 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Calibration and Evaluation of Binary Classifiers
Paper and Code
Oct 22, 2022


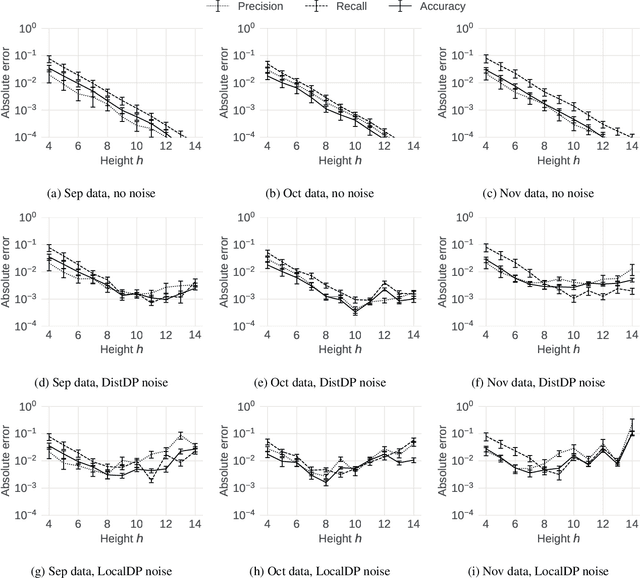
We address two major obstacles to practical use of supervised classifiers on distributed private data. Whether a classifier was trained by a federation of cooperating clients or trained centrally out of distribution, (1) the output scores must be calibrated, and (2) performance metrics must be evaluated -- all without assembling labels in one place. In particular, we show how to perform calibration and compute precision, recall, accuracy and ROC-AUC in the federated setting under three privacy models (i) secure aggregation, (ii) distributed differential privacy, (iii) local differential privacy. Our theorems and experiments clarify tradeoffs between privacy, accuracy, and data efficiency. They also help decide whether a given application has sufficient data to support federated calibration and evaluation.