 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRusTitW: Russian Language Text Dataset for Visual Text in-the-Wild Recognition
Mar 29, 2023



Information surrounds people in modern life. Text is a very efficient type of information that people use for communication for centuries. However, automated text-in-the-wild recognition remains a challenging problem. The major limitation for a DL system is the lack of training data. For the competitive performance, training set must contain many samples that replicate the real-world cases. While there are many high-quality datasets for English text recognition; there are no available datasets for Russian language. In this paper, we present a large-scale human-labeled dataset for Russian text recognition in-the-wild. We also publish a synthetic dataset and code to reproduce the generation process
Federated Calibration and Evaluation of Binary Classifiers
Oct 22, 2022


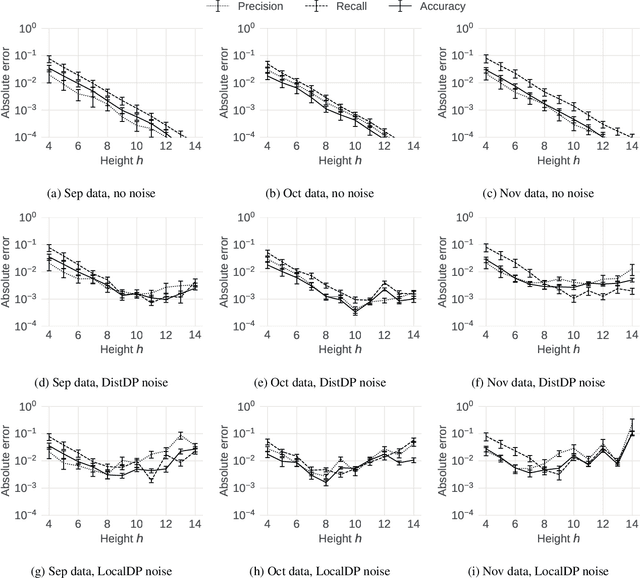
We address two major obstacles to practical use of supervised classifiers on distributed private data. Whether a classifier was trained by a federation of cooperating clients or trained centrally out of distribution, (1) the output scores must be calibrated, and (2) performance metrics must be evaluated -- all without assembling labels in one place. In particular, we show how to perform calibration and compute precision, recall, accuracy and ROC-AUC in the federated setting under three privacy models (i) secure aggregation, (ii) distributed differential privacy, (iii) local differential privacy. Our theorems and experiments clarify tradeoffs between privacy, accuracy, and data efficiency. They also help decide whether a given application has sufficient data to support federated calibration and evaluation.
Data-Driven Mitigation of Adversarial Text Perturbation
Feb 19, 2022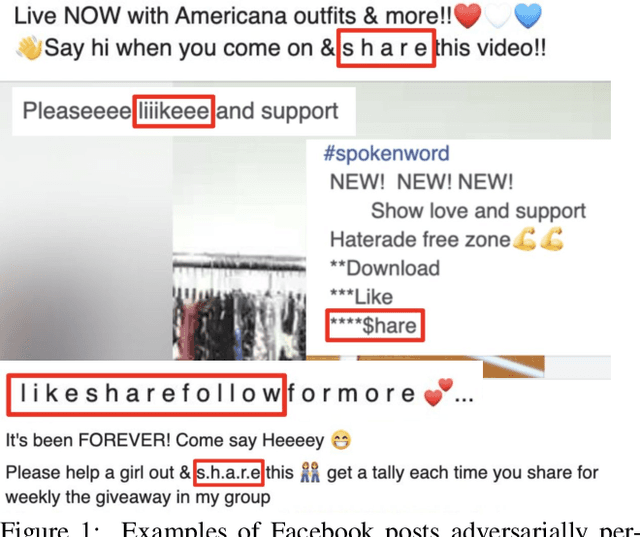
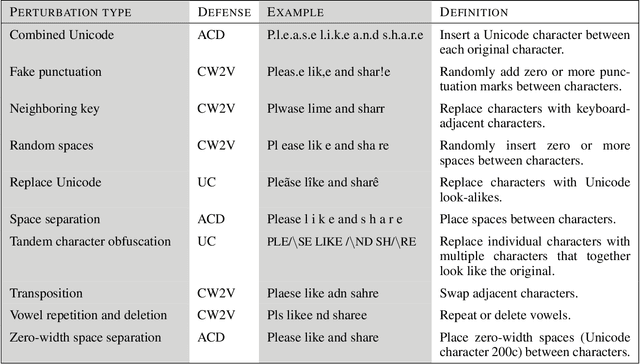
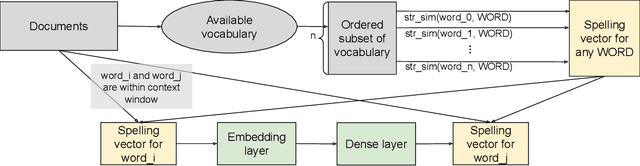

Social networks have become an indispensable part of our lives, with billions of people producing ever-increasing amounts of text. At such scales, content policies and their enforcement become paramount. To automate moderation, questionable content is detected by Natural Language Processing (NLP) classifiers. However, high-performance classifiers are hampered by misspellings and adversarial text perturbations. In this paper, we classify intentional and unintentional adversarial text perturbation into ten types and propose a deobfuscation pipeline to make NLP models robust to such perturbations. We propose Continuous Word2Vec (CW2V), our data-driven method to learn word embeddings that ensures that perturbations of words have embeddings similar to those of the original words. We show that CW2V embeddings are generally more robust to text perturbations than embeddings based on character ngrams. Our robust classification pipeline combines deobfuscation and classification, using proposed defense methods and word embeddings to classify whether Facebook posts are requesting engagement such as likes. Our pipeline results in engagement bait classification that goes from 0.70 to 0.67 AUC with adversarial text perturbation, while character ngram-based word embedding methods result in downstream classification that goes from 0.76 to 0.64.
Picasso: Model-free Feature Visualization
Nov 24, 2021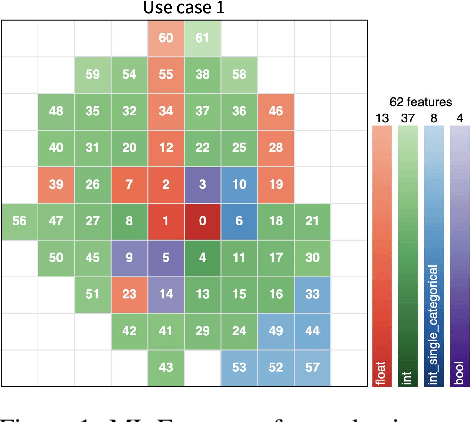
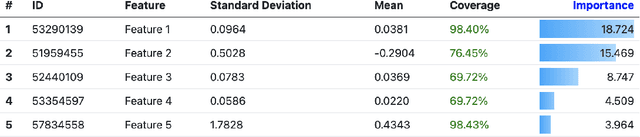
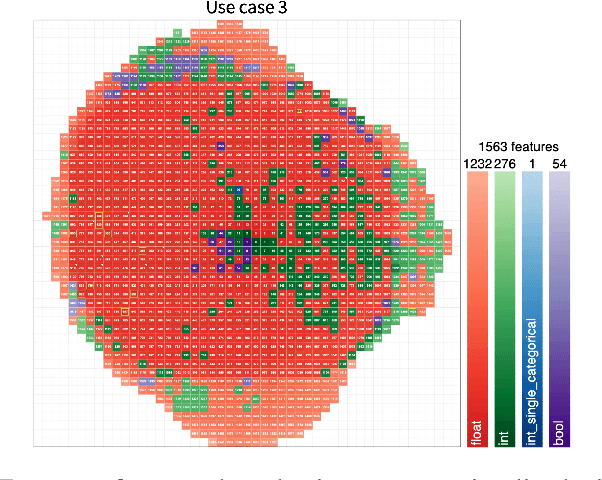
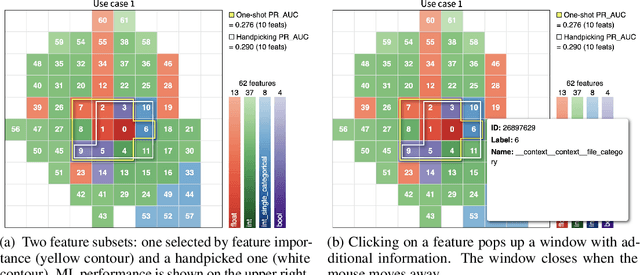
Today, Machine Learning (ML) applications can have access to tens of thousands of features. With such feature sets, efficiently browsing and curating subsets of most relevant features is a challenge. In this paper, we present a novel approach to visualize up to several thousands of features in a single image. The image not only shows information on individual features, but also expresses feature interactions via the relative positioning of features.