 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinking generative semi-supervised learning and generative open-set recognition
Mar 21, 2023



This study investigates the relationship between semi-supervised learning (SSL) and open-set recognition (OSR) in the context of generative adversarial networks (GANs). Although no previous study has formally linked SSL and OSR, their respective methods share striking similarities. Specifically, SSL-GANs and OSR-GANs require generator to produce samples in the complementary space. Subsequently, by regularising networks with generated samples, both SSL and OSR classifiers generalize the open space. To demonstrate the connection between SSL and OSR, we theoretically and experimentally compare state-of-the-art SSL-GAN methods with state-of-the-art OSR-GAN methods. Our results indicate that the SSL optimised margin-GANs, which have a stronger foundation in literature, set the new standard for the combined SSL-OSR task and achieves new state-of-other art results in certain general OSR experiments. However, the OSR optimised adversarial reciprocal point (ARP)-GANs still slightly out-performed margin-GANs at other OSR experiments. This result indicates unique insights for the combined optimisation task of SSL-OSR.
A Temporal Extension of Latent Dirichlet Allocation for Unsupervised Acoustic Unit Discovery
Jun 29, 2022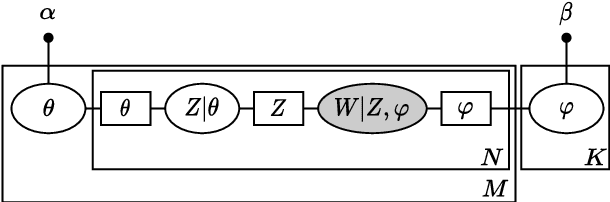
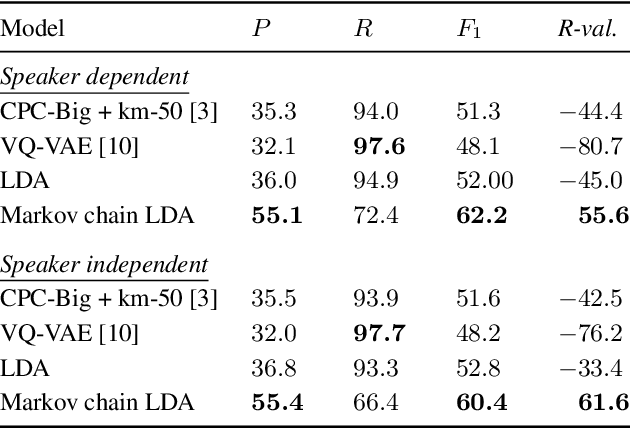
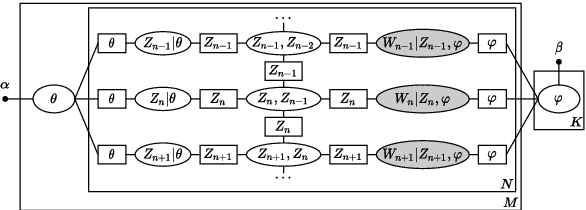
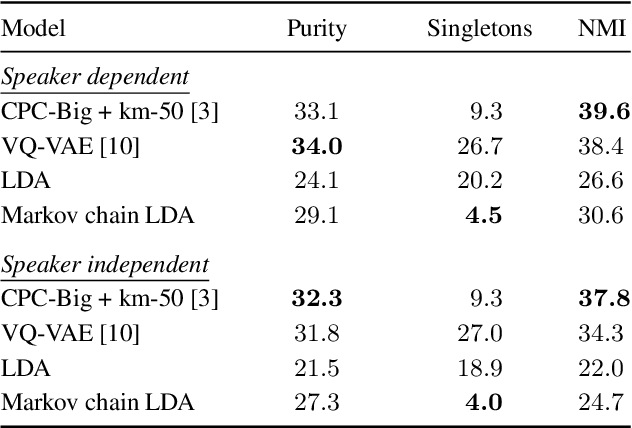
Latent Dirichlet allocation (LDA) is widely used for unsupervised topic modelling on sets of documents. No temporal information is used in the model. However, there is often a relationship between the corresponding topics of consecutive tokens. In this paper, we present an extension to LDA that uses a Markov chain to model temporal information. We use this new model for acoustic unit discovery from speech. As input tokens, the model takes a discretised encoding of speech from a vector quantised (VQ) neural network with 512 codes. The goal is then to map these 512 VQ codes to 50 phone-like units (topics) in order to more closely resemble true phones. In contrast to the base LDA, which only considers how VQ codes co-occur within utterances (documents), the Markov chain LDA additionally captures how consecutive codes follow one another. This extension leads to an increase in cluster quality and phone segmentation results compared to the base LDA. Compared to a recent vector quantised neural network approach that also learns 50 units, the extended LDA model performs better in phone segmentation but worse in mutual information.
Temporal separation of whale vocalizations from background oceanic noise using a power calculation
Oct 19, 2021

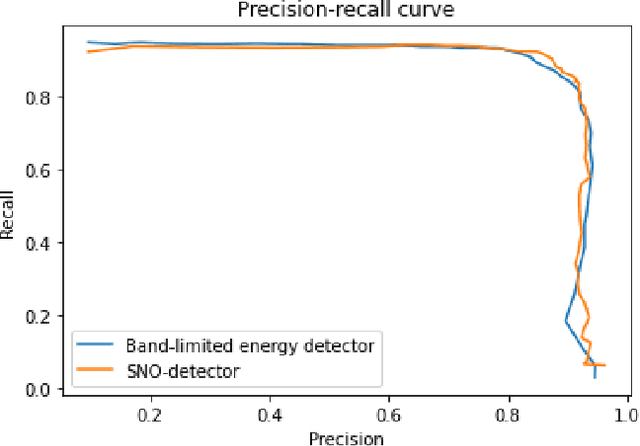
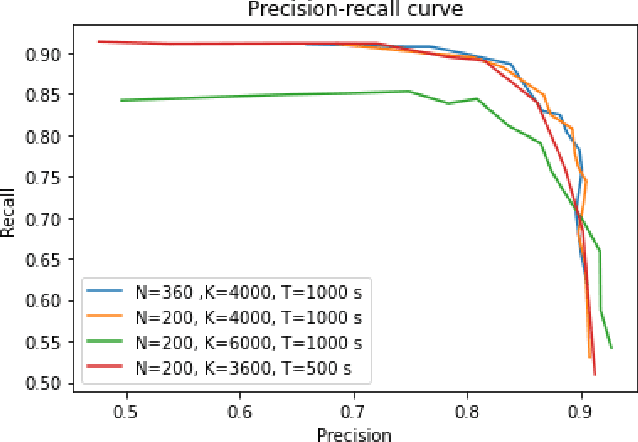
The process of analyzing audio signals in search of cetacean vocalizations is in many cases a very arduous task, requiring many complex computations, a plethora of digital processing techniques and the scrutinization of an audio signal with a fine comb to determine where the vocalizations are located. To ease this process, a computationally efficient and noise-resistant method for determining whether an audio segment contains a potential cetacean call is developed here with the help of a robust power calculation for stationary Gaussian noise signals and a recursive method for determining the mean and variance of a given sample frame. The resulting detector is tested on audio recordings containing Southern Right whale sounds and its performance compared to that of an existing contemporary energy detector. The detector exhibits good performance at moderate-to-high signal-to-noise ratio values. The detector succeeds in being easy to implement, computationally efficient to use and robust enough to accurately detect whale vocalizations in a noisy underwater environment.
A Probabilistic Graphical Model Approach to the Structure-and-Motion Problem
Oct 07, 2021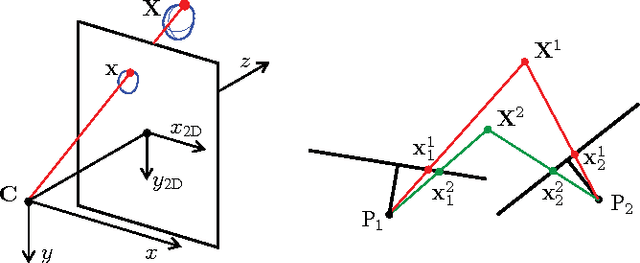
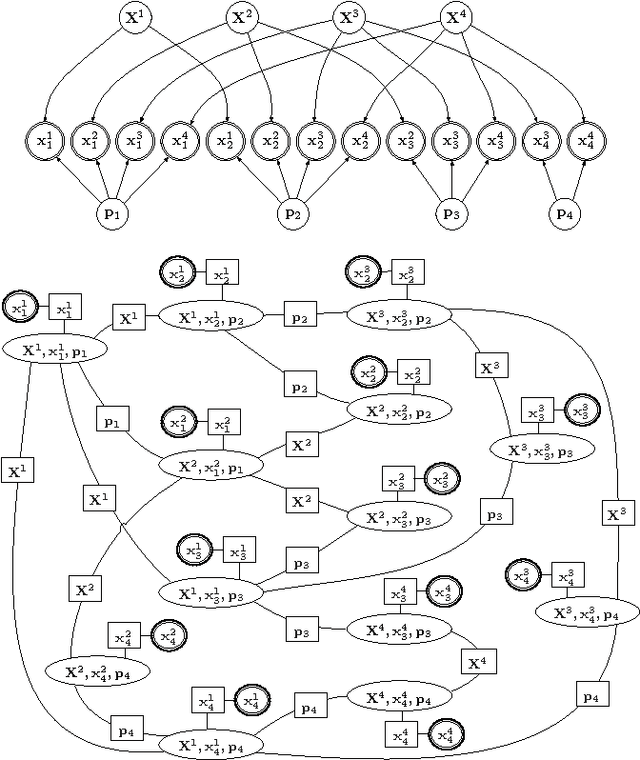
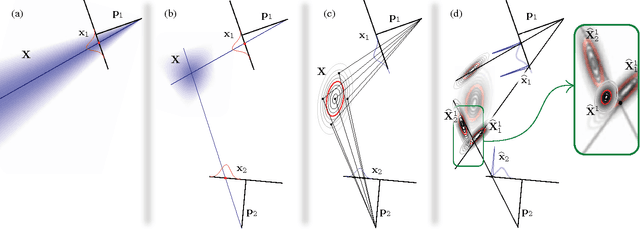
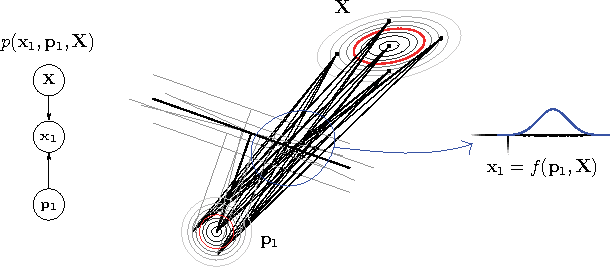
We present a means of formulating and solving the well known structure-and-motion problem in computer vision with probabilistic graphical models. We model the unknown camera poses and 3D feature coordinates as well as the observed 2D projections as Gaussian random variables, using sigma point parameterizations to effectively linearize the nonlinear relationships between these variables. Those variables involved in every projection are grouped into a cluster, and we connect the clusters in a cluster graph. Loopy belief propagation is performed over this graph, in an iterative re-initialization and estimation procedure, and we find that our approach shows promise in both simulation and on real-world data. The PGM is easily extendable to include additional parameters or constraints.
Graph Coloring: Comparing Cluster Graphs to Factor Graphs
Oct 05, 2021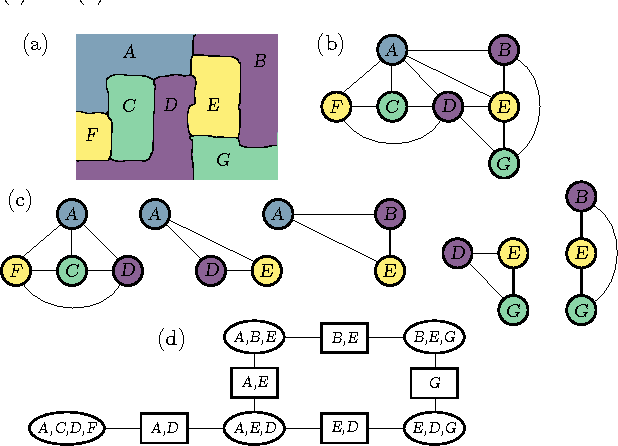
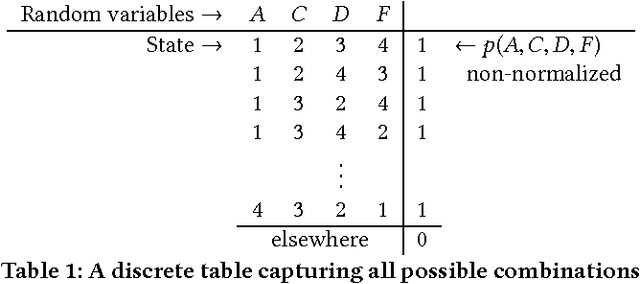

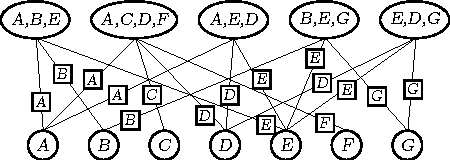
We present a means of formulating and solving graph coloring problems with probabilistic graphical models. In contrast to the prevalent literature that uses factor graphs for this purpose, we instead approach it from a cluster graph perspective. Since there seems to be a lack of algorithms to automatically construct valid cluster graphs, we provide such an algorithm (termed LTRIP). Our experiments indicate a significant advantage for preferring cluster graphs over factor graphs, both in terms of accuracy as well as computational efficiency.
Strengthening Probabilistic Graphical Models: The Purge-and-merge Algorithm
Sep 30, 2021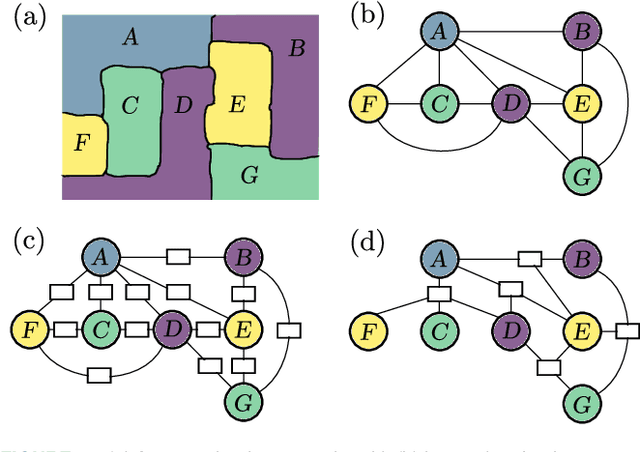
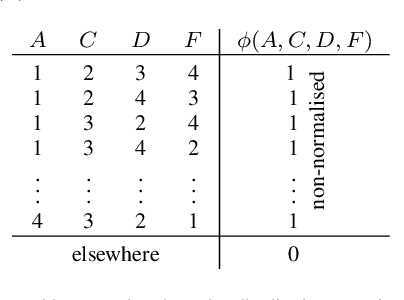
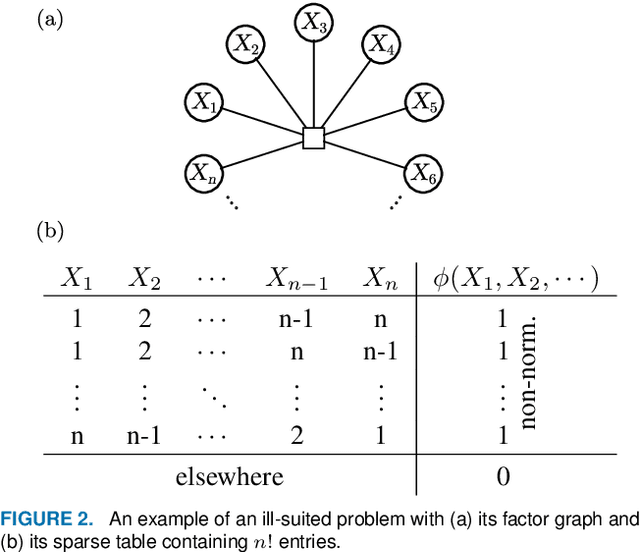
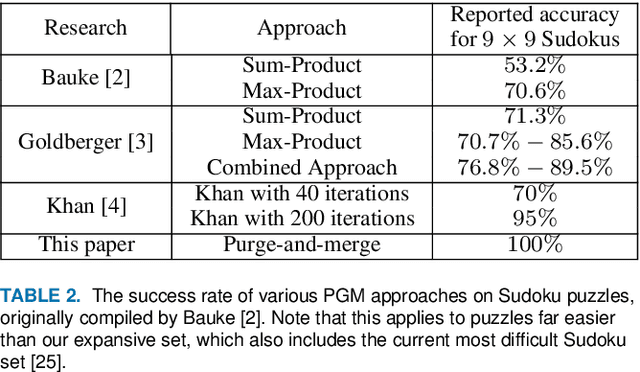
Probabilistic graphical models (PGMs) are powerful tools for solving systems of complex relationships over a variety of probability distributions. Tree-structured PGMs always result in efficient and exact solutions, while inference on graph (or loopy) structured PGMs is not guaranteed to discover the optimal solutions. It is in principle possible to convert loopy PGMs to an equivalent tree structure, but for most interesting problems this is impractical due to exponential blow-up. To address this, we developed the purge-and-merge algorithm. The idea behind this algorithm is to iteratively nudge a malleable graph structure towards a tree structure by selectively merging factors. The merging process is designed to avoid exponential blow-up by making use of sparse structures from which redundancy is purged as the algorithm progresses. This approach is evaluated on a number of constraint-satisfaction puzzles such as Sudoku, Fill-a-pix, and Kakuro. On these tasks, our system outperformed other PGM-based approaches reported in the literature. Although these tasks were limited to the binary logic of CSP, we believe it holds promise for extension to general PGM inference.
Stabilising priors for robust Bayesian deep learning
Oct 23, 2019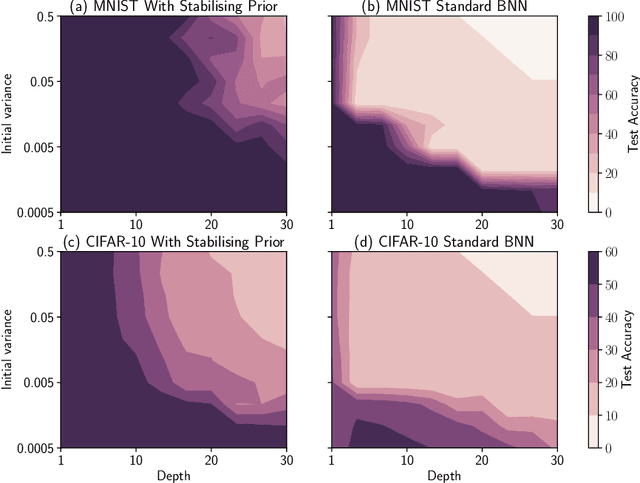
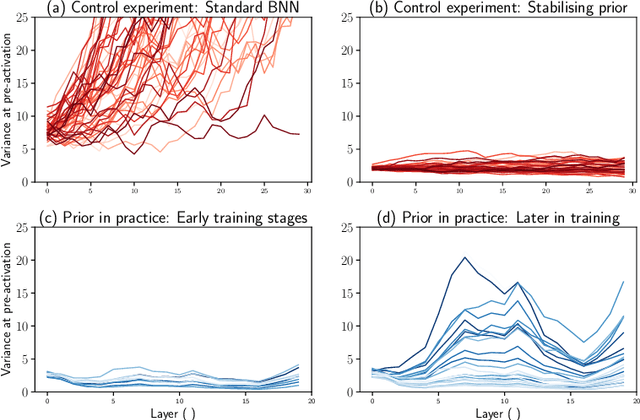
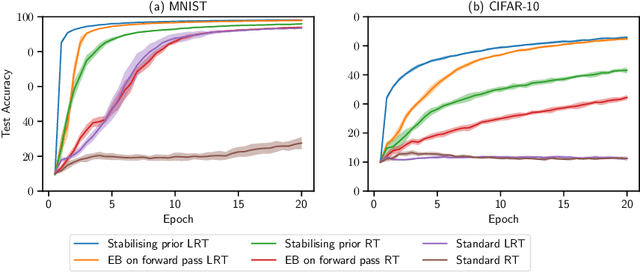
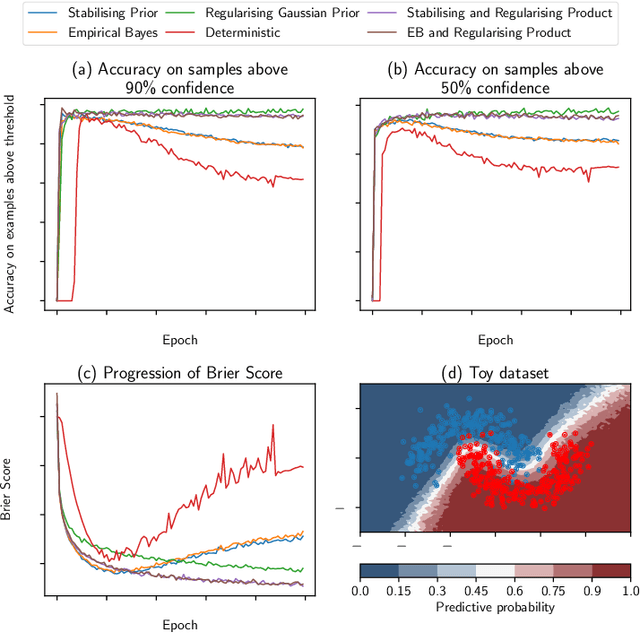
Bayesian neural networks (BNNs) have developed into useful tools for probabilistic modelling due to recent advances in variational inference enabling large scale BNNs. However, BNNs remain brittle and hard to train, especially: (1) when using deep architectures consisting of many hidden layers and (2) in situations with large weight variances. We use signal propagation theory to quantify these challenges and propose self-stabilising priors. This is achieved by a reformulation of the ELBO to allow the prior to influence network signal propagation. Then, we develop a stabilising prior, where the distributional parameters of the prior are adjusted before each forward pass to ensure stability of the propagating signal. This stabilised signal propagation leads to improved convergence and robustness making it possible to train deeper networks and in more noisy settings.
The PAV algorithm optimizes binary proper scoring rules
Apr 08, 2013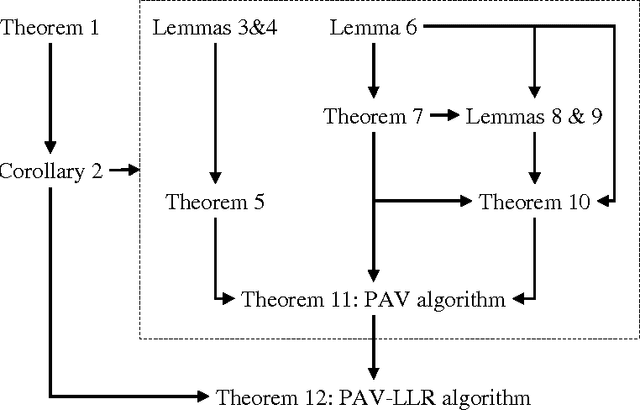
There has been much recent interest in application of the pool-adjacent-violators (PAV) algorithm for the purpose of calibrating the probabilistic outputs of automatic pattern recognition and machine learning algorithms. Special cost functions, known as proper scoring rules form natural objective functions to judge the goodness of such calibration. We show that for binary pattern classifiers, the non-parametric optimization of calibration, subject to a monotonicity constraint, can be solved by PAV and that this solution is optimal for all regular binary proper scoring rules. This extends previous results which were limited to convex binary proper scoring rules. We further show that this result holds not only for calibration of probabilities, but also for calibration of log-likelihood-ratios, in which case optimality holds independently of the prior probabilities of the pattern classes.