 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Mitigation of Adversarial Text Perturbation
Feb 19, 2022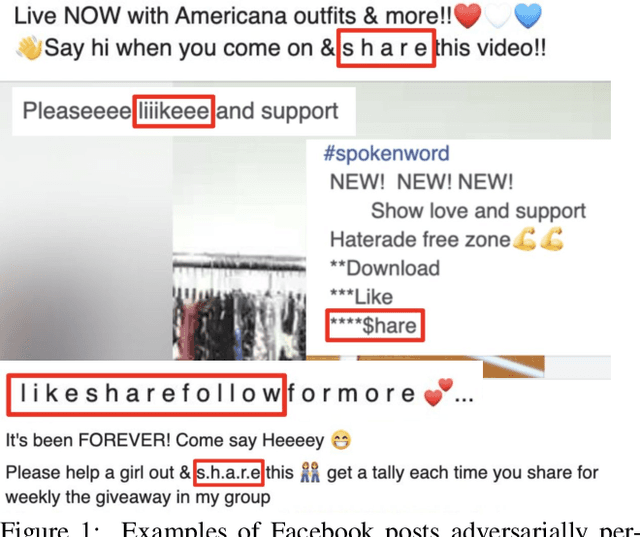
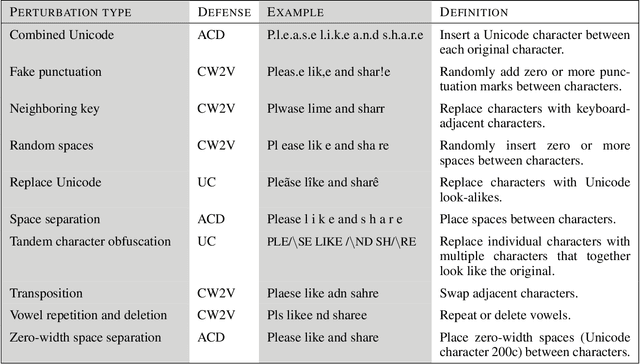
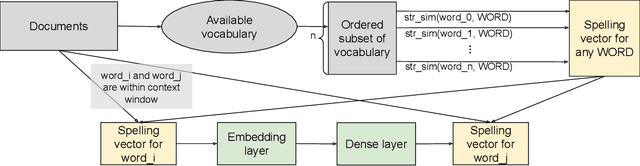

Social networks have become an indispensable part of our lives, with billions of people producing ever-increasing amounts of text. At such scales, content policies and their enforcement become paramount. To automate moderation, questionable content is detected by Natural Language Processing (NLP) classifiers. However, high-performance classifiers are hampered by misspellings and adversarial text perturbations. In this paper, we classify intentional and unintentional adversarial text perturbation into ten types and propose a deobfuscation pipeline to make NLP models robust to such perturbations. We propose Continuous Word2Vec (CW2V), our data-driven method to learn word embeddings that ensures that perturbations of words have embeddings similar to those of the original words. We show that CW2V embeddings are generally more robust to text perturbations than embeddings based on character ngrams. Our robust classification pipeline combines deobfuscation and classification, using proposed defense methods and word embeddings to classify whether Facebook posts are requesting engagement such as likes. Our pipeline results in engagement bait classification that goes from 0.70 to 0.67 AUC with adversarial text perturbation, while character ngram-based word embedding methods result in downstream classification that goes from 0.76 to 0.64.
Locally Differentially Private Naive Bayes Classification
May 03, 2019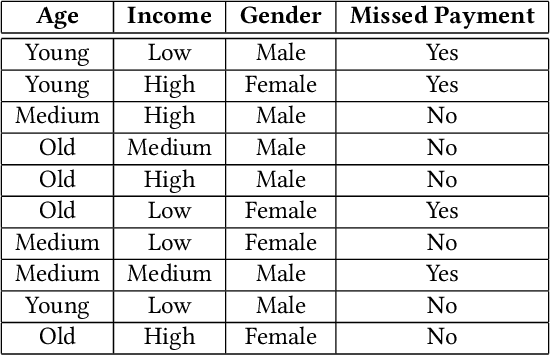
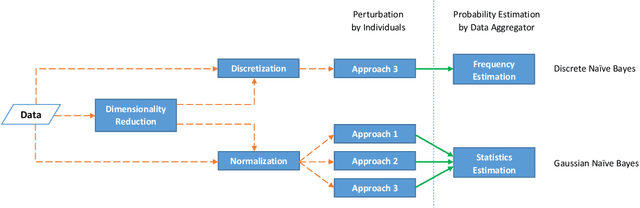
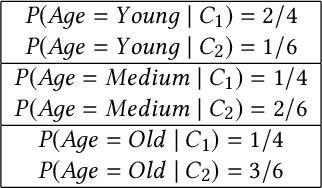
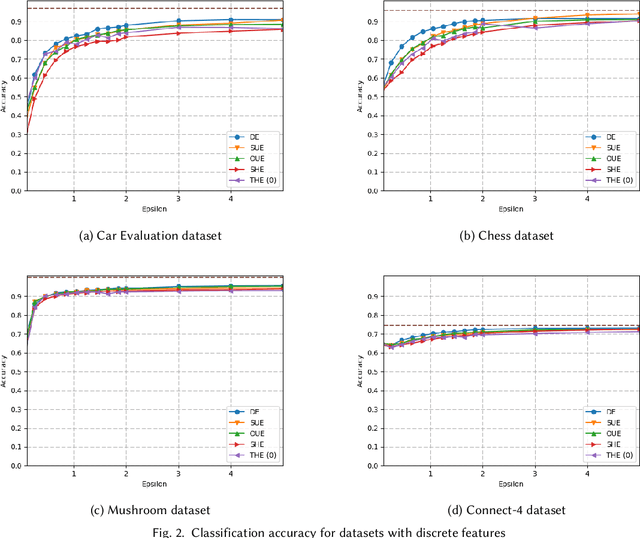
In machine learning, classification models need to be trained in order to predict class labels. When the training data contains personal information about individuals, collecting training data becomes difficult due to privacy concerns. Local differential privacy is a definition to measure the individual privacy when there is no trusted data curator. Individuals interact with an untrusted data aggregator who obtains statistical information about the population without learning personal data. In order to train a Naive Bayes classifier in an untrusted setting, we propose to use methods satisfying local differential privacy. Individuals send their perturbed inputs that keep the relationship between the feature values and class labels. The data aggregator estimates all probabilities needed by the Naive Bayes classifier. Then, new instances can be classified based on the estimated probabilities. We propose solutions for both discrete and continuous data. In order to eliminate high amount of noise and decrease communication cost in multi-dimensional data, we propose utilizing dimensionality reduction techniques which can be applied by individuals before perturbing their inputs. Our experimental results show that the accuracy of the Naive Bayes classifier is maintained even when the individual privacy is guaranteed under local differential privacy, and that using dimensionality reduction enhances the accuracy.
Privacy Preserving Machine Learning: Threats and Solutions
Mar 27, 2018
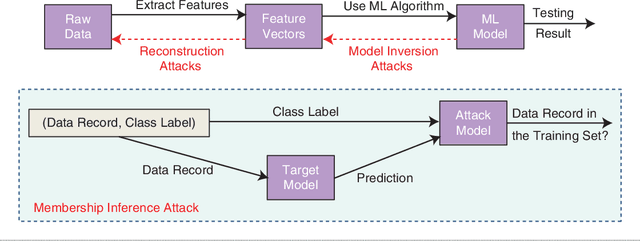
For privacy concerns to be addressed adequately in current machine learning systems, the knowledge gap between the machine learning and privacy communities must be bridged. This article aims to provide an introduction to the intersection of both fields with special emphasis on the techniques used to protect the data.