 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Augmentation for Multitask Few-Shot Learning: Agricultural Domain Use-Case
Paper and Code
Feb 24, 2021
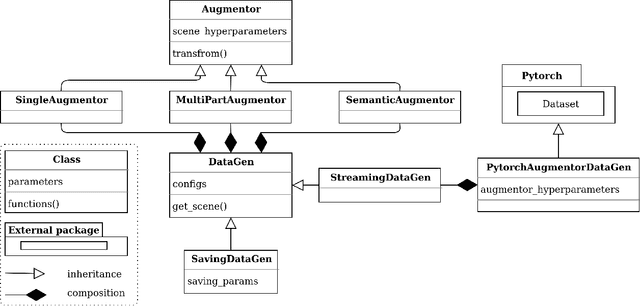

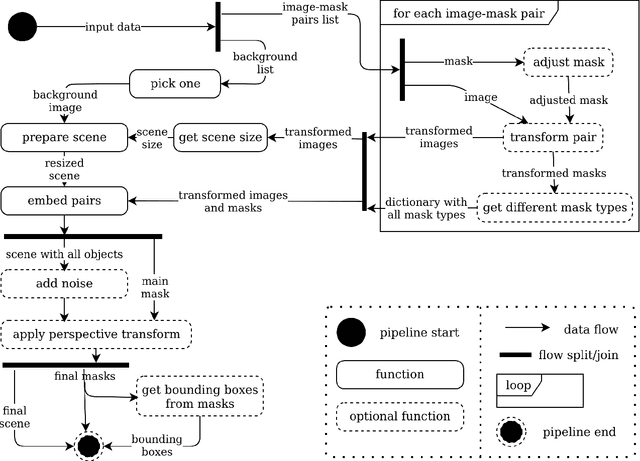
Large datasets' availability is catalyzing a rapid expansion of deep learning in general and computer vision in particular. At the same time, in many domains, a sufficient amount of training data is lacking, which may become an obstacle to the practical application of computer vision techniques. This paper challenges small and imbalanced datasets based on the example of a plant phenomics domain. We introduce an image augmentation framework, which enables us to extremely enlarge the number of training samples while providing the data for such tasks as object detection, semantic segmentation, instance segmentation, object counting, image denoising, and classification. We prove that our augmentation method increases model performance when only a few training samples are available. In our experiment, we use the DeepLabV3 model on semantic segmentation tasks with Arabidopsis and Nicotiana tabacum image dataset. The obtained result shows a 9% relative increase in model performance compared to the basic image augmentation techniques.