 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReality Check: A New Evaluation Ecosystem Is Necessary to Understand AI's Real World Effects
May 24, 2025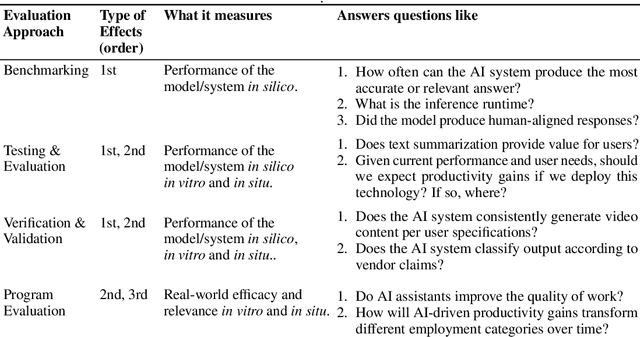
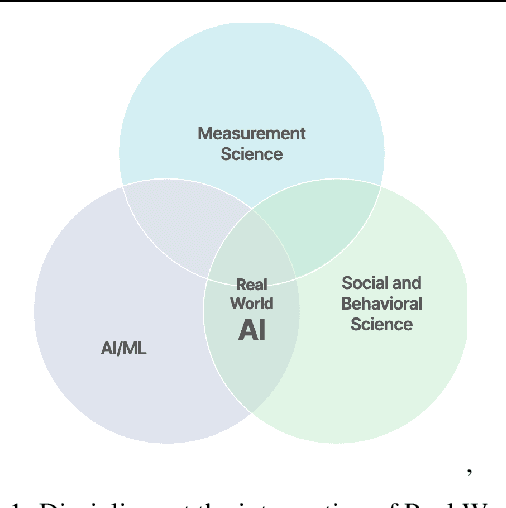

Conventional AI evaluation approaches concentrated within the AI stack exhibit systemic limitations for exploring, navigating and resolving the human and societal factors that play out in real world deployment such as in education, finance, healthcare, and employment sectors. AI capability evaluations can capture detail about first-order effects, such as whether immediate system outputs are accurate, or contain toxic, biased or stereotypical content, but AI's second-order effects, i.e. any long-term outcomes and consequences that may result from AI use in the real world, have become a significant area of interest as the technology becomes embedded in our daily lives. These secondary effects can include shifts in user behavior, societal, cultural and economic ramifications, workforce transformations, and long-term downstream impacts that may result from a broad and growing set of risks. This position paper argues that measuring the indirect and secondary effects of AI will require expansion beyond static, single-turn approaches conducted in silico to include testing paradigms that can capture what actually materializes when people use AI technology in context. Specifically, we describe the need for data and methods that can facilitate contextual awareness and enable downstream interpretation and decision making about AI's secondary effects, and recommend requirements for a new ecosystem.
Bound by the Bounty: Collaboratively Shaping Evaluation Processes for Queer AI Harms
Jul 25, 2023

Bias evaluation benchmarks and dataset and model documentation have emerged as central processes for assessing the biases and harms of artificial intelligence (AI) systems. However, these auditing processes have been criticized for their failure to integrate the knowledge of marginalized communities and consider the power dynamics between auditors and the communities. Consequently, modes of bias evaluation have been proposed that engage impacted communities in identifying and assessing the harms of AI systems (e.g., bias bounties). Even so, asking what marginalized communities want from such auditing processes has been neglected. In this paper, we ask queer communities for their positions on, and desires from, auditing processes. To this end, we organized a participatory workshop to critique and redesign bias bounties from queer perspectives. We found that when given space, the scope of feedback from workshop participants goes far beyond what bias bounties afford, with participants questioning the ownership, incentives, and efficacy of bounties. We conclude by advocating for community ownership of bounties and complementing bounties with participatory processes (e.g., co-creation).
* To appear at AIES 2023
A Keyword Based Approach to Understanding the Overpenalization of Marginalized Groups by English Marginal Abuse Models on Twitter
Oct 07, 2022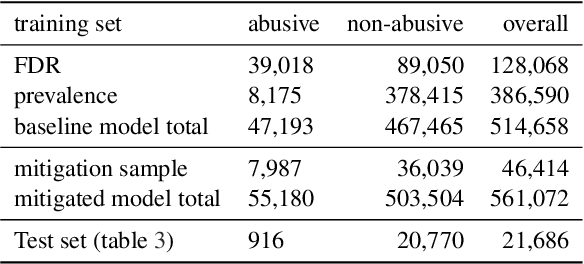
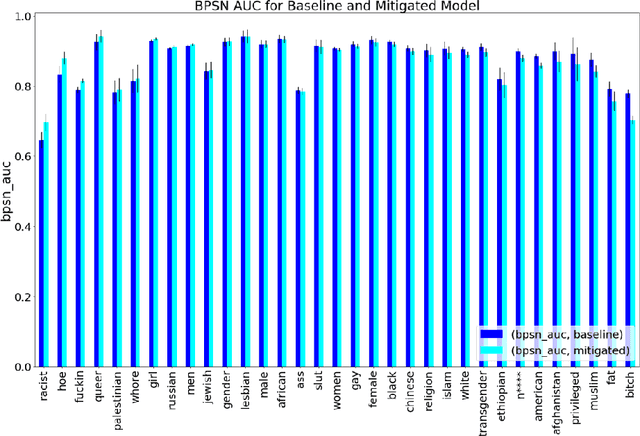
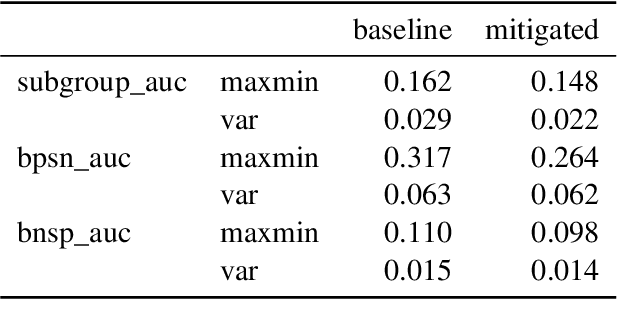
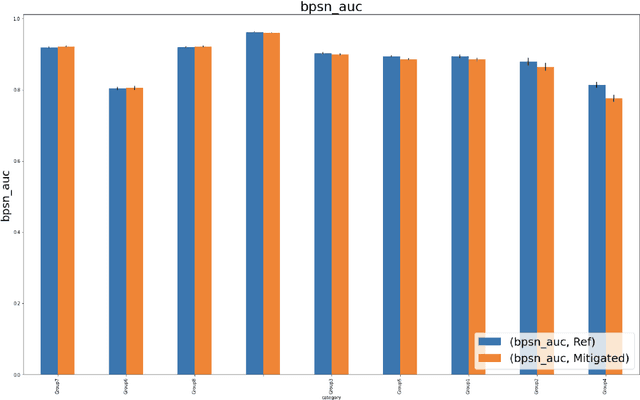
Harmful content detection models tend to have higher false positive rates for content from marginalized groups. In the context of marginal abuse modeling on Twitter, such disproportionate penalization poses the risk of reduced visibility, where marginalized communities lose the opportunity to voice their opinion on the platform. Current approaches to algorithmic harm mitigation, and bias detection for NLP models are often very ad hoc and subject to human bias. We make two main contributions in this paper. First, we design a novel methodology, which provides a principled approach to detecting and measuring the severity of potential harms associated with a text-based model. Second, we apply our methodology to audit Twitter's English marginal abuse model, which is used for removing amplification eligibility of marginally abusive content. Without utilizing demographic labels or dialect classifiers, we are still able to detect and measure the severity of issues related to the over-penalization of the speech of marginalized communities, such as the use of reclaimed speech, counterspeech, and identity related terms. In order to mitigate the associated harms, we experiment with adding additional true negative examples and find that doing so provides improvements to our fairness metrics without large degradations in model performance.
Random Isn't Always Fair: Candidate Set Imbalance and Exposure Inequality in Recommender Systems
Sep 12, 2022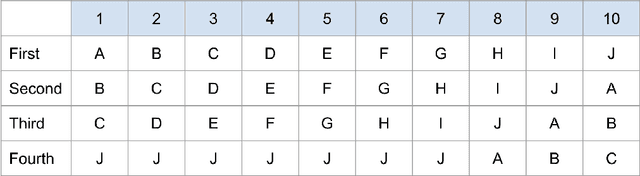

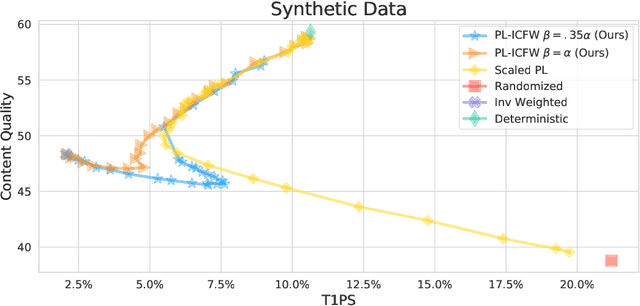
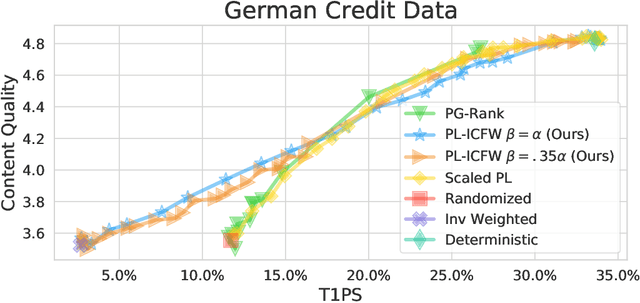
Traditionally, recommender systems operate by returning a user a set of items, ranked in order of estimated relevance to that user. In recent years, methods relying on stochastic ordering have been developed to create "fairer" rankings that reduce inequality in who or what is shown to users. Complete randomization -- ordering candidate items randomly, independent of estimated relevance -- is largely considered a baseline procedure that results in the most equal distribution of exposure. In industry settings, recommender systems often operate via a two-step process in which candidate items are first produced using computationally inexpensive methods and then a full ranking model is applied only to those candidates. In this paper, we consider the effects of inequality at the first step and show that, paradoxically, complete randomization at the second step can result in a higher degree of inequality relative to deterministic ordering of items by estimated relevance scores. In light of this observation, we then propose a simple post-processing algorithm in pursuit of reducing exposure inequality that works both when candidate sets have a high level of imbalance and when they do not. The efficacy of our method is illustrated on both simulated data and a common benchmark data set used in studying fairness in recommender systems.
Image Cropping on Twitter: Fairness Metrics, their Limitations, and the Importance of Representation, Design, and Agency
May 18, 2021
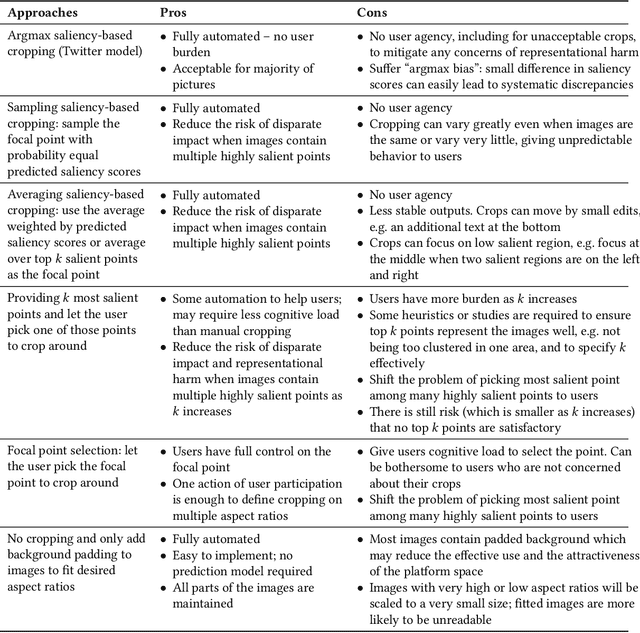
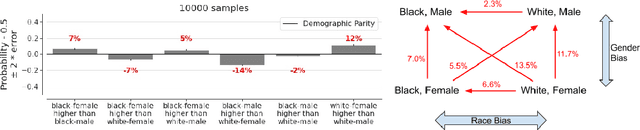
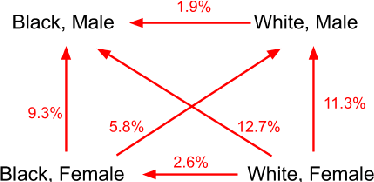
Twitter uses machine learning to crop images, where crops are centered around the part predicted to be the most salient. In fall 2020, Twitter users raised concerns that the automated image cropping system on Twitter favored light-skinned over dark-skinned individuals, as well as concerns that the system favored cropping woman's bodies instead of their heads. In order to address these concerns, we conduct an extensive analysis using formalized group fairness metrics. We find systematic disparities in cropping and identify contributing factors, including the fact that the cropping based on the single most salient point can amplify the disparities. However, we demonstrate that formalized fairness metrics and quantitative analysis on their own are insufficient for capturing the risk of representational harm in automatic cropping. We suggest the removal of saliency-based cropping in favor of a solution that better preserves user agency. For developing a new solution that sufficiently address concerns related to representational harm, our critique motivates a combination of quantitative and qualitative methods that include human-centered design.
Language Models not just for Pre-training: Fast Online Neural Noisy Channel Modeling
Nov 13, 2020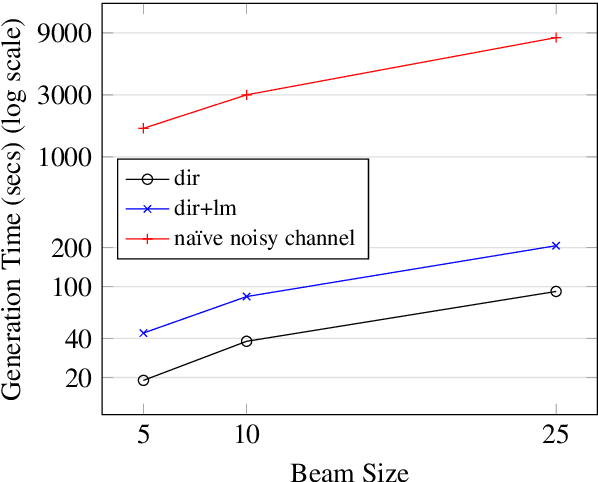
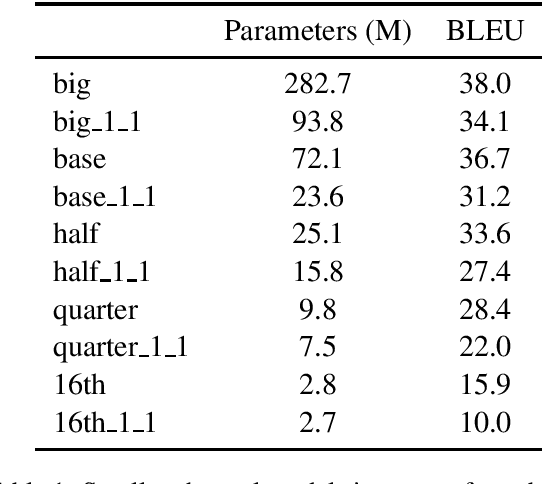
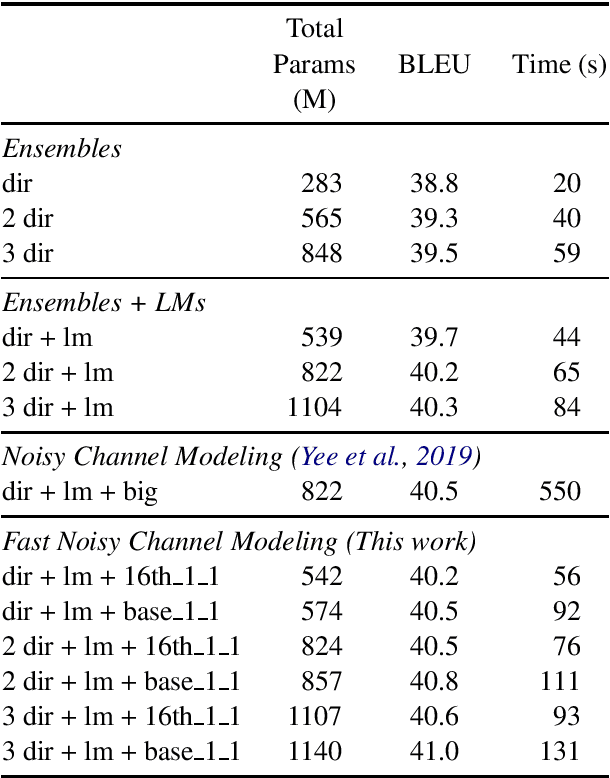
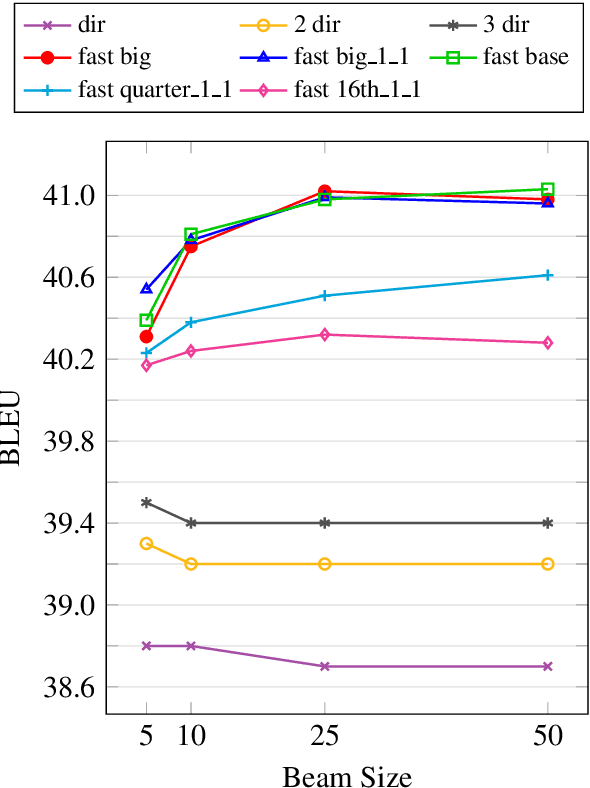
Pre-training models on vast quantities of unlabeled data has emerged as an effective approach to improving accuracy on many NLP tasks. On the other hand, traditional machine translation has a long history of leveraging unlabeled data through noisy channel modeling. The same idea has recently been shown to achieve strong improvements for neural machine translation. Unfortunately, na\"{i}ve noisy channel modeling with modern sequence to sequence models is up to an order of magnitude slower than alternatives. We address this issue by introducing efficient approximations to make inference with the noisy channel approach as fast as strong ensembles while increasing accuracy. We also show that the noisy channel approach can outperform strong pre-training results by achieving a new state of the art on WMT Romanian-English translation.
Simple and Effective Noisy Channel Modeling for Neural Machine Translation
Aug 15, 2019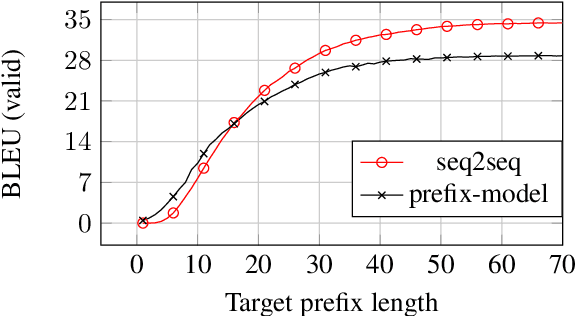
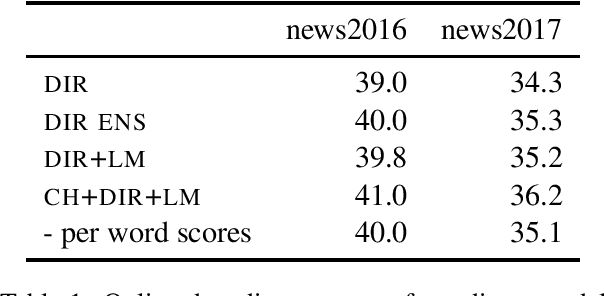
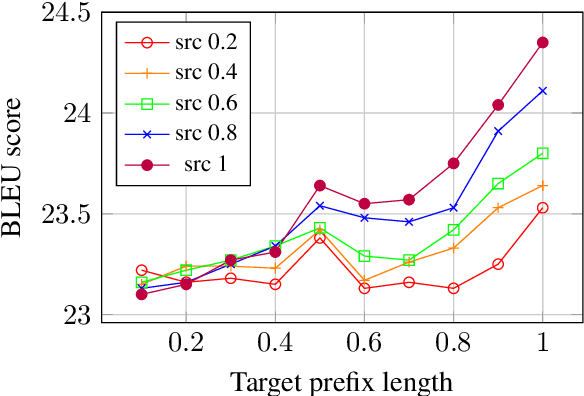
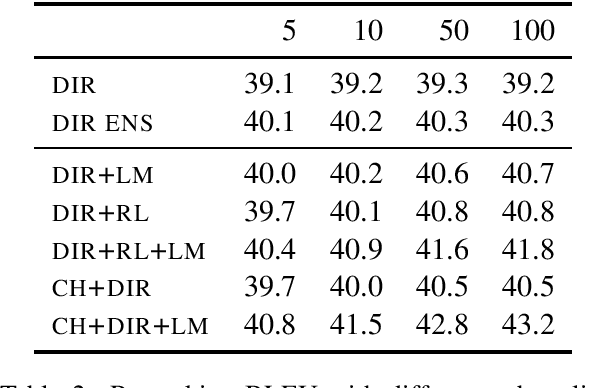
Previous work on neural noisy channel modeling relied on latent variable models that incrementally process the source and target sentence. This makes decoding decisions based on partial source prefixes even though the full source is available. We pursue an alternative approach based on standard sequence to sequence models which utilize the entire source. These models perform remarkably well as channel models, even though they have neither been trained on, nor designed to factor over incomplete target sentences. Experiments with neural language models trained on billions of words show that noisy channel models can outperform a direct model by up to 3.2 BLEU on WMT'17 German-English translation. We evaluate on four language-pairs and our channel models consistently outperform strong alternatives such right-to-left reranking models and ensembles of direct models.
Facebook FAIR's WMT19 News Translation Task Submission
Jul 15, 2019
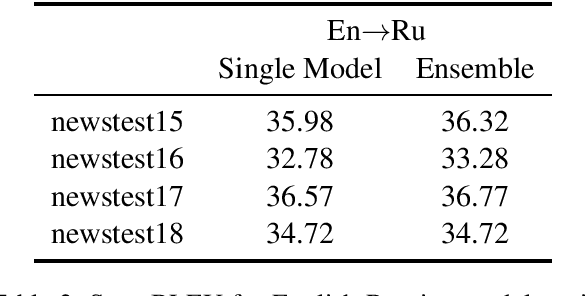
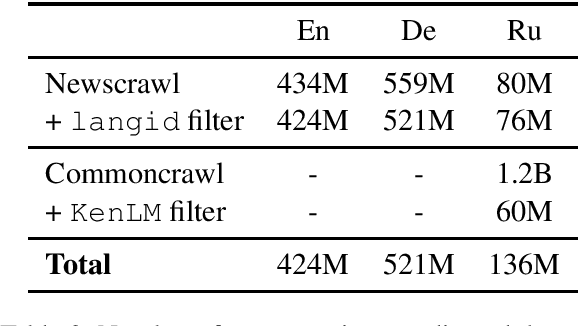
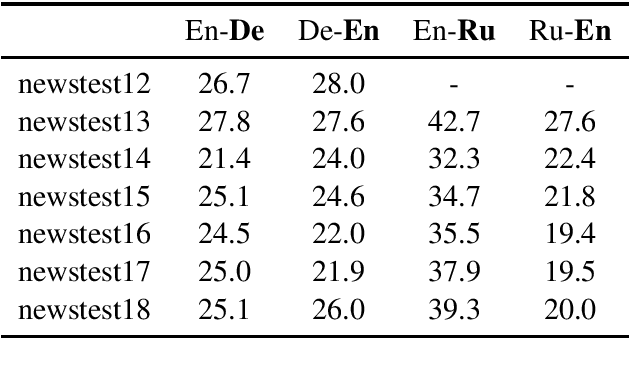
This paper describes Facebook FAIR's submission to the WMT19 shared news translation task. We participate in two language pairs and four language directions, English <-> German and English <-> Russian. Following our submission from last year, our baseline systems are large BPE-based transformer models trained with the Fairseq sequence modeling toolkit which rely on sampled back-translations. This year we experiment with different bitext data filtering schemes, as well as with adding filtered back-translated data. We also ensemble and fine-tune our models on domain-specific data, then decode using noisy channel model reranking. Our submissions are ranked first in all four directions of the human evaluation campaign. On En->De, our system significantly outperforms other systems as well as human translations. This system improves upon our WMT'18 submission by 4.5 BLEU points.