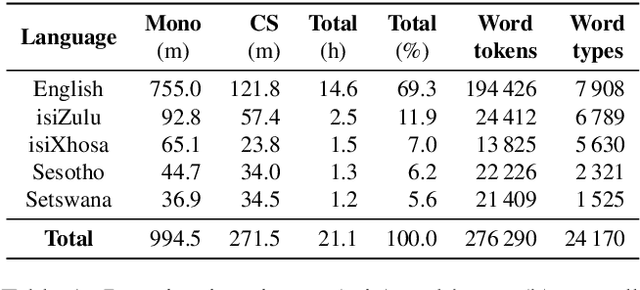
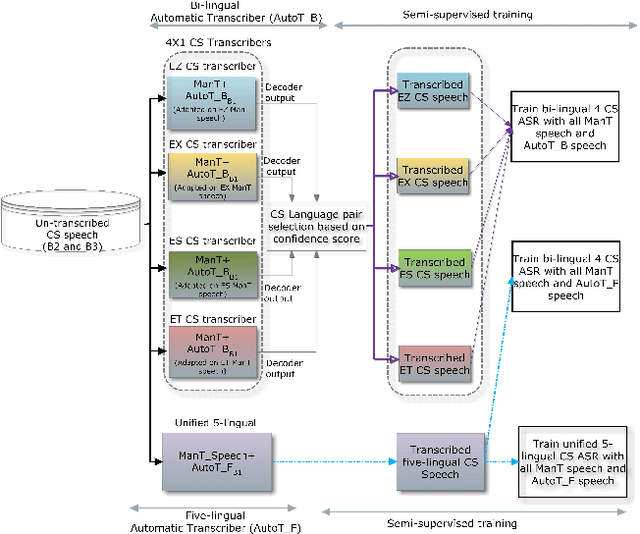
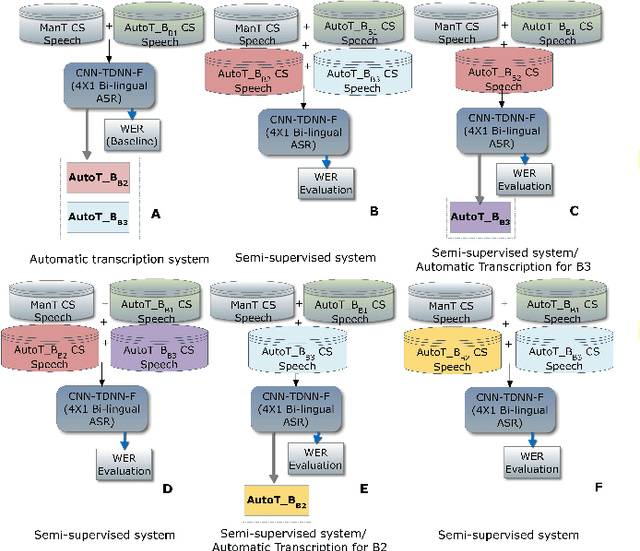
This paper reports on the semi-supervised development of acoustic and language models for under-resourced, code-switched speech in five South African languages. Two approaches are considered. The first constructs four separate bilingual automatic speech recognisers (ASRs) corresponding to four different language pairs between which speakers switch frequently. The second uses a single, unified, five-lingual ASR system that represents all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). We evaluate the effectiveness of these two approaches when used to add additional data to our extremely sparse training sets. Results indicate that batch-wise semi-supervised training yields better results than a non-batch-wise approach. Furthermore, while the separate bilingual systems achieved better recognition performance than the unified system, they benefited more from pseudo-labels generated by the five-lingual system than from those generated by the bilingual systems.
Improved low-resource Somali speech recognition by semi-supervised acoustic and language model training
Jul 06, 2019
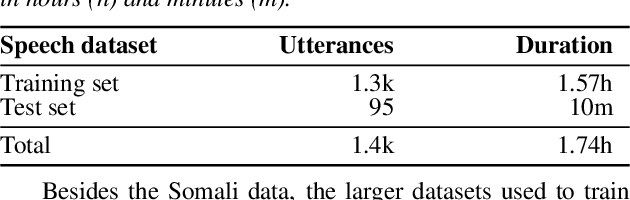
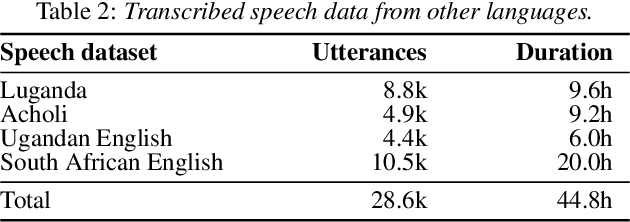
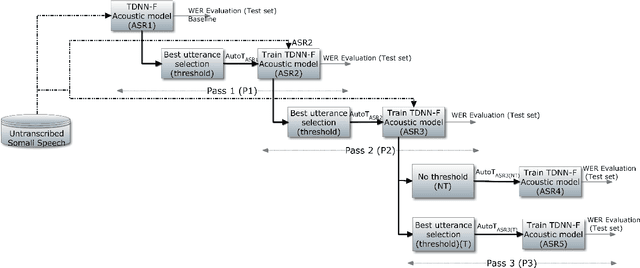
We present improvements in automatic speech recognition (ASR) for Somali, a currently extremely under-resourced language. This forms part of a continuing United Nations (UN) effort to employ ASR-based keyword spotting systems to support humanitarian relief programmes in rural Africa. Using just 1.57 hours of annotated speech data as a seed corpus, we increase the pool of training data by applying semi-supervised training to 17.55 hours of untranscribed speech. We make use of factorised time-delay neural networks (TDNN-F) for acoustic modelling, since these have recently been shown to be effective in resource-scarce situations. Three semi-supervised training passes were performed, where the decoded output from each pass was used for acoustic model training in the subsequent pass. The automatic transcriptions from the best performing pass were used for language model augmentation. To ensure the quality of automatic transcriptions, decoder confidence is used as a threshold. The acoustic and language models obtained from the semi-supervised approach show significant improvement in terms of WER and perplexity compared to the baseline. Incorporating the automatically generated transcriptions yields a 6.55\% improvement in language model perplexity. The use of 17.55 hour of Somali acoustic data in semi-supervised training shows an improvement of 7.74\% relative over the baseline.
Semi-supervised acoustic model training for five-lingual code-switched ASR
Jun 20, 2019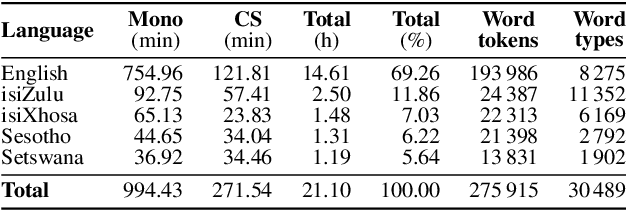
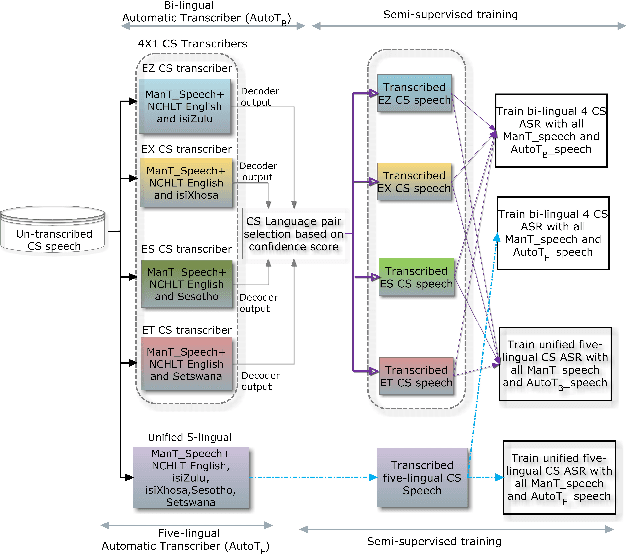
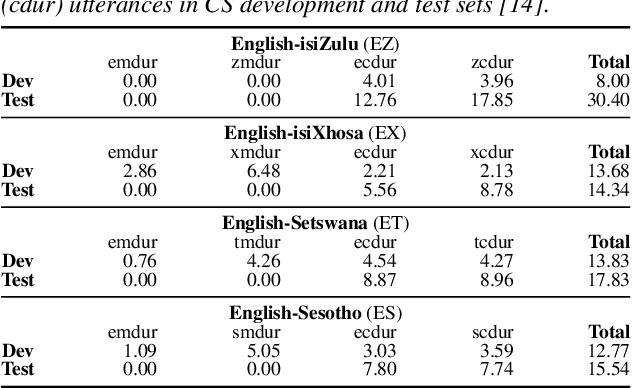
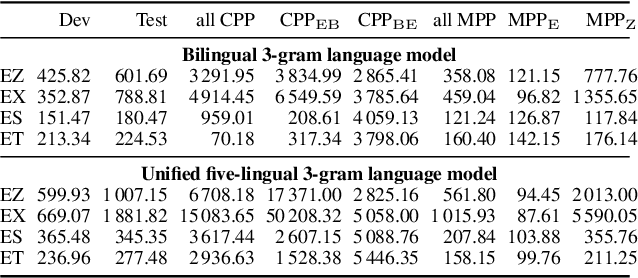
This paper presents recent progress in the acoustic modelling of under-resourced code-switched (CS) speech in multiple South African languages. We consider two approaches. The first constructs separate bilingual acoustic models corresponding to language pairs (English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho). The second constructs a single unified five-lingual acoustic model representing all the languages (English, isiZulu, isiXhosa, Setswana and Sesotho). For these two approaches we consider the effectiveness of semi-supervised training to increase the size of the very sparse acoustic training sets. Using approximately 11 hours of untranscribed speech, we show that both approaches benefit from semi-supervised training. The bilingual TDNN-F acoustic models also benefit from the addition of CNN layers (CNN-TDNN-F), while the five-lingual system does not show any significant improvement. Furthermore, because English is common to all language pairs in our data, it dominates when training a unified language model, leading to improved English ASR performance at the expense of the other languages. Nevertheless, the five-lingual model offers flexibility because it can process more than two languages simultaneously, and is therefore an attractive option as an automatic transcription system in a semi-supervised training pipeline.
Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks
Apr 16, 2019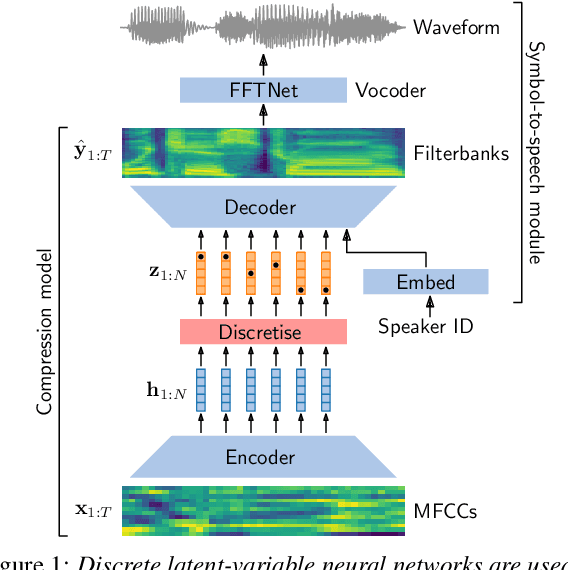

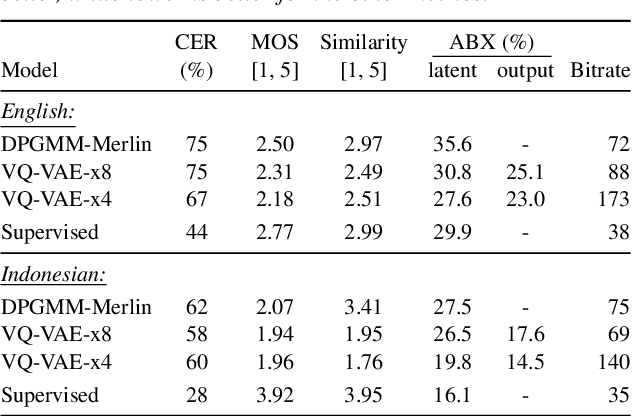
For our submission to the ZeroSpeech 2019 challenge, we apply discrete latent-variable neural networks to unlabelled speech and use the discovered units for speech synthesis. Unsupervised discrete subword modelling could be useful for studies of phonetic category learning in infants or in low-resource speech technology requiring symbolic input. We use an autoencoder (AE) architecture with intermediate discretisation. We decouple acoustic unit discovery from speaker modelling by conditioning the AE's decoder on the training speaker identity. At test time, unit discovery is performed on speech from an unseen speaker, followed by unit decoding conditioned on a known target speaker to obtain reconstructed filterbanks. This output is fed to a neural vocoder to synthesise speech in the target speaker's voice. For discretisation, categorical variational autoencoders (CatVAEs), vector-quantised VAEs (VQ-VAEs) and straight-through estimation are compared at different compression levels on two languages. Our final model uses convolutional encoding, VQ-VAE discretisation, deconvolutional decoding and an FFTNet vocoder. We show that decoupled speaker conditioning intrinsically improves discrete acoustic representations, yielding competitive synthesis quality compared to the challenge baseline.
Building a Unified Code-Switching ASR System for South African Languages
Jul 28, 2018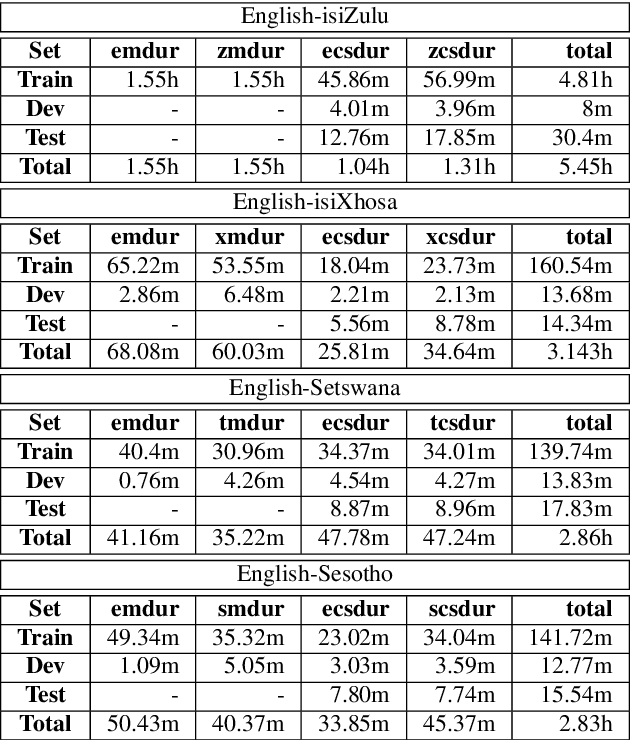
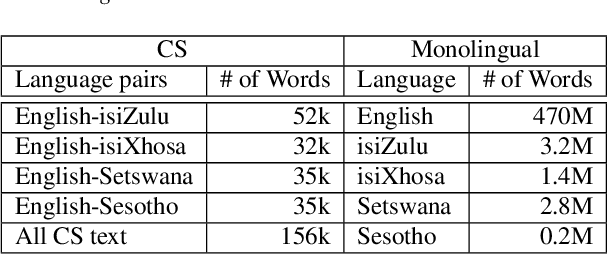
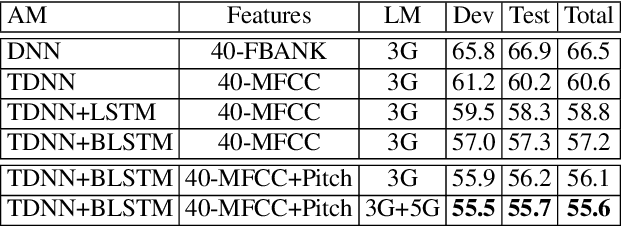

We present our first efforts towards building a single multilingual automatic speech recognition (ASR) system that can process code-switching (CS) speech in five languages spoken within the same population. This contrasts with related prior work which focuses on the recognition of CS speech in bilingual scenarios. Recently, we have compiled a small five-language corpus of South African soap opera speech which contains examples of CS between 5 languages occurring in various contexts such as using English as the matrix language and switching to other indigenous languages. The ASR system presented in this work is trained on 4 corpora containing English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho CS speech. The interpolation of multiple language models trained on these language pairs enables the ASR system to hypothesize mixed word sequences from these 5 languages. We evaluate various state-of-the-art acoustic models trained on this 5-lingual training data and report ASR accuracy and language recognition performance on the development and test sets of the South African multilingual soap opera corpus.