 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep motion estimation for parallel inter-frame prediction in video compression
Dec 11, 2019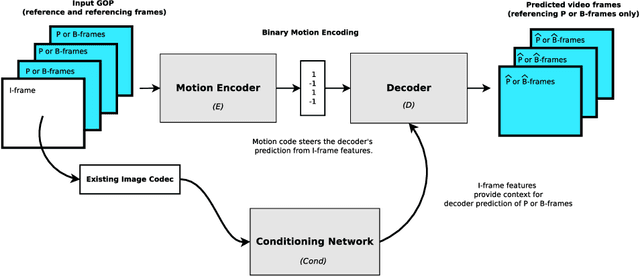
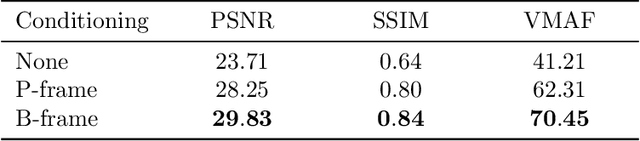
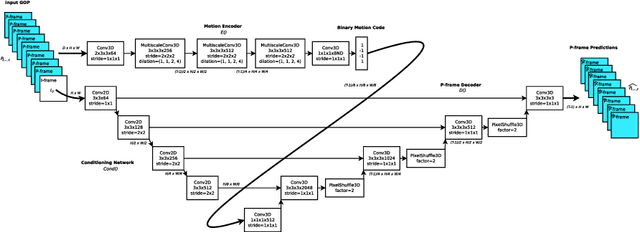

Standard video codecs rely on optical flow to guide inter-frame prediction: pixels from reference frames are moved via motion vectors to predict target video frames. We propose to learn binary motion codes that are encoded based on an input video sequence. These codes are not limited to 2D translations, but can capture complex motion (warping, rotation and occlusion). Our motion codes are learned as part of a single neural network which also learns to compress and decode them. This approach supports parallel video frame decoding instead of the sequential motion estimation and compensation of flow-based methods. We also introduce 3D dynamic bit assignment to adapt to object displacements caused by motion, yielding additional bit savings. By replacing the optical flow-based block-motion algorithms found in an existing video codec with our learned inter-frame prediction model, our approach outperforms the standard H.264 and H.265 video codecs across at low bitrates.
BINet: a binary inpainting network for deep patch-based image compression
Dec 11, 2019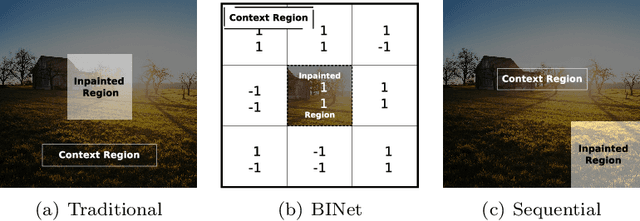

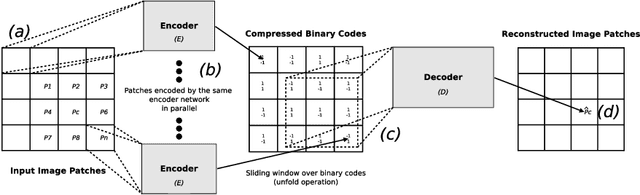

Recent deep learning models outperform standard lossy image compression codecs. However, applying these models on a patch-by-patch basis requires that each image patch be encoded and decoded independently. The influence from adjacent patches is therefore lost, leading to block artefacts at low bitrates. We propose the Binary Inpainting Network (BINet), an autoencoder framework which incorporates binary inpainting to reinstate interdependencies between adjacent patches, for improved patch-based compression of still images. When decoding a patch, BINet additionally uses the binarised encodings from surrounding patches to guide its reconstruction. In contrast to sequential inpainting methods where patches are decoded based on previons reconstructions, BINet operates directly on the binary codes of surrounding patches without access to the original or reconstructed image data. Encoding and decoding can therefore be performed in parallel. We demonstrate that BINet improves the compression quality of a competitive deep image codec across a range of compression levels.
Unsupervised acoustic unit discovery for speech synthesis using discrete latent-variable neural networks
Apr 16, 2019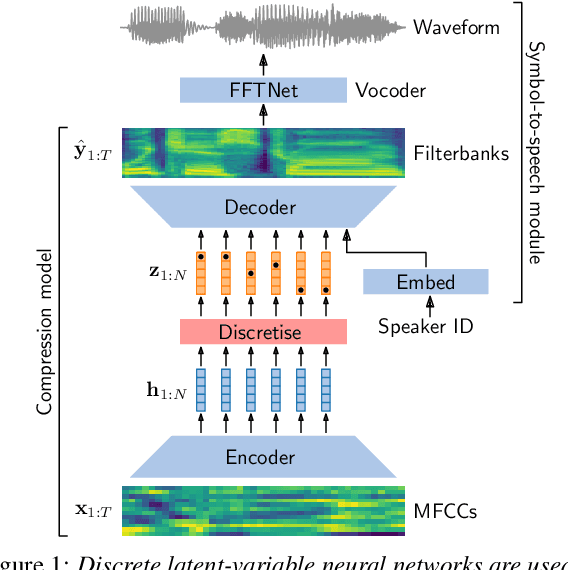

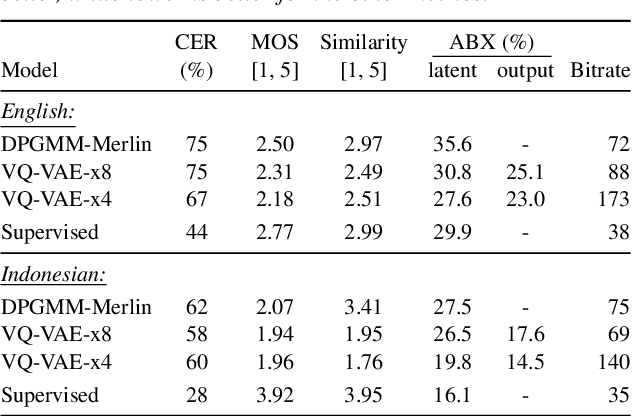
For our submission to the ZeroSpeech 2019 challenge, we apply discrete latent-variable neural networks to unlabelled speech and use the discovered units for speech synthesis. Unsupervised discrete subword modelling could be useful for studies of phonetic category learning in infants or in low-resource speech technology requiring symbolic input. We use an autoencoder (AE) architecture with intermediate discretisation. We decouple acoustic unit discovery from speaker modelling by conditioning the AE's decoder on the training speaker identity. At test time, unit discovery is performed on speech from an unseen speaker, followed by unit decoding conditioned on a known target speaker to obtain reconstructed filterbanks. This output is fed to a neural vocoder to synthesise speech in the target speaker's voice. For discretisation, categorical variational autoencoders (CatVAEs), vector-quantised VAEs (VQ-VAEs) and straight-through estimation are compared at different compression levels on two languages. Our final model uses convolutional encoding, VQ-VAE discretisation, deconvolutional decoding and an FFTNet vocoder. We show that decoupled speaker conditioning intrinsically improves discrete acoustic representations, yielding competitive synthesis quality compared to the challenge baseline.