 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Isn't Always Fair: Candidate Set Imbalance and Exposure Inequality in Recommender Systems
Sep 12, 2022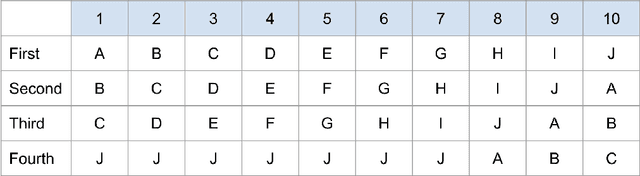

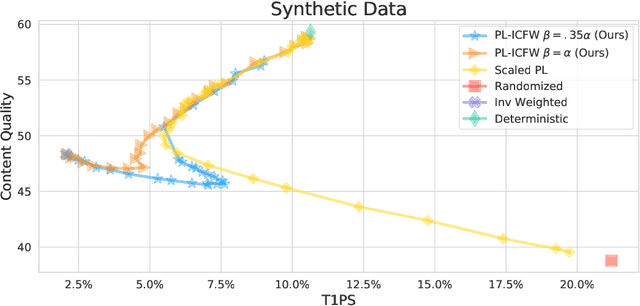
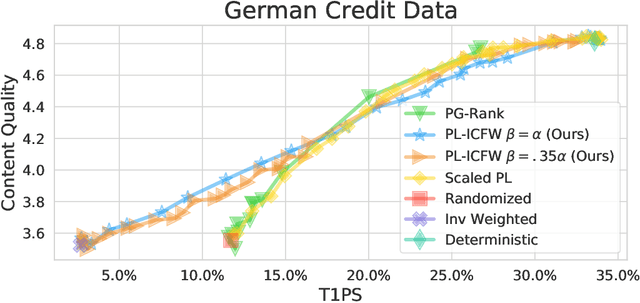
Traditionally, recommender systems operate by returning a user a set of items, ranked in order of estimated relevance to that user. In recent years, methods relying on stochastic ordering have been developed to create "fairer" rankings that reduce inequality in who or what is shown to users. Complete randomization -- ordering candidate items randomly, independent of estimated relevance -- is largely considered a baseline procedure that results in the most equal distribution of exposure. In industry settings, recommender systems often operate via a two-step process in which candidate items are first produced using computationally inexpensive methods and then a full ranking model is applied only to those candidates. In this paper, we consider the effects of inequality at the first step and show that, paradoxically, complete randomization at the second step can result in a higher degree of inequality relative to deterministic ordering of items by estimated relevance scores. In light of this observation, we then propose a simple post-processing algorithm in pursuit of reducing exposure inequality that works both when candidate sets have a high level of imbalance and when they do not. The efficacy of our method is illustrated on both simulated data and a common benchmark data set used in studying fairness in recommender systems.
De-biasing "bias" measurement
May 11, 2022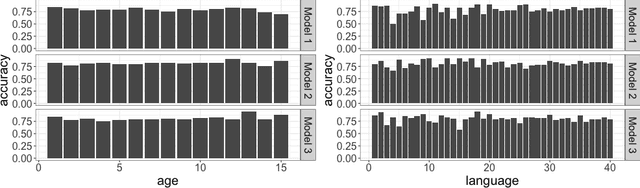

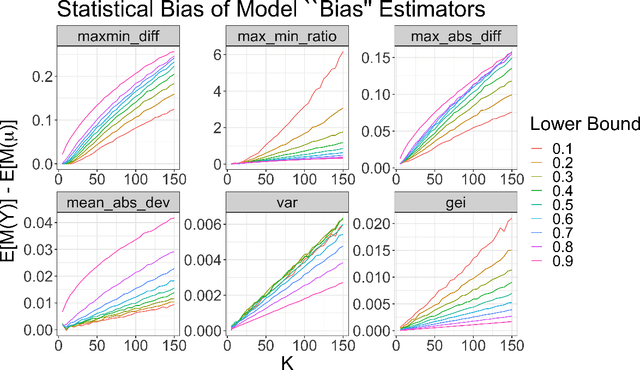
When a model's performance differs across socially or culturally relevant groups--like race, gender, or the intersections of many such groups--it is often called "biased." While much of the work in algorithmic fairness over the last several years has focused on developing various definitions of model fairness (the absence of group-wise model performance disparities) and eliminating such "bias," much less work has gone into rigorously measuring it. In practice, it important to have high quality, human digestible measures of model performance disparities and associated uncertainty quantification about them that can serve as inputs into multi-faceted decision-making processes. In this paper, we show both mathematically and through simulation that many of the metrics used to measure group-wise model performance disparities are themselves statistically biased estimators of the underlying quantities they purport to represent. We argue that this can cause misleading conclusions about the relative group-wise model performance disparities along different dimensions, especially in cases where some sensitive variables consist of categories with few members. We propose the "double-corrected" variance estimator, which provides unbiased estimates and uncertainty quantification of the variance of model performance across groups. It is conceptually simple and easily implementable without statistical software package or numerical optimization. We demonstrate the utility of this approach through simulation and show on a real dataset that while statistically biased estimators of model group-wise model performance disparities indicate statistically significant between-group model performance disparities, when accounting for statistical bias in the estimator, the estimated group-wise disparities in model performance are no longer statistically significant.
Measuring Disparate Outcomes of Content Recommendation Algorithms with Distributional Inequality Metrics
Feb 03, 2022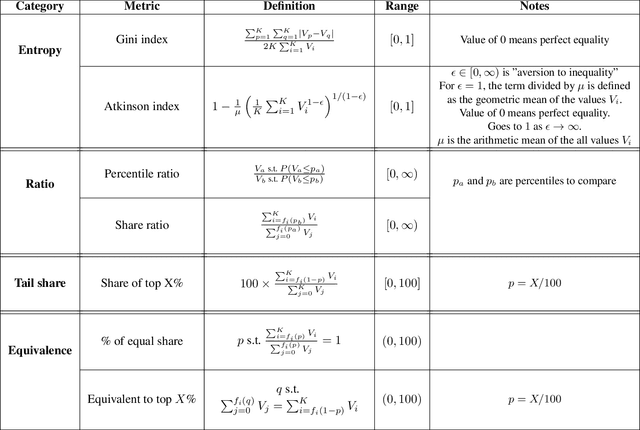
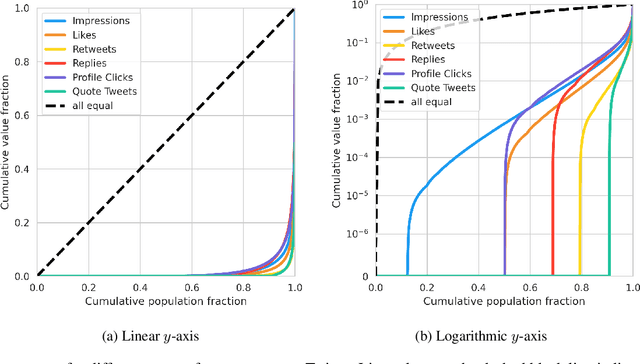
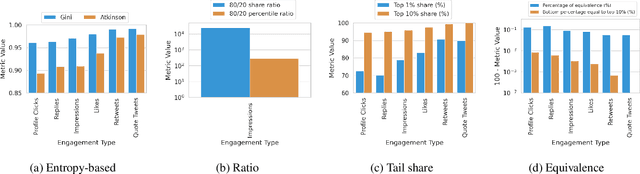
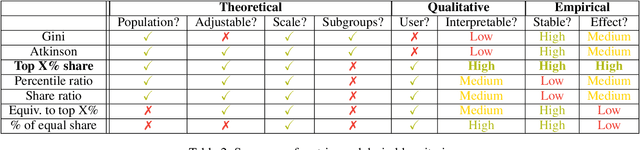
The harmful impacts of algorithmic decision systems have recently come into focus, with many examples of systems such as machine learning (ML) models amplifying existing societal biases. Most metrics attempting to quantify disparities resulting from ML algorithms focus on differences between groups, dividing users based on demographic identities and comparing model performance or overall outcomes between these groups. However, in industry settings, such information is often not available, and inferring these characteristics carries its own risks and biases. Moreover, typical metrics that focus on a single classifier's output ignore the complex network of systems that produce outcomes in real-world settings. In this paper, we evaluate a set of metrics originating from economics, distributional inequality metrics, and their ability to measure disparities in content exposure in a production recommendation system, the Twitter algorithmic timeline. We define desirable criteria for metrics to be used in an operational setting, specifically by ML practitioners. We characterize different types of engagement with content on Twitter using these metrics, and use these results to evaluate the metrics with respect to the desired criteria. We show that we can use these metrics to identify content suggestion algorithms that contribute more strongly to skewed outcomes between users. Overall, we conclude that these metrics can be useful tools for understanding disparate outcomes in online social networks.
Individually Fair Ranking
Mar 19, 2021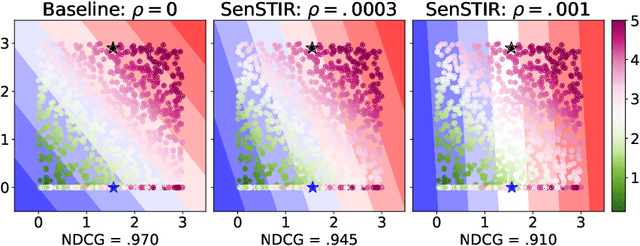



We develop an algorithm to train individually fair learning-to-rank (LTR) models. The proposed approach ensures items from minority groups appear alongside similar items from majority groups. This notion of fair ranking is based on the definition of individual fairness from supervised learning and is more nuanced than prior fair LTR approaches that simply ensure the ranking model provides underrepresented items with a basic level of exposure. The crux of our method is an optimal transport-based regularizer that enforces individual fairness and an efficient algorithm for optimizing the regularizer. We show that our approach leads to certifiably individually fair LTR models and demonstrate the efficacy of our method on ranking tasks subject to demographic biases.
Preference Modeling with Context-Dependent Salient Features
Feb 22, 2020

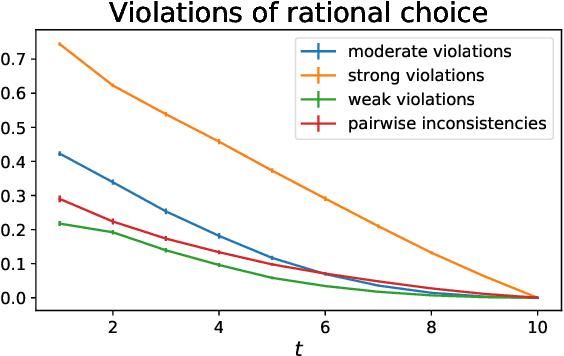

We consider the problem of estimating a ranking on a set of items from noisy pairwise comparisons given item features. We address the fact that pairwise comparison data often reflects irrational choice, e.g. intransitivity. Our key observation is that two items compared in isolation from other items may be compared based on only a salient subset of features. Formalizing this framework, we propose the "salient feature preference model" and prove a sample complexity result for learning the parameters of our model and the underlying ranking with maximum likelihood estimation. We also provide empirical results that support our theoretical bounds and illustrate how our model explains systematic intransitivity. Finally we demonstrate strong performance of maximum likelihood estimation of our model on both synthetic data and two real data sets: the UT Zappos50K data set and comparison data about the compactness of legislative districts in the US.
Learning fair predictors with Sensitive Subspace Robustness
Jun 28, 2019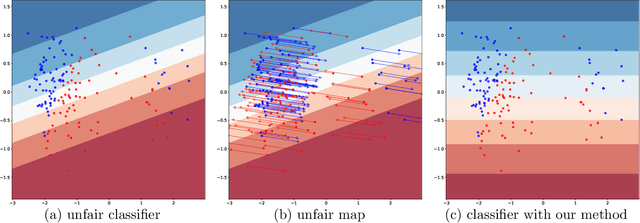


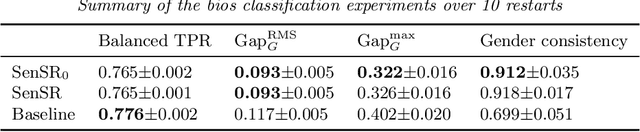
We consider an approach to training machine learning systems that are fair in the sense that their performance is invariant under certain perturbations to the features. For example, the performance of a resume screening system should be invariant under changes to the name of the applicant or switching the gender pronouns. We connect this intuitive notion of algorithmic fairness to individual fairness and study how to certify ML algorithms as algorithmically fair. We also demonstrate the effectiveness of our approach on three machine learning tasks that are susceptible to gender and racial biases.
Fair Pipelines
Jul 03, 2017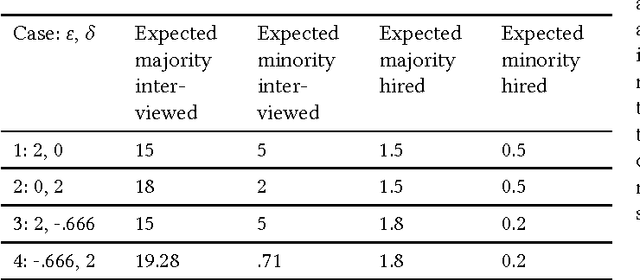
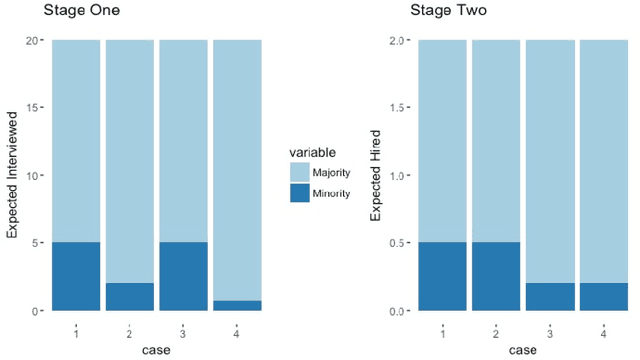
This work facilitates ensuring fairness of machine learning in the real world by decoupling fairness considerations in compound decisions. In particular, this work studies how fairness propagates through a compound decision-making processes, which we call a pipeline. Prior work in algorithmic fairness only focuses on fairness with respect to one decision. However, many decision-making processes require more than one decision. For instance, hiring is at least a two stage model: deciding who to interview from the applicant pool and then deciding who to hire from the interview pool. Perhaps surprisingly, we show that the composition of fair components may not guarantee a fair pipeline under a $(1+\varepsilon)$-equal opportunity definition of fair. However, we identify circumstances that do provide that guarantee. We also propose numerous directions for future work on more general compound machine learning decisions.