 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual training set selection for ASR in under-resourced Malian languages
Aug 13, 2021

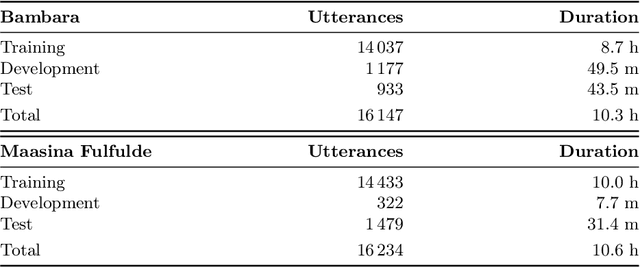
We present first speech recognition systems for the two severely under-resourced Malian languages Bambara and Maasina Fulfulde. These systems will be used by the United Nations as part of a monitoring system to inform and support humanitarian programmes in rural Africa. We have compiled datasets in Bambara and Maasina Fulfulde, but since these are very small, we take advantage of six similarly under-resourced datasets in other languages for multilingual training. We focus specifically on the best composition of the multilingual pool of speech data for multilingual training. We find that, although maximising the training pool by including all six additional languages provides improved speech recognition in both target languages, substantially better performance can be achieved by a more judicious choice. Our experiments show that the addition of just one language provides best performance. For Bambara, this additional language is Maasina Fulfulde, and its introduction leads to a relative word error rate reduction of 6.7%, as opposed to a 2.4% relative reduction achieved when pooling all six additional languages. For the case of Maasina Fulfulde, best performance was achieved when adding only Luganda, leading to a relative word error rate improvement of 9.4% as opposed to a 3.9% relative improvement when pooling all six languages. We conclude that careful selection of the out-of-language data is worthwhile for multilingual training even in highly under-resourced settings, and that the general assumption that more data is better does not always hold.
Multilingual Bottleneck Features for Improving ASR Performance of Code-Switched Speech in Under-Resourced Languages
Oct 31, 2020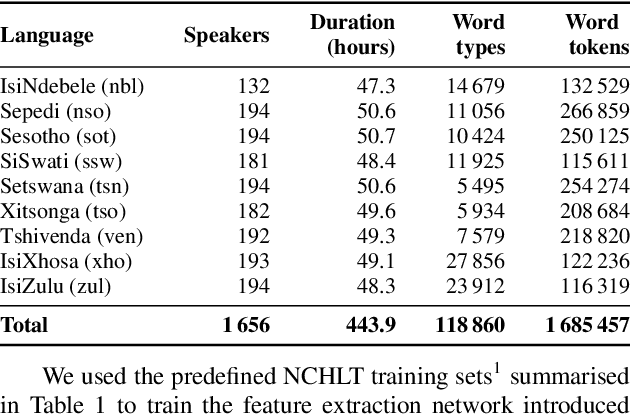
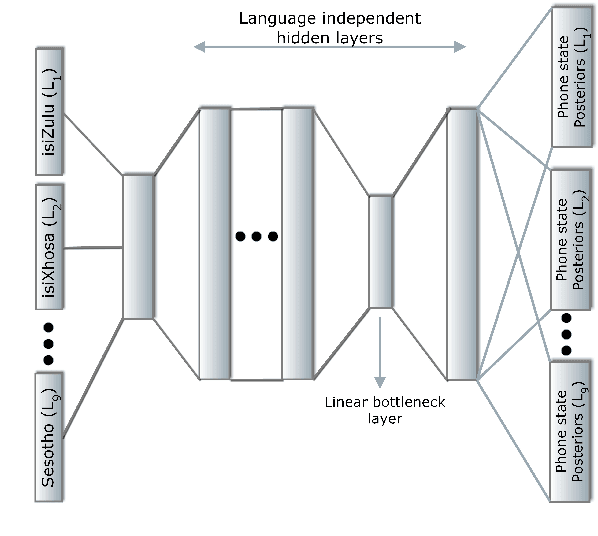
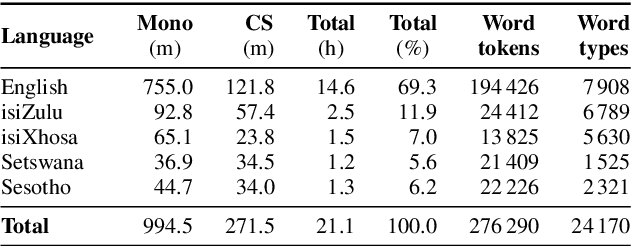
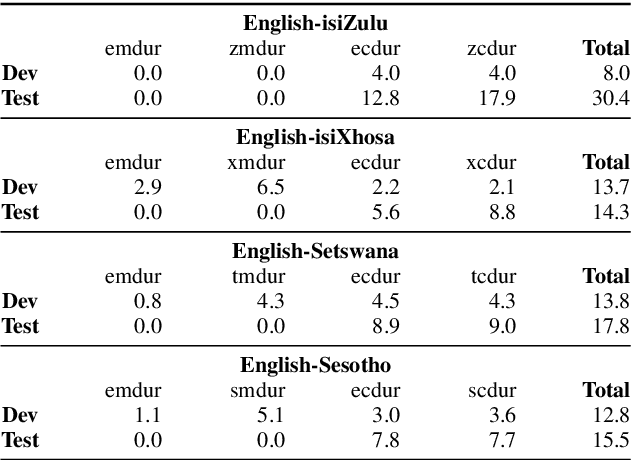
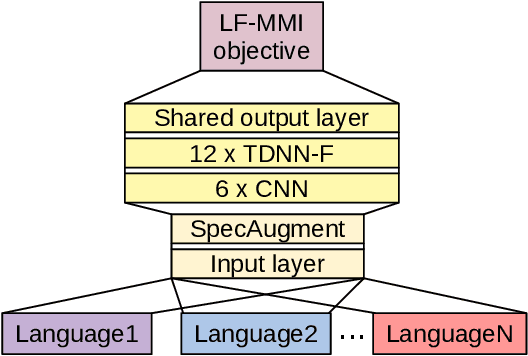
In this work, we explore the benefits of using multilingual bottleneck features (mBNF) in acoustic modelling for the automatic speech recognition of code-switched (CS) speech in African languages. The unavailability of annotated corpora in the languages of interest has always been a primary challenge when developing speech recognition systems for this severely under-resourced type of speech. Hence, it is worthwhile to investigate the potential of using speech corpora available for other better-resourced languages to improve speech recognition performance. To achieve this, we train a mBNF extractor using nine Southern Bantu languages that form part of the freely available multilingual NCHLT corpus. We append these mBNFs to the existing MFCCs, pitch features and i-vectors to train acoustic models for automatic speech recognition (ASR) in the target code-switched languages. Our results show that the inclusion of the mBNF features leads to clear performance improvements over a baseline trained without the mBNFs for code-switched English-isiZulu, English-isiXhosa, English-Sesotho and English-Setswana speech.
* In Proceedings of The First Workshop on Speech Technologies for Code-Switching in Multilingual Communities