 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Mitigation of Adversarial Text Perturbation
Feb 19, 2022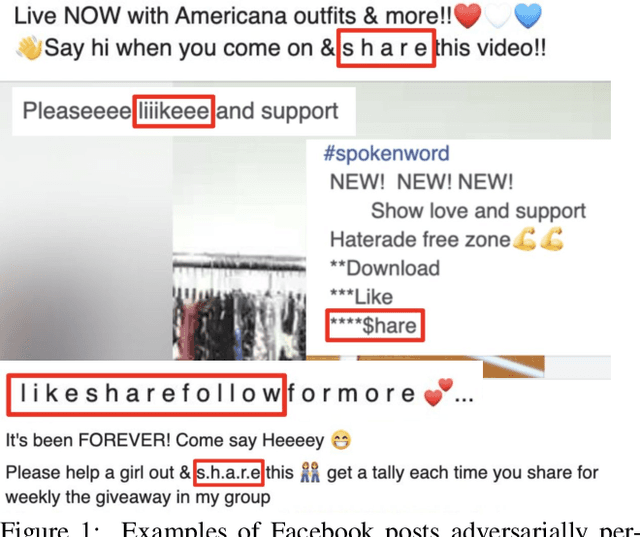
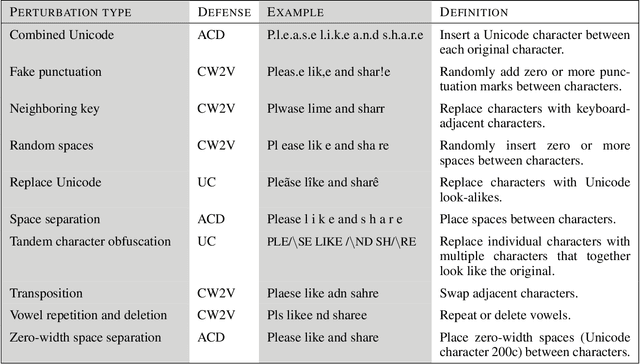
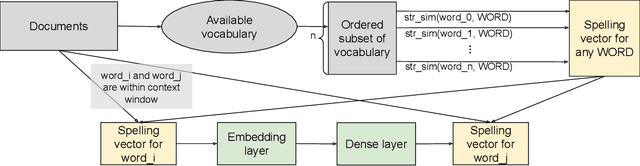

Social networks have become an indispensable part of our lives, with billions of people producing ever-increasing amounts of text. At such scales, content policies and their enforcement become paramount. To automate moderation, questionable content is detected by Natural Language Processing (NLP) classifiers. However, high-performance classifiers are hampered by misspellings and adversarial text perturbations. In this paper, we classify intentional and unintentional adversarial text perturbation into ten types and propose a deobfuscation pipeline to make NLP models robust to such perturbations. We propose Continuous Word2Vec (CW2V), our data-driven method to learn word embeddings that ensures that perturbations of words have embeddings similar to those of the original words. We show that CW2V embeddings are generally more robust to text perturbations than embeddings based on character ngrams. Our robust classification pipeline combines deobfuscation and classification, using proposed defense methods and word embeddings to classify whether Facebook posts are requesting engagement such as likes. Our pipeline results in engagement bait classification that goes from 0.70 to 0.67 AUC with adversarial text perturbation, while character ngram-based word embedding methods result in downstream classification that goes from 0.76 to 0.64.