 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRusTitW: Russian Language Text Dataset for Visual Text in-the-Wild Recognition
Mar 29, 2023



Information surrounds people in modern life. Text is a very efficient type of information that people use for communication for centuries. However, automated text-in-the-wild recognition remains a challenging problem. The major limitation for a DL system is the lack of training data. For the competitive performance, training set must contain many samples that replicate the real-world cases. While there are many high-quality datasets for English text recognition; there are no available datasets for Russian language. In this paper, we present a large-scale human-labeled dataset for Russian text recognition in-the-wild. We also publish a synthetic dataset and code to reproduce the generation process
Object-Based Augmentation Improves Quality of Remote SensingSemantic Segmentation
May 12, 2021
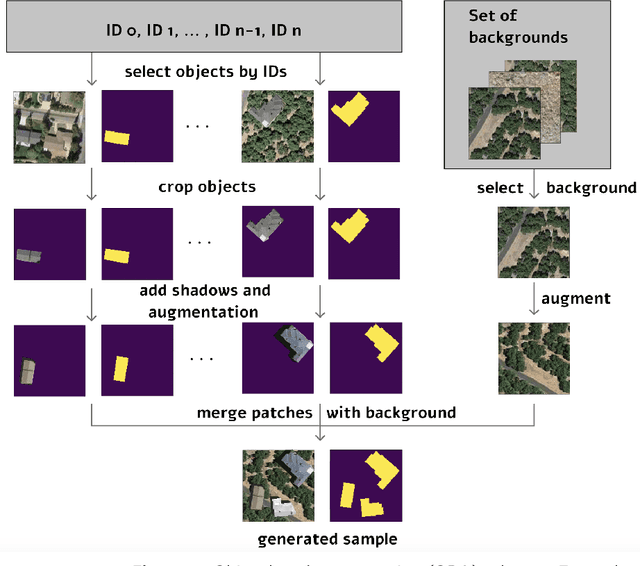


Today deep convolutional neural networks (CNNs) push the limits for most computer vision problems, define trends, and set state-of-the-art results. In remote sensing tasks such as object detection and semantic segmentation, CNNs reach the SotA performance. However, for precise performance, CNNs require much high-quality training data. Rare objects and the variability of environmental conditions strongly affect prediction stability and accuracy. To overcome these data restrictions, it is common to consider various approaches including data augmentation techniques. This study focuses on the development and testing of object-based augmentation. The practical usefulness of the developed augmentation technique is shown in the remote sensing domain, being one of the most demanded ineffective augmentation techniques. We propose a novel pipeline for georeferenced image augmentation that enables a significant increase in the number of training samples. The presented pipeline is called object-based augmentation (OBA) and exploits objects' segmentation masks to produce new realistic training scenes using target objects and various label-free backgrounds. We test the approach on the buildings segmentation dataset with six different CNN architectures and show that the proposed method benefits for all the tested models. We also show that further augmentation strategy optimization can improve the results. The proposed method leads to the meaningful improvement of U-Net model predictions from 0.78 to 0.83 F1-score.
Image Augmentation for Multitask Few-Shot Learning: Agricultural Domain Use-Case
Feb 24, 2021
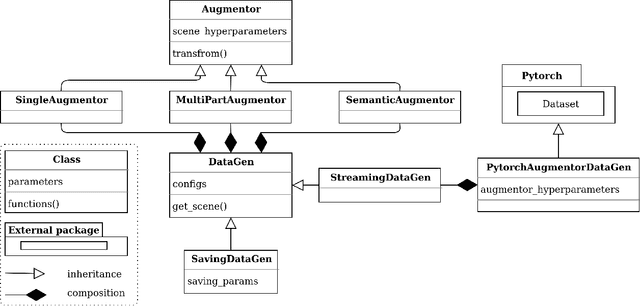

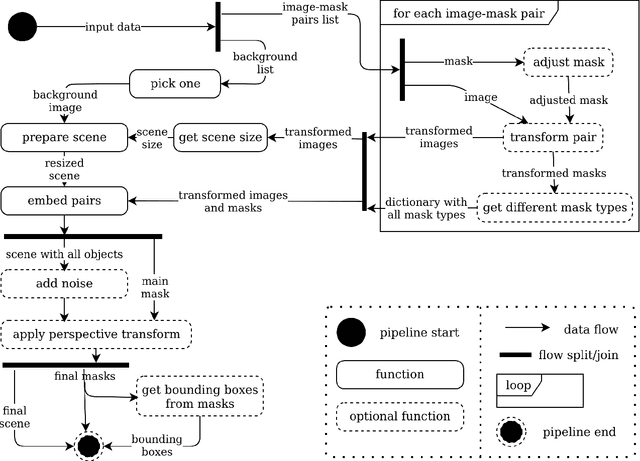
Large datasets' availability is catalyzing a rapid expansion of deep learning in general and computer vision in particular. At the same time, in many domains, a sufficient amount of training data is lacking, which may become an obstacle to the practical application of computer vision techniques. This paper challenges small and imbalanced datasets based on the example of a plant phenomics domain. We introduce an image augmentation framework, which enables us to extremely enlarge the number of training samples while providing the data for such tasks as object detection, semantic segmentation, instance segmentation, object counting, image denoising, and classification. We prove that our augmentation method increases model performance when only a few training samples are available. In our experiment, we use the DeepLabV3 model on semantic segmentation tasks with Arabidopsis and Nicotiana tabacum image dataset. The obtained result shows a 9% relative increase in model performance compared to the basic image augmentation techniques.