 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature learning for efficient ASR-free keyword spotting in low-resource languages
Paper and Code
Aug 13, 2021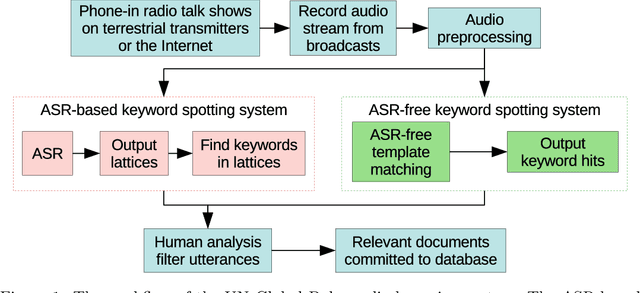
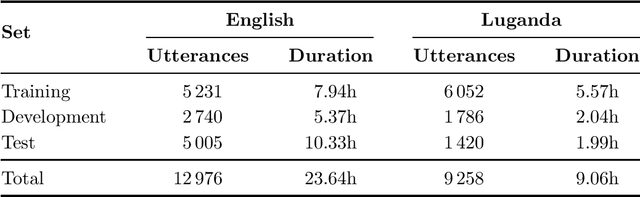

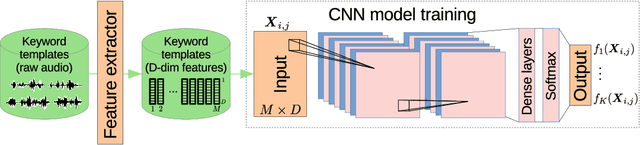
We consider feature learning for efficient keyword spotting that can be applied in severely under-resourced settings. The objective is to support humanitarian relief programmes by the United Nations in parts of Africa in which almost no language resources are available. For rapid development in such languages, we rely on a small, easily-compiled set of isolated keywords. These keyword templates are applied to a large corpus of in-domain but untranscribed speech using dynamic time warping (DTW). The resulting DTW alignment scores are used to train a convolutional neural network (CNN) which is orders of magnitude more computationally efficient and suitable for real-time application. We optimise this neural network keyword spotter by identifying robust acoustic features in this almost zero-resource setting. First, we incorporate information from well-resourced but unrelated languages using a multilingual bottleneck feature (BNF) extractor. Next, we consider features extracted from an autoencoder (AE) trained on in-domain but untranscribed data. Finally, we consider correspondence autoencoder (CAE) features which are fine-tuned on the small set of in-domain labelled data. Experiments in South African English and Luganda, a low-resource language, show that BNF and CAE features achieve a 5% relative performance improvement over baseline MFCCs. However, using BNFs as input to the CAE results in a more than 27% relative improvement over MFCCs in ROC area-under-the-curve (AUC) and more than twice as many top-10 retrievals. We show that, using these features, the CNN-DTW keyword spotter performs almost as well as the DTW keyword spotter while outperforming a baseline CNN trained only on the keyword templates. The CNN-DTW keyword spotter using BNF-derived CAE features represents an efficient approach with competitive performance suited to rapid deployment in a severely under-resourced scenario.