 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Graphical Model Approach to the Structure-and-Motion Problem
Oct 07, 2021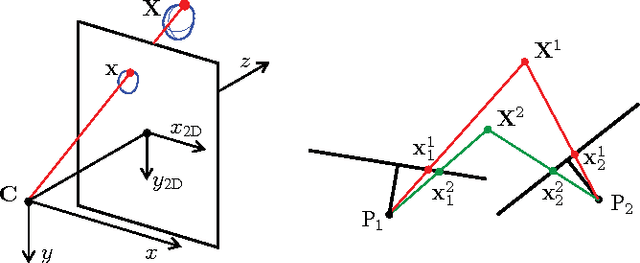
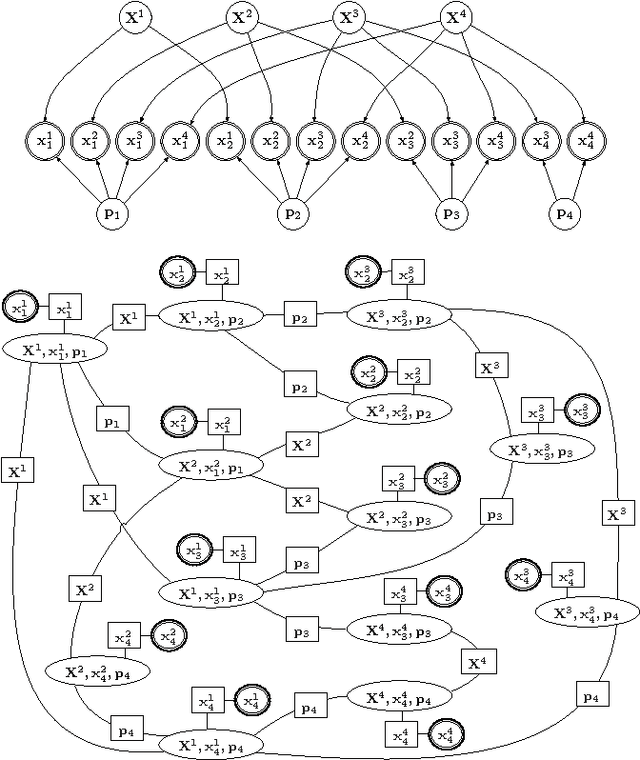
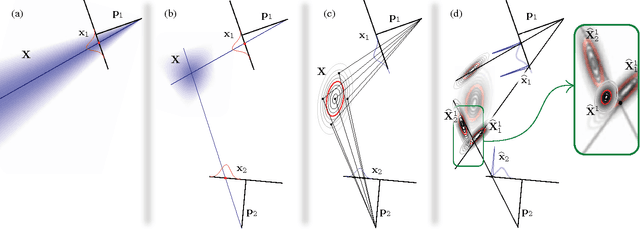
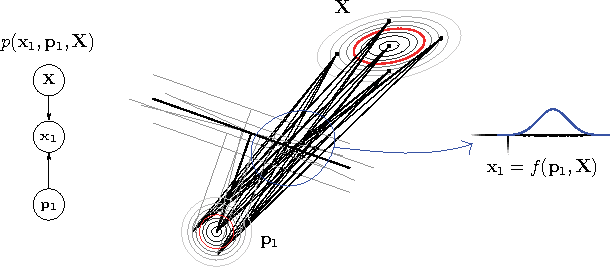
We present a means of formulating and solving the well known structure-and-motion problem in computer vision with probabilistic graphical models. We model the unknown camera poses and 3D feature coordinates as well as the observed 2D projections as Gaussian random variables, using sigma point parameterizations to effectively linearize the nonlinear relationships between these variables. Those variables involved in every projection are grouped into a cluster, and we connect the clusters in a cluster graph. Loopy belief propagation is performed over this graph, in an iterative re-initialization and estimation procedure, and we find that our approach shows promise in both simulation and on real-world data. The PGM is easily extendable to include additional parameters or constraints.
Mava: a research framework for distributed multi-agent reinforcement learning
Jul 03, 2021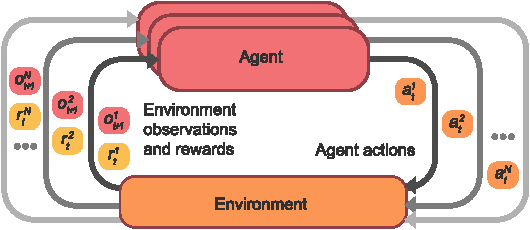
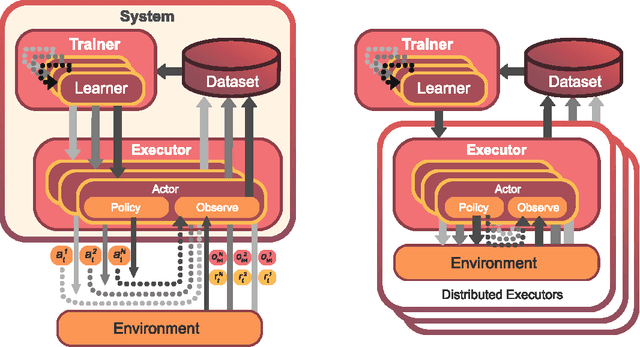
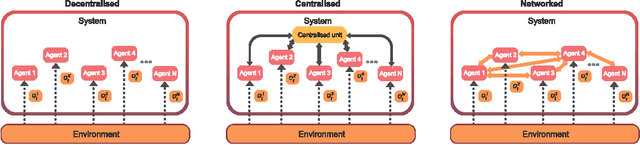

Breakthrough advances in reinforcement learning (RL) research have led to a surge in the development and application of RL. To support the field and its rapid growth, several frameworks have emerged that aim to help the community more easily build effective and scalable agents. However, very few of these frameworks exclusively support multi-agent RL (MARL), an increasingly active field in itself, concerned with decentralised decision-making problems. In this work, we attempt to fill this gap by presenting Mava: a research framework specifically designed for building scalable MARL systems. Mava provides useful components, abstractions, utilities and tools for MARL and allows for simple scaling for multi-process system training and execution, while providing a high level of flexibility and composability. Mava is built on top of DeepMind's Acme \citep{hoffman2020acme}, and therefore integrates with, and greatly benefits from, a wide range of already existing single-agent RL components made available in Acme. Several MARL baseline systems have already been implemented in Mava. These implementations serve as examples showcasing Mava's reusable features, such as interchangeable system architectures, communication and mixing modules. Furthermore, these implementations allow existing MARL algorithms to be easily reproduced and extended. We provide experimental results for these implementations on a wide range of multi-agent environments and highlight the benefits of distributed system training.
Towards the Localisation of Lesions in Diabetic Retinopathy
Feb 02, 2021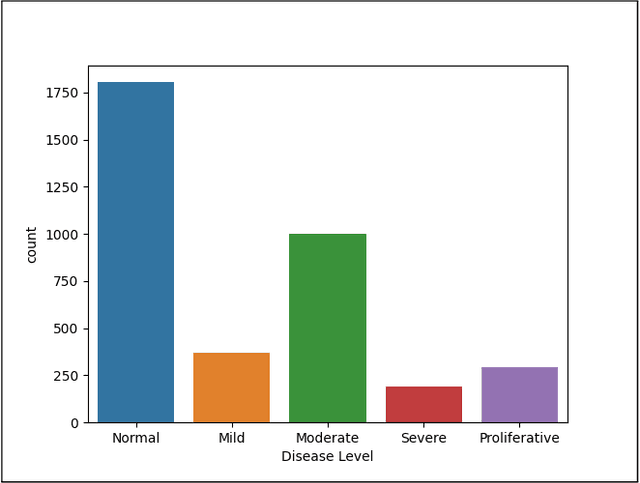
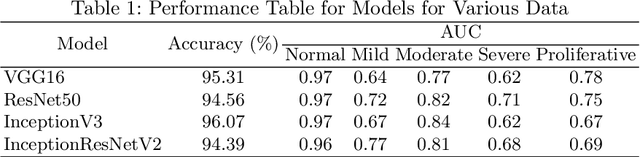
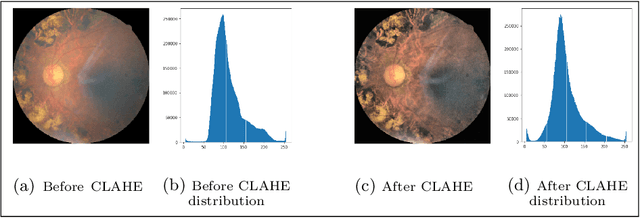
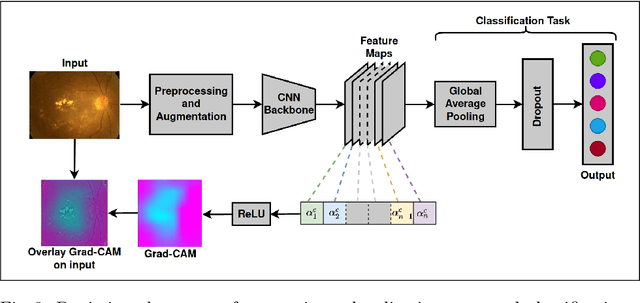
Convolutional Neural Networks (CNNs) have successfully been used to classify diabetic retinopathy (DR) fundus images in recent times. However, deeper representations in CNNs may capture higher-level semantics at the expense of spatial resolution. To make predictions usable for ophthalmologists, we use a post-attention technique called Gradient-weighted Class Activation Mapping (Grad-CAM) on the penultimate layer of deep learning models to produce coarse localisation maps on DR fundus images. This is to help identify discriminative regions in the images, consequently providing evidence for ophthalmologists to make a diagnosis and potentially save lives by early diagnosis. Specifically, this study uses pre-trained weights from four state-of-the-art deep learning models to produce and compare localisation maps of DR fundus images. The models used include VGG16, ResNet50, InceptionV3, and InceptionResNetV2. We find that InceptionV3 achieves the best performance with a test classification accuracy of 96.07%, and localise lesions better and faster than the other models.
BINet: a binary inpainting network for deep patch-based image compression
Dec 11, 2019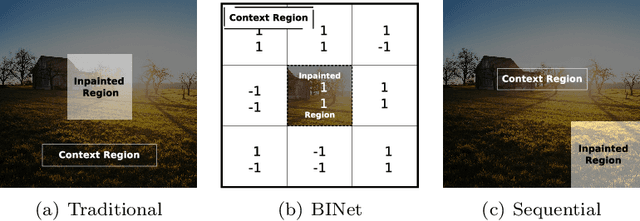

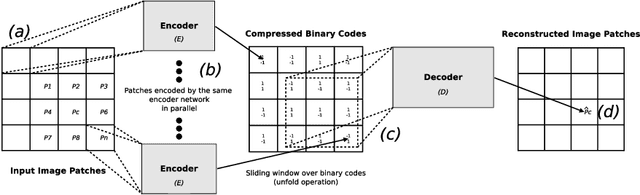

Recent deep learning models outperform standard lossy image compression codecs. However, applying these models on a patch-by-patch basis requires that each image patch be encoded and decoded independently. The influence from adjacent patches is therefore lost, leading to block artefacts at low bitrates. We propose the Binary Inpainting Network (BINet), an autoencoder framework which incorporates binary inpainting to reinstate interdependencies between adjacent patches, for improved patch-based compression of still images. When decoding a patch, BINet additionally uses the binarised encodings from surrounding patches to guide its reconstruction. In contrast to sequential inpainting methods where patches are decoded based on previons reconstructions, BINet operates directly on the binary codes of surrounding patches without access to the original or reconstructed image data. Encoding and decoding can therefore be performed in parallel. We demonstrate that BINet improves the compression quality of a competitive deep image codec across a range of compression levels.