 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeglected Hessian component explains mysteries in Sharpness regularization
Jan 24, 2024Recent work has shown that methods like SAM which either explicitly or implicitly penalize second order information can improve generalization in deep learning. Seemingly similar methods like weight noise and gradient penalties often fail to provide such benefits. We show that these differences can be explained by the structure of the Hessian of the loss. First, we show that a common decomposition of the Hessian can be quantitatively interpreted as separating the feature exploitation from feature exploration. The feature exploration, which can be described by the Nonlinear Modeling Error matrix (NME), is commonly neglected in the literature since it vanishes at interpolation. Our work shows that the NME is in fact important as it can explain why gradient penalties are sensitive to the choice of activation function. Using this insight we design interventions to improve performance. We also provide evidence that challenges the long held equivalence of weight noise and gradient penalties. This equivalence relies on the assumption that the NME can be ignored, which we find does not hold for modern networks since they involve significant feature learning. We find that regularizing feature exploitation but not feature exploration yields performance similar to gradient penalties.
Has the Machine Learning Review Process Become More Arbitrary as the Field Has Grown? The NeurIPS 2021 Consistency Experiment
Jun 05, 2023
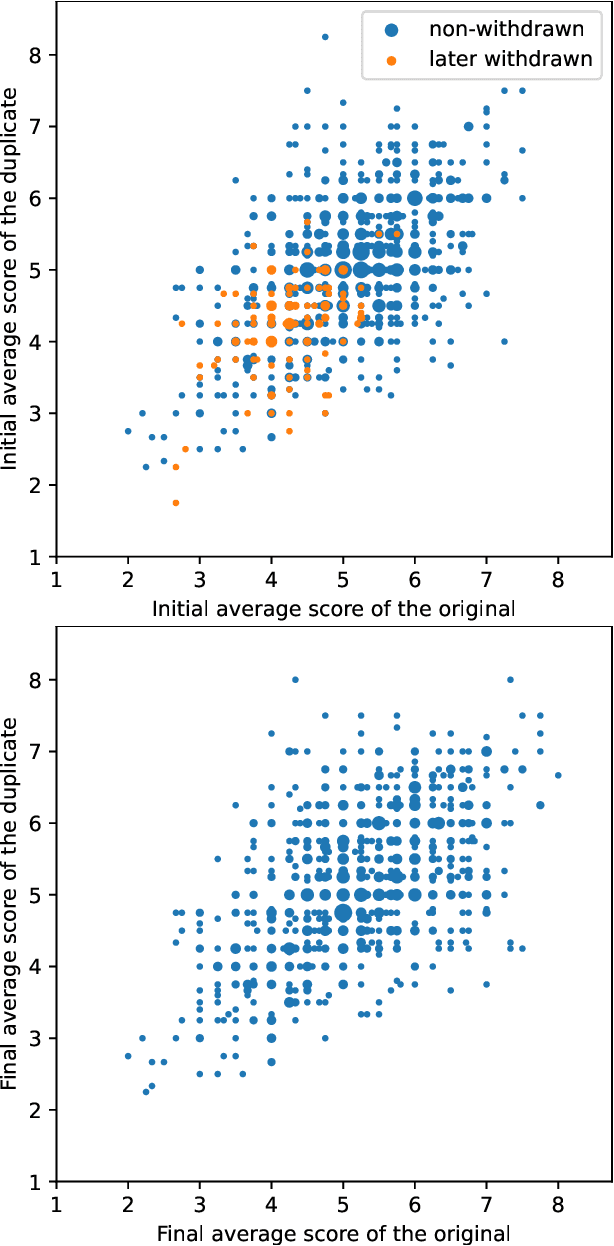
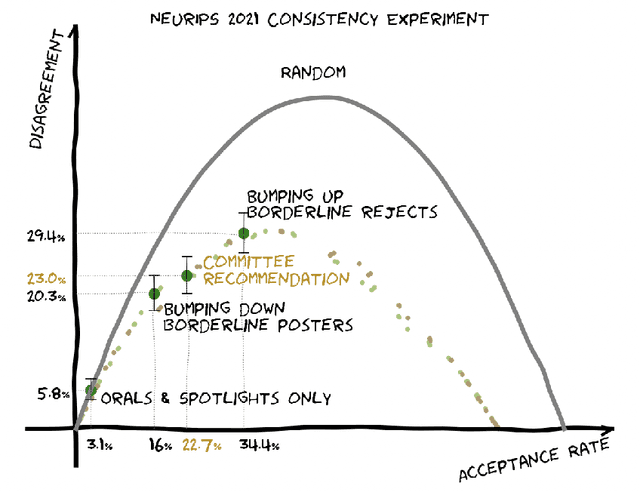
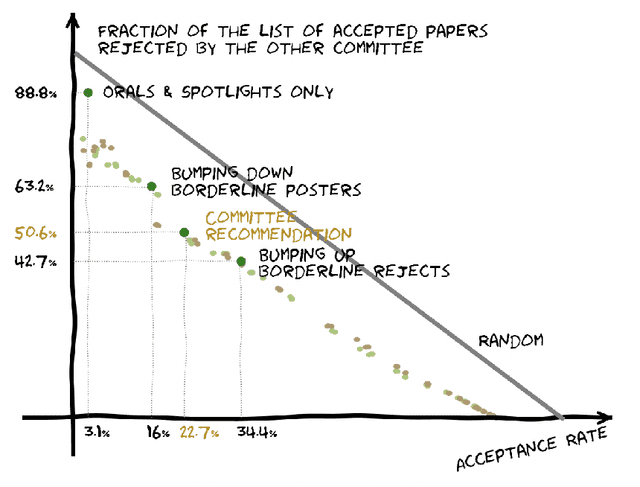
We present the NeurIPS 2021 consistency experiment, a larger-scale variant of the 2014 NeurIPS experiment in which 10% of conference submissions were reviewed by two independent committees to quantify the randomness in the review process. We observe that the two committees disagree on their accept/reject recommendations for 23% of the papers and that, consistent with the results from 2014, approximately half of the list of accepted papers would change if the review process were randomly rerun. Our analysis suggests that making the conference more selective would increase the arbitrariness of the process. Taken together with previous research, our results highlight the inherent difficulty of objectively measuring the quality of research, and suggest that authors should not be excessively discouraged by rejected work.
SAM operates far from home: eigenvalue regularization as a dynamical phenomenon
Feb 17, 2023
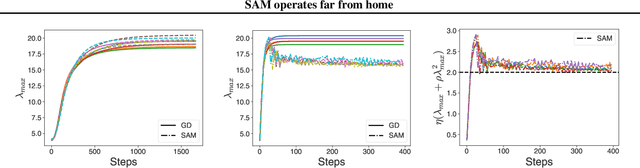
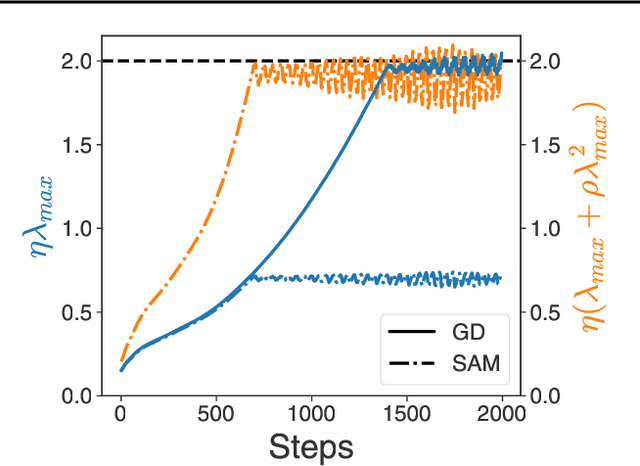

The Sharpness Aware Minimization (SAM) optimization algorithm has been shown to control large eigenvalues of the loss Hessian and provide generalization benefits in a variety of settings. The original motivation for SAM was a modified loss function which penalized sharp minima; subsequent analyses have also focused on the behavior near minima. However, our work reveals that SAM provides a strong regularization of the eigenvalues throughout the learning trajectory. We show that in a simplified setting, SAM dynamically induces a stabilization related to the edge of stability (EOS) phenomenon observed in large learning rate gradient descent. Our theory predicts the largest eigenvalue as a function of the learning rate and SAM radius parameters. Finally, we show that practical models can also exhibit this EOS stabilization, and that understanding SAM must account for these dynamics far away from any minima.
How do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
Nov 22, 2022



How do author perceptions match up to the outcomes of the peer-review process and perceptions of others? In a top-tier computer science conference (NeurIPS 2021) with more than 23,000 submitting authors and 9,000 submitted papers, we survey the authors on three questions: (i) their predicted probability of acceptance for each of their papers, (ii) their perceived ranking of their own papers based on scientific contribution, and (iii) the change in their perception about their own papers after seeing the reviews. The salient results are: (1) Authors have roughly a three-fold overestimate of the acceptance probability of their papers: The median prediction is 70% for an approximately 25% acceptance rate. (2) Female authors exhibit a marginally higher (statistically significant) miscalibration than male authors; predictions of authors invited to serve as meta-reviewers or reviewers are similarly calibrated, but better than authors who were not invited to review. (3) Authors' relative ranking of scientific contribution of two submissions they made generally agree (93%) with their predicted acceptance probabilities, but there is a notable 7% responses where authors think their better paper will face a worse outcome. (4) The author-provided rankings disagreed with the peer-review decisions about a third of the time; when co-authors ranked their jointly authored papers, co-authors disagreed at a similar rate -- about a third of the time. (5) At least 30% of respondents of both accepted and rejected papers said that their perception of their own paper improved after the review process. The stakeholders in peer review should take these findings into account in setting their expectations from peer review.
Simple and Effective Noisy Channel Modeling for Neural Machine Translation
Aug 15, 2019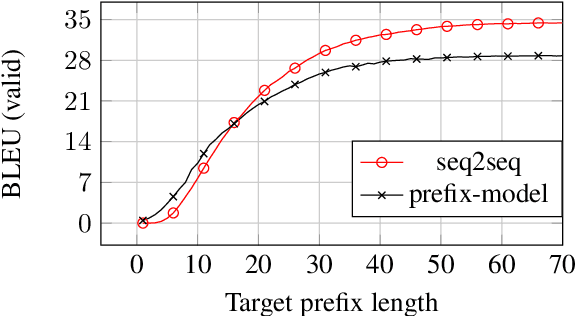
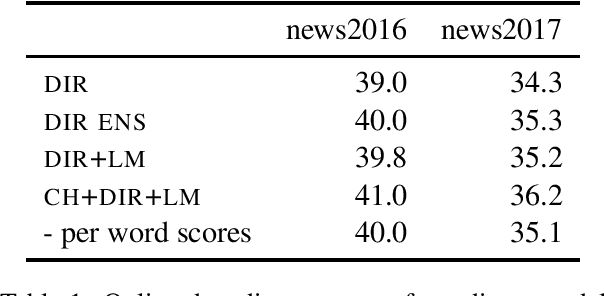
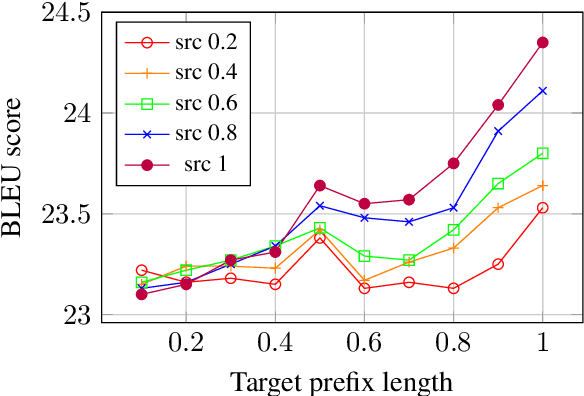
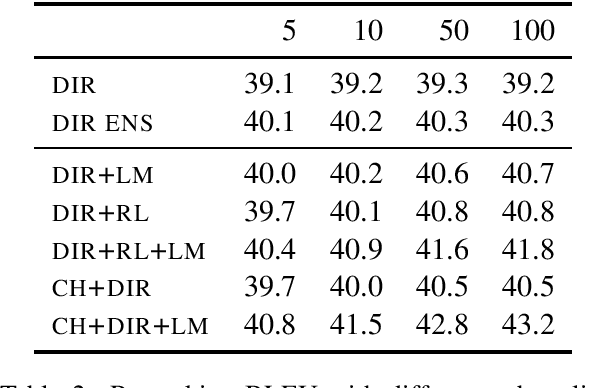
Previous work on neural noisy channel modeling relied on latent variable models that incrementally process the source and target sentence. This makes decoding decisions based on partial source prefixes even though the full source is available. We pursue an alternative approach based on standard sequence to sequence models which utilize the entire source. These models perform remarkably well as channel models, even though they have neither been trained on, nor designed to factor over incomplete target sentences. Experiments with neural language models trained on billions of words show that noisy channel models can outperform a direct model by up to 3.2 BLEU on WMT'17 German-English translation. We evaluate on four language-pairs and our channel models consistently outperform strong alternatives such right-to-left reranking models and ensembles of direct models.
Pay Less Attention with Lightweight and Dynamic Convolutions
Jan 29, 2019
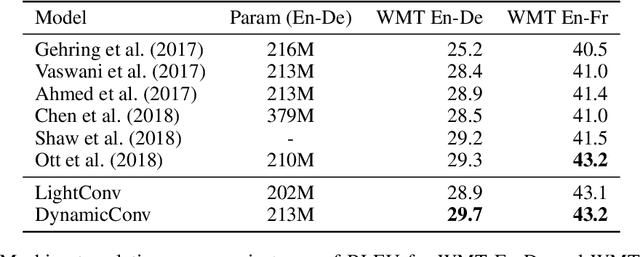

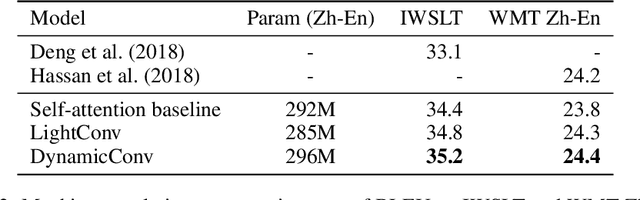
Self-attention is a useful mechanism to build generative models for language and images. It determines the importance of context elements by comparing each element to the current time step. In this paper, we show that a very lightweight convolution can perform competitively to the best reported self-attention results. Next, we introduce dynamic convolutions which are simpler and more efficient than self-attention. We predict separate convolution kernels based solely on the current time-step in order to determine the importance of context elements. The number of operations required by this approach scales linearly in the input length, whereas self-attention is quadratic. Experiments on large-scale machine translation, language modeling and abstractive summarization show that dynamic convolutions improve over strong self-attention models. On the WMT'14 English-German test set dynamic convolutions achieve a new state of the art of 29.7 BLEU.
Fixup Initialization: Residual Learning Without Normalization
Jan 27, 2019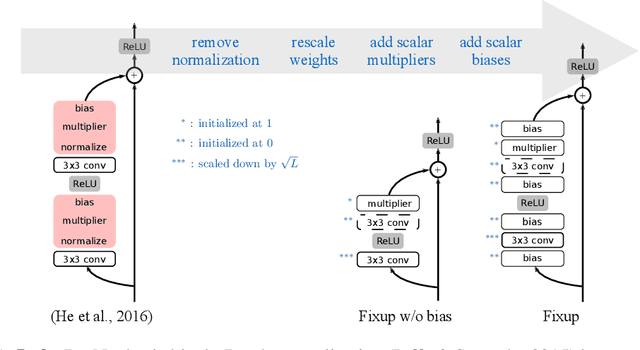

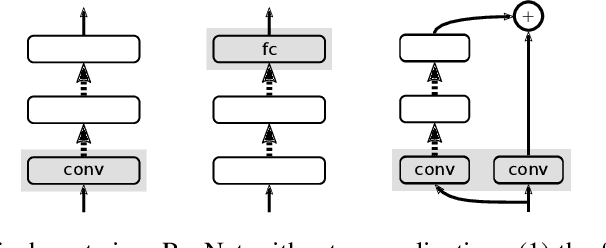
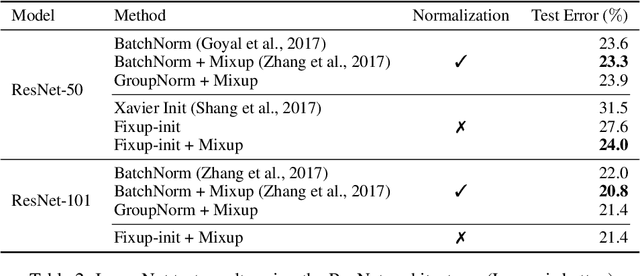
Normalization layers are a staple in state-of-the-art deep neural network architectures. They are widely believed to stabilize training, enable higher learning rate, accelerate convergence and improve generalization, though the reason for their effectiveness is still an active research topic. In this work, we challenge the commonly-held beliefs by showing that none of the perceived benefits is unique to normalization. Specifically, we propose fixed-update initialization (Fixup), an initialization motivated by solving the exploding and vanishing gradient problem at the beginning of training via properly rescaling a standard initialization. We find training residual networks with Fixup to be as stable as training with normalization -- even for networks with 10,000 layers. Furthermore, with proper regularization, Fixup enables residual networks without normalization to achieve state-of-the-art performance in image classification and machine translation.
mixup: Beyond Empirical Risk Minimization
Apr 27, 2018
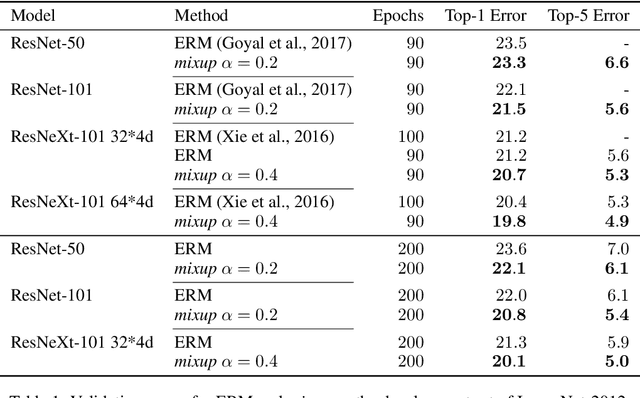
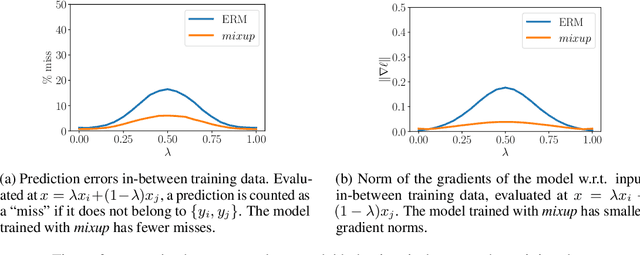
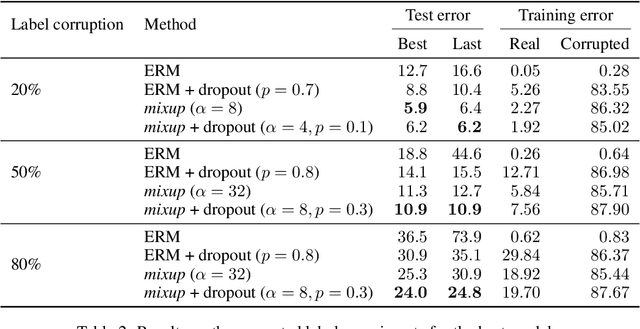
Large deep neural networks are powerful, but exhibit undesirable behaviors such as memorization and sensitivity to adversarial examples. In this work, we propose mixup, a simple learning principle to alleviate these issues. In essence, mixup trains a neural network on convex combinations of pairs of examples and their labels. By doing so, mixup regularizes the neural network to favor simple linear behavior in-between training examples. Our experiments on the ImageNet-2012, CIFAR-10, CIFAR-100, Google commands and UCI datasets show that mixup improves the generalization of state-of-the-art neural network architectures. We also find that mixup reduces the memorization of corrupt labels, increases the robustness to adversarial examples, and stabilizes the training of generative adversarial networks.
Language Modeling with Gated Convolutional Networks
Sep 08, 2017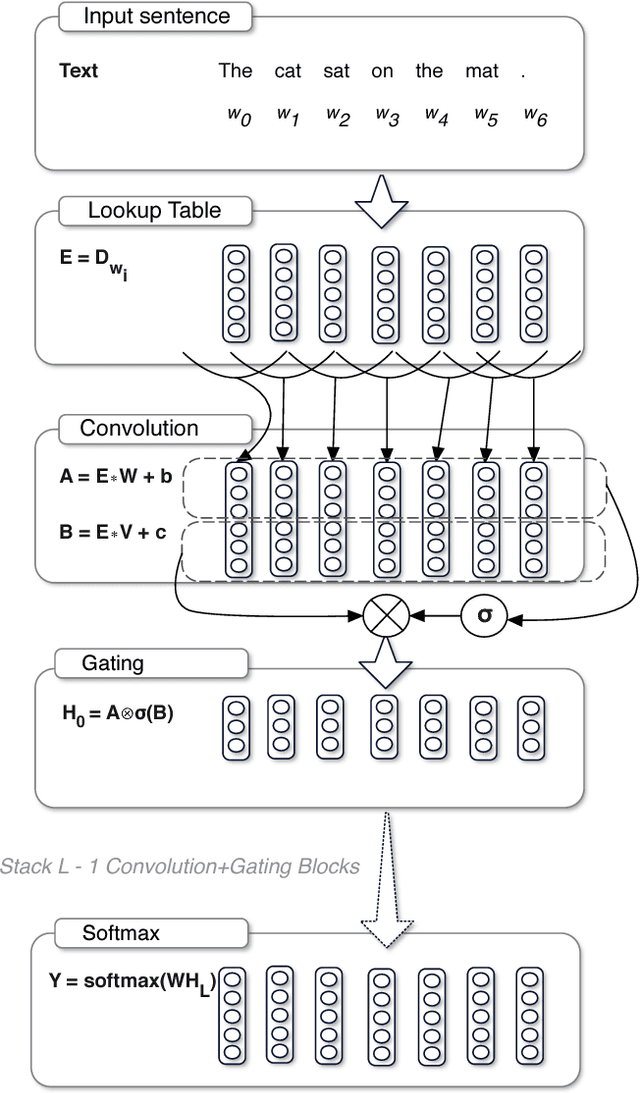
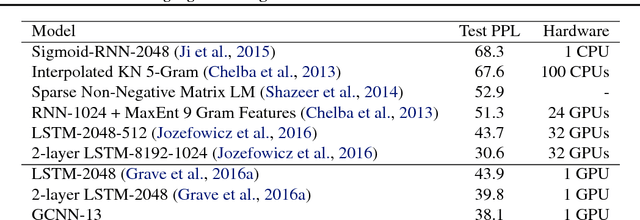

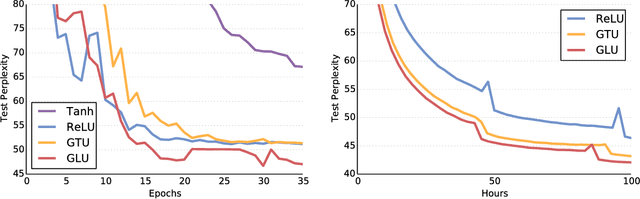
The pre-dominant approach to language modeling to date is based on recurrent neural networks. Their success on this task is often linked to their ability to capture unbounded context. In this paper we develop a finite context approach through stacked convolutions, which can be more efficient since they allow parallelization over sequential tokens. We propose a novel simplified gating mechanism that outperforms Oord et al (2016) and investigate the impact of key architectural decisions. The proposed approach achieves state-of-the-art on the WikiText-103 benchmark, even though it features long-term dependencies, as well as competitive results on the Google Billion Words benchmark. Our model reduces the latency to score a sentence by an order of magnitude compared to a recurrent baseline. To our knowledge, this is the first time a non-recurrent approach is competitive with strong recurrent models on these large scale language tasks.
Convolutional Sequence to Sequence Learning
Jul 25, 2017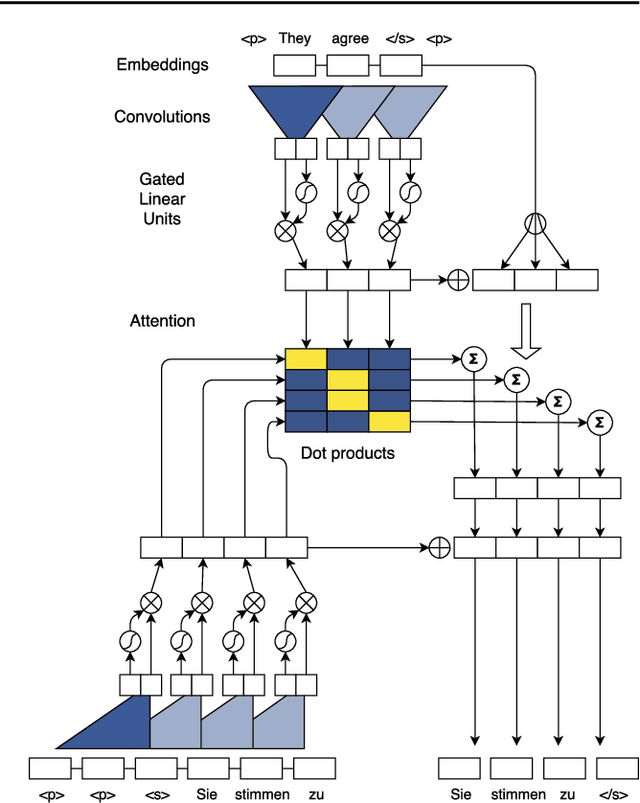
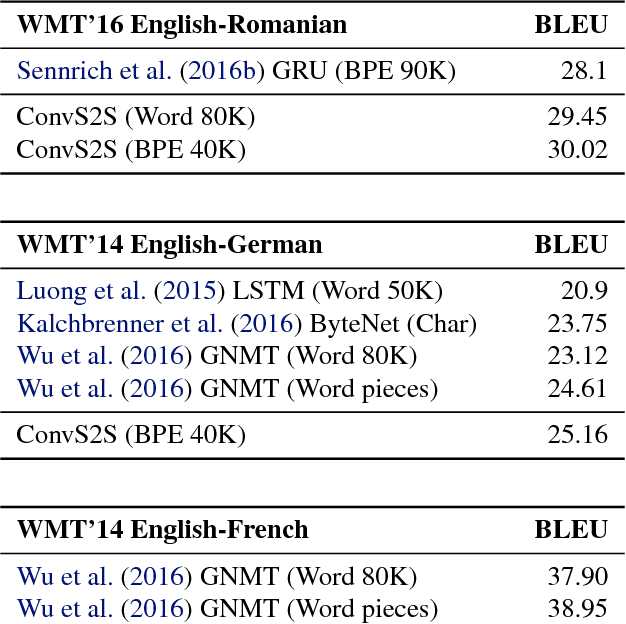
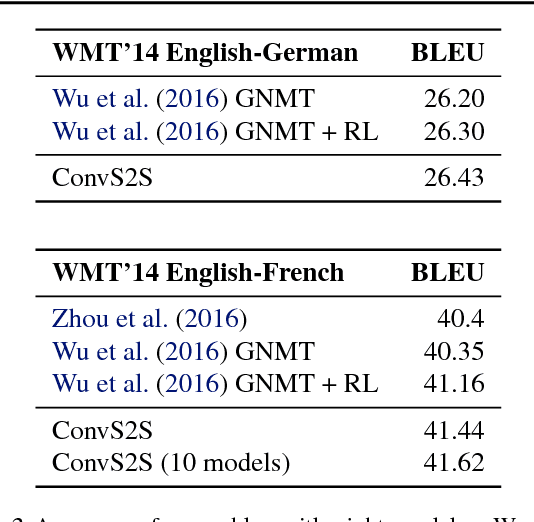
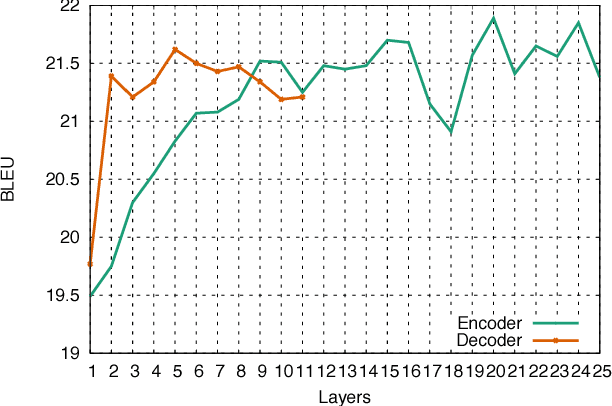
The prevalent approach to sequence to sequence learning maps an input sequence to a variable length output sequence via recurrent neural networks. We introduce an architecture based entirely on convolutional neural networks. Compared to recurrent models, computations over all elements can be fully parallelized during training and optimization is easier since the number of non-linearities is fixed and independent of the input length. Our use of gated linear units eases gradient propagation and we equip each decoder layer with a separate attention module. We outperform the accuracy of the deep LSTM setup of Wu et al. (2016) on both WMT'14 English-German and WMT'14 English-French translation at an order of magnitude faster speed, both on GPU and CPU.