 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLegal-Bench: Cognitively Grounded Benchmark for Vietnamese Legal Reasoning of Large Language Models
Dec 24, 2025The rapid advancement of large language models (LLMs) has enabled new possibilities for applying artificial intelligence within the legal domain. Nonetheless, the complexity, hierarchical organization, and frequent revisions of Vietnamese legislation pose considerable challenges for evaluating how well these models interpret and utilize legal knowledge. To address this gap, the Vietnamese Legal Benchmark (VLegal-Bench) is introduced, the first comprehensive benchmark designed to systematically assess LLMs on Vietnamese legal tasks. Informed by Bloom's cognitive taxonomy, VLegal-Bench encompasses multiple levels of legal understanding through tasks designed to reflect practical usage scenarios. The benchmark comprises 10,450 samples generated through a rigorous annotation pipeline, where legal experts label and cross-validate each instance using our annotation system to ensure every sample is grounded in authoritative legal documents and mirrors real-world legal assistant workflows, including general legal questions and answers, retrieval-augmented generation, multi-step reasoning, and scenario-based problem solving tailored to Vietnamese law. By providing a standardized, transparent, and cognitively informed evaluation framework, VLegal-Bench establishes a solid foundation for assessing LLM performance in Vietnamese legal contexts and supports the development of more reliable, interpretable, and ethically aligned AI-assisted legal systems. To facilitate access and reproducibility, we provide a public landing page for this benchmark at https://vilegalbench.cmcai.vn/.
Intelligent Knowledge Mining Framework: Bridging AI Analysis and Trustworthy Preservation
Dec 19, 2025The unprecedented proliferation of digital data presents significant challenges in access, integration, and value creation across all data-intensive sectors. Valuable information is frequently encapsulated within disparate systems, unstructured documents, and heterogeneous formats, creating silos that impede efficient utilization and collaborative decision-making. This paper introduces the Intelligent Knowledge Mining Framework (IKMF), a comprehensive conceptual model designed to bridge the critical gap between dynamic AI-driven analysis and trustworthy long-term preservation. The framework proposes a dual-stream architecture: a horizontal Mining Process that systematically transforms raw data into semantically rich, machine-actionable knowledge, and a parallel Trustworthy Archiving Stream that ensures the integrity, provenance, and computational reproducibility of these assets. By defining a blueprint for this symbiotic relationship, the paper provides a foundational model for transforming static repositories into living ecosystems that facilitate the flow of actionable intelligence from producers to consumers. This paper outlines the motivation, problem statement, and key research questions guiding the research and development of the framework, presents the underlying scientific methodology, and details its conceptual design and modeling.
Picasso: Model-free Feature Visualization
Nov 24, 2021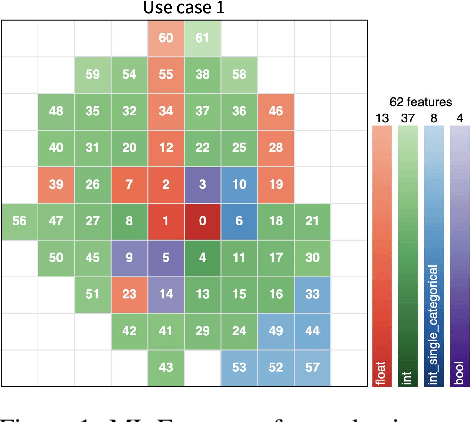
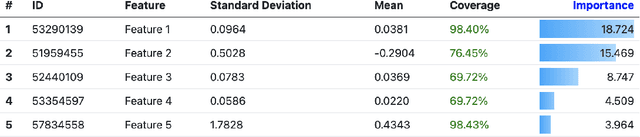
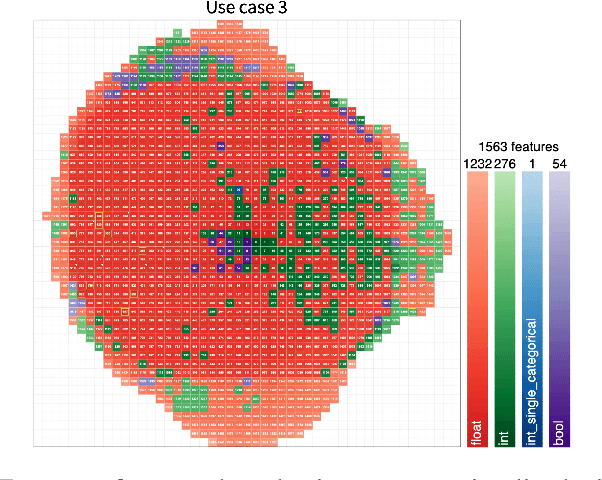
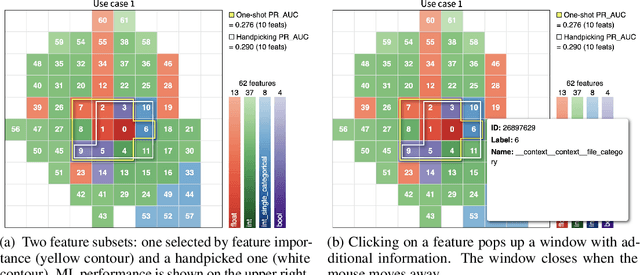
Today, Machine Learning (ML) applications can have access to tens of thousands of features. With such feature sets, efficiently browsing and curating subsets of most relevant features is a challenge. In this paper, we present a novel approach to visualize up to several thousands of features in a single image. The image not only shows information on individual features, but also expresses feature interactions via the relative positioning of features.